Spark筆記整理(二):RDD與spark核心概念名詞-創(chuàng)新互聯(lián)
[TOC]

Spark RDD
非常基本的說明,下面一張圖就能夠有基本的理解:
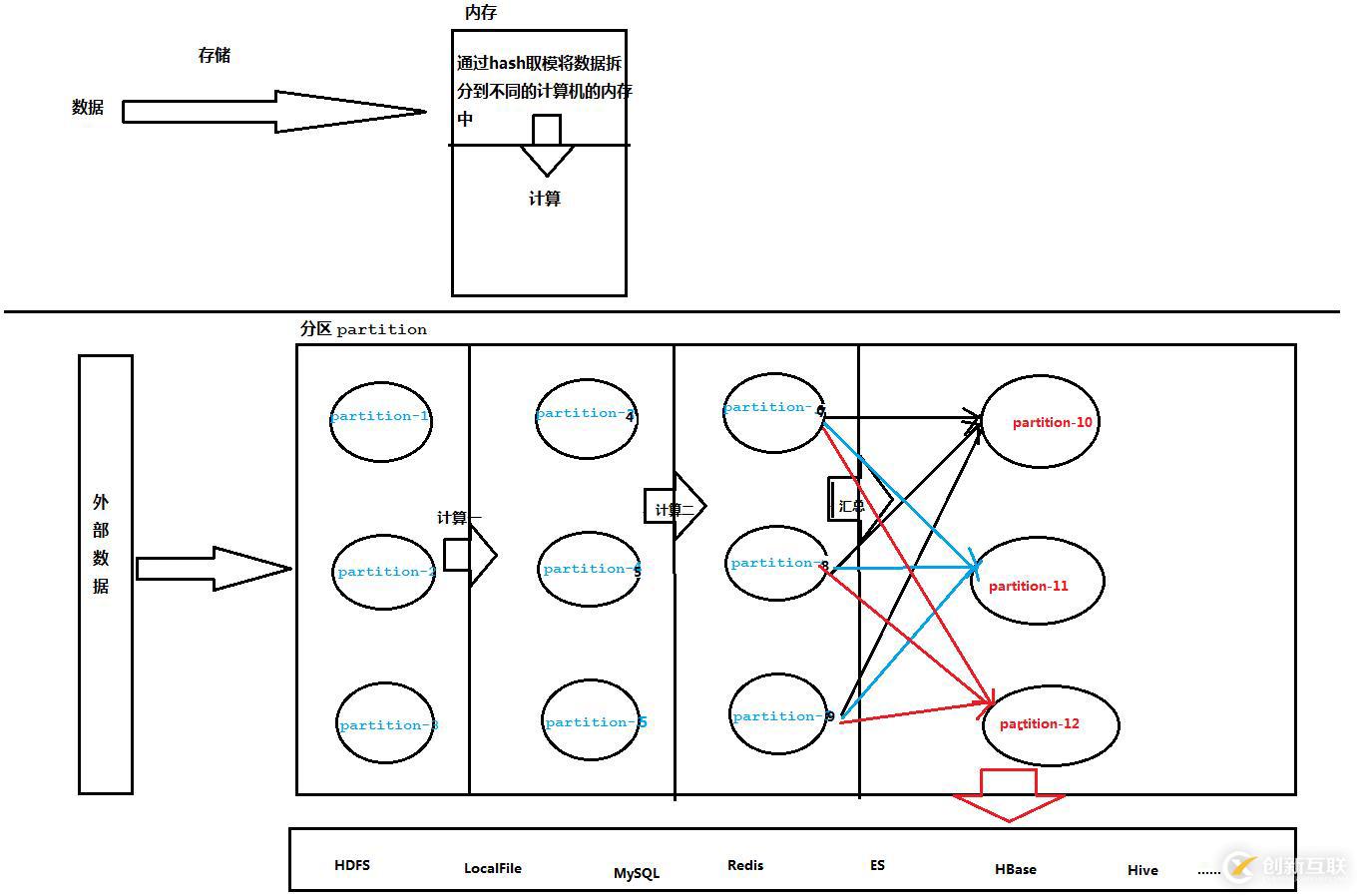
Spark RDD基本說明
1、Spark的核心概念是RDD (resilient distributed dataset,彈性分布式數(shù)據(jù)集),指的是一個只讀的,可分區(qū)的分布式數(shù)據(jù)集,這個數(shù)據(jù)集的全部或部分可以緩存在內存中,在多次計算間重用。
2、RDD在抽象上來說是一種元素集合,包含了數(shù)據(jù)。它是被分區(qū)的,分為多個分區(qū),每個分區(qū)分布在集群中的不同Worker節(jié)點上,從而讓RDD中的數(shù)據(jù)可以被并行操作。(分布式數(shù)據(jù)集)
3、RDD通常通過Hadoop上的文件,即HDFS文件或者Hive表,來進行創(chuàng)建;有時也可以通過RDD的本地創(chuàng)建轉換而來。
4、傳統(tǒng)的MapReduce雖然具有自動容錯、平衡負載和可拓展性的優(yōu)點,但是其大缺點是采用非循環(huán)式的數(shù)據(jù)流模型,使得在迭代計算式要進行大量的磁盤IO操作(每跑完一個Job,拿到其中間結果后,再跑下一個Job,聯(lián)想使用MR做數(shù)據(jù)清洗的案例)。RDD正是解決這一缺點的抽象方法。RDD最重要的特性就是,提供了容錯性,可以自動從節(jié)點失敗中恢復過來。即如果某個節(jié)點上的RDD partition,因為節(jié)點故障,導致數(shù)據(jù)丟了,那么RDD會自動通過自己的數(shù)據(jù)來源重新計算該partition。這一切對使用者是透明的。RDD的lineage特性(類似于族譜,像上面的圖,假如某個partition的數(shù)據(jù)丟失了,找到其父partition重新計算即可,我稱之為溯源)。
5、RDD的數(shù)據(jù)默認情況下存放在內存中的,但是在內存資源不足時,Spark會自動將RDD數(shù)據(jù)寫入磁盤。(彈性)
RDD在Spark中的地位和作用
(1)為什么會有Spark?因為傳統(tǒng)的并行計算模型無法有效的解決迭代計算(iterative)和交互式計算(interactive);而Spark的使命便是解決這兩個問題,這也是他存在的價值和理由。
(2)Spark如何解決迭代計算?其主要實現(xiàn)思想就是RDD,把所有計算的數(shù)據(jù)保存在分布式的內存中。迭代計算通常情況下都是對同一個數(shù)據(jù)集做反復的迭代計算,數(shù)據(jù)在內存中將大大提升IO操作。這也是Spark涉及的核心:內存計算。(一行搞定wc:sc.textFile("./hello").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println),這就是典型的迭代計算了)
