從零開始入門K8s|可觀測性:監(jiān)控與日志-創(chuàng)新互聯(lián)
作者 | 莫源? 阿里巴巴技術(shù)專家

一、背景
監(jiān)控和日志是大型分布式系統(tǒng)的重要基礎(chǔ)設(shè)施,監(jiān)控可以幫助開發(fā)者查看系統(tǒng)的運(yùn)行狀態(tài),而日志可以協(xié)助問題的排查和診斷。
在 Kubernetes 中,監(jiān)控和日志屬于生態(tài)的一部分,它并不是核心組件,因此大部分的能力依賴上層的云廠商的適配。Kubernetes 定義了介入的接口標(biāo)準(zhǔn)和規(guī)范,任何符合接口標(biāo)準(zhǔn)的組件都可以快速集成。
二、監(jiān)控
監(jiān)控類型
先看一下監(jiān)控,從監(jiān)控類型上劃分,在 K8s 中可以分成四個不同的類型:
1.資源監(jiān)控
比較常見的像 CPU、內(nèi)存、網(wǎng)絡(luò)這種資源類的一個指標(biāo),通常這些指標(biāo)會以數(shù)值、百分比的單位進(jìn)行統(tǒng)計(jì),是最常見的一個監(jiān)控方式。這種監(jiān)控方式在常規(guī)的監(jiān)控里面,類似項(xiàng)目 zabbix telegraph,這些系統(tǒng)都是可以做到的。
2.性能監(jiān)控
性能監(jiān)控指的就是 APM 監(jiān)控,也就是說常見的一些應(yīng)用性能類的監(jiān)控指標(biāo)的檢查。通常是通過一些 Hook 的機(jī)制在虛擬機(jī)層、字節(jié)碼執(zhí)行層通過隱式調(diào)用,或者是在應(yīng)用層顯示注入,獲取更深層次的一個監(jiān)控指標(biāo),一般是用來應(yīng)用的調(diào)優(yōu)和診斷的。比較常見的類似像 jvm 或者 php 的 Zend?Engine,通過一些常見的 Hook 機(jī)制,拿到類似像 jvm 里面的 GC 的次數(shù),各種內(nèi)存代的一個分布以及網(wǎng)絡(luò)連接數(shù)的一些指標(biāo),通過這種方式來進(jìn)行應(yīng)用的性能診斷和調(diào)優(yōu)。
3.安全監(jiān)控
安全監(jiān)控主要是對安全進(jìn)行的一系列的監(jiān)控策略,類似像越權(quán)管理、安全漏洞掃描等等。
4.事件監(jiān)控
事件監(jiān)控是 K8s 中比較另類的一種監(jiān)控方式。之前的文章為大家介紹了在 K8s 中的一個設(shè)計(jì)理念,就是基于狀態(tài)機(jī)的一個狀態(tài)轉(zhuǎn)換。從正常的狀態(tài)轉(zhuǎn)換成另一個正常的狀態(tài)的時候,會發(fā)生一個 normal 的事件,而從一個正常狀態(tài)轉(zhuǎn)換成一個異常狀態(tài)的時候,會發(fā)生一個 warning 的事件。通常情況下,warning 的事件是我們比較關(guān)心的,而事件監(jiān)控就是可以把 normal 的事件或者是 warning 事件離線到一個數(shù)據(jù)中心,然后通過數(shù)據(jù)中心的分析以及報(bào)警,把相應(yīng)的一些異常通過像釘釘或者是短信、郵件的方式進(jìn)行暴露,彌補(bǔ)常規(guī)監(jiān)控的一些缺陷和弊端。