(3)Spark如何實現(xiàn)交互式計算?因為Spark是用scala語言實現(xiàn)的,Spark和scala能夠緊密的集成,所以Spark可以完美的運用scala的解釋器,使得其中的scala可以向操作本地集合對象一樣輕松操作分布式數(shù)據(jù)集。
(4)Spark和RDD的關系?可以理解為:RDD是一種具有容錯性基于內存的集群計算抽象方法,Spark則是這個抽象方法的實現(xiàn)。
Spark常用核心模塊
1、核心模塊開發(fā):離線批處理 Spark Core
2、實時計算:底層也是基于RDD Spark Streaming
3、Spark SQL/Hive:交互式分析
4、Spark Graphx:圖計算
5、Spark Mlib: 數(shù)據(jù)挖掘和機器學習核心概念名詞
大多數(shù)應該都要實地寫過spark程序和提交任務到spark集群后才有更好的理解。
- ClusterManager:在Standalone模式中即為Master(主節(jié)點),控制整個集群,監(jiān)控Worker。在YARN模式中為資源管理器。
- Worker:從節(jié)點,負責控制計算節(jié)點,啟動Executor。在YARN模式中為NodeManager,負責計算節(jié)點的控制。
- Driver:運行Application的main()函數(shù)并創(chuàng)建SparkContext。
- Executor:執(zhí)行器,在worker node上執(zhí)行任務的組件、用于啟動線程池運行任務。每個Application擁有獨立的一組Executors。
- SparkContext:整個應用的上下文,控制應用的生命周期。
- RDD:Spark的基本計算單元,一組RDD可形成執(zhí)行的有向無環(huán)圖RDD Graph。
- DAG Scheduler:實現(xiàn)將Spark作業(yè)分解成一到多個Stage,每個Stage根據(jù)RDD的Partition個數(shù)決定Task的個數(shù),然后生成相應的Task set放到TaskScheduler中。
- TaskScheduler:將任務(Task)分發(fā)給Executor執(zhí)行。(所以Executor執(zhí)行的就是我們的代碼)
- Stage:一個Spark作業(yè)一般包含一到多個Stage。
- Task:一個Stage包含一到多個Task,通過多個Task實現(xiàn)并行運行的功能。
- Transformations:轉換(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是說從一個RDD轉換生成另一個RDD的操作不是馬上執(zhí)行,Spark在遇到Transformations操作時只會記錄需要這樣的操作,并不會去執(zhí)行,需要等到有Actions操作的時候才會真正啟動計算過程進行計算。(后面的wc例子就會有很好的說明)
- Actions:操作(Actions) (如:count, collect, save等),Actions操作會返回結果或把RDD數(shù)據(jù)寫到存儲系統(tǒng)中。Actions是觸發(fā)Spark啟動計算的動因。
- SparkEnv:線程級別的上下文,存儲運行時的重要組件的引用。SparkEnv內創(chuàng)建并包含如下一些重要組件的引用。
- MapOutPutTracker:負責Shuffle元信息的存儲。
- BroadcastManager:負責廣播變量的控制與元信息的存儲。
- BlockManager:負責存儲管理、創(chuàng)建和查找塊。
- MetricsSystem:監(jiān)控運行時性能指標信息。
- SparkConf:負責存儲配置信息。
另外有需要云服務器可以了解下創(chuàng)新互聯(lián)scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
名稱欄目:Spark筆記整理(二):RDD與spark核心概念名詞-創(chuàng)新互聯(lián)
網(wǎng)站鏈接:http://vcdvsql.cn/article26/jshjg.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供網(wǎng)頁設計公司、外貿建站、App開發(fā)、App設計、網(wǎng)站制作、定制開發(fā)
聲明:本網(wǎng)站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經(jīng)允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內容
- 你不懂得HTML與CSS的戀情發(fā)展史-創(chuàng)新互聯(lián)
- dedecms織夢arclist標簽的使用-創(chuàng)新互聯(lián)
- linux如何查看文件和目錄-創(chuàng)新互聯(lián)
- 利用mybatis-plus怎么實現(xiàn)一個代碼自動生成功能-創(chuàng)新互聯(lián)
- 原生js如何實現(xiàn)ajax請求和JSONP跨域請求-創(chuàng)新互聯(lián)
- 怎么用vbs將本地文件替換為在文件服務器上找到的新版本-創(chuàng)新互聯(lián)
- Matlab繪制累積分布函數(shù)(CDF)-創(chuàng)新互聯(lián)
- ChatGPT的應用ChatGPT對社會的利弊影響 2023-02-20
- 火爆的ChatGPT,來聊聊它的熱門話題 2023-02-20
- 怎樣利用chatGPT快速賺錢? 2023-05-05
- ChatGPT是什么?ChatGPT是聊天機器人嗎? 2023-05-05
- ChatGPT的發(fā)展歷程 2023-02-20
- 馬云回國,首談ChatGPT。又是新一個風口? 2023-05-28
- ChatGPT是什么 2023-02-20
- 爆紅的ChatGPT,誰會丟掉飯碗? 2023-02-20