Kubernetes 的監(jiān)控演進(jìn)
在早期,也就是 1.10 以前的 K8s 版本。大家都會使用類似像 Heapster 這樣的組件來去進(jìn)行監(jiān)控的采集,Heapster 的設(shè)計(jì)原理其實(shí)也比較簡單。
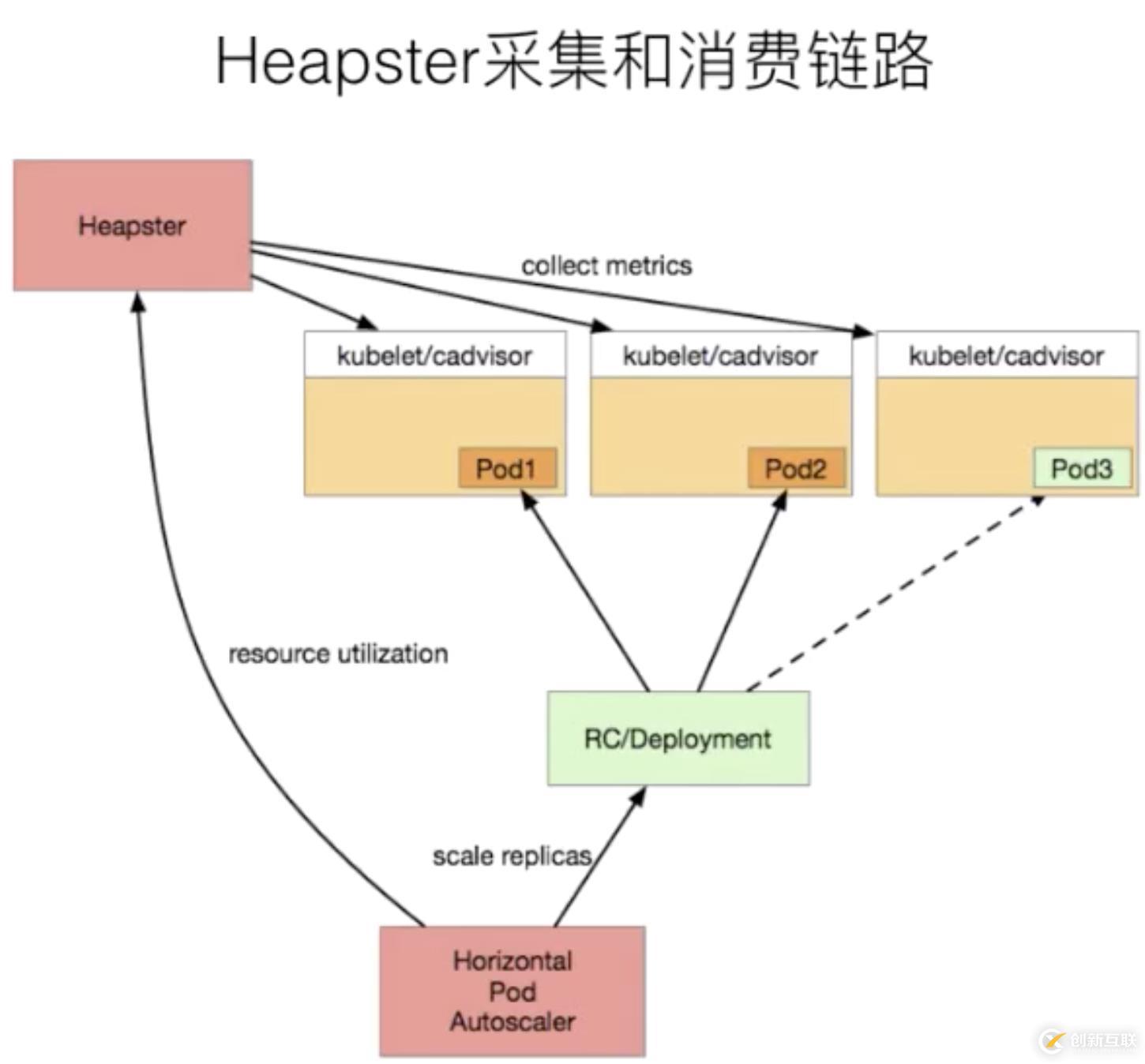
首先,我們在每一個 Kubernetes 上面有一個包裹好的 cadvisor,這個 cadvisor 是負(fù)責(zé)數(shù)據(jù)采集的組件。當(dāng) cadvisor 把數(shù)據(jù)采集完成,Kubernetes 會把 cadvisor 采集到的數(shù)據(jù)進(jìn)行包裹,暴露成相應(yīng)的 API。在早期的時候,實(shí)際上是有三種不同的 API:
- 第一種是 summary 接口;
- 第二種是 kubelet 接口;
- 第三種是 Prometheus 接口。
這三種接口,其實(shí)對應(yīng)的數(shù)據(jù)源都是 cadvisor,只是數(shù)據(jù)格式有所不同。而在 Heapster 里面,其實(shí)支持了 summary 接口和 kubelet 兩種數(shù)據(jù)采集接口,Heapster 會定期去每一個節(jié)點(diǎn)拉取數(shù)據(jù),在自己的內(nèi)存里面進(jìn)行聚合,然后再暴露相應(yīng)的 service,供上層的消費(fèi)者進(jìn)行使用。在 K8s 中比較常見的消費(fèi)者,類似像 dashboard,或者是 HPA-Controller,它通過調(diào)用 service 獲取相應(yīng)的監(jiān)控?cái)?shù)據(jù),來實(shí)現(xiàn)相應(yīng)的彈性伸縮,以及監(jiān)控?cái)?shù)據(jù)的一個展示。
這個是以前的一個數(shù)據(jù)消費(fèi)鏈路,這條消費(fèi)鏈路看上去很清晰,也沒有太多的一個問題,那為什么 Kubernetes 會將 Heapster 放棄掉而轉(zhuǎn)換到 metrics-service 呢?其實(shí)這個主要的一個動力來源是由于 Heapster 在做監(jiān)控?cái)?shù)據(jù)接口的標(biāo)準(zhǔn)化。為什么要做監(jiān)控?cái)?shù)據(jù)接口標(biāo)準(zhǔn)化呢?
- 第一點(diǎn)在于客戶的需求是千變?nèi)f化的,比如說今天用 Heapster 進(jìn)行了基礎(chǔ)數(shù)據(jù)的一個資源采集,那明天的時候,我想在應(yīng)用里面暴露在線人數(shù)的一個數(shù)據(jù)接口,放到自己的接口系統(tǒng)里進(jìn)行數(shù)據(jù)的一個展現(xiàn),以及類似像 HPA 的一個數(shù)據(jù)消費(fèi)。那這個場景在 Heapster 下能不能做呢?答案是不可以的,所以這就是 Heapster 自身擴(kuò)展性的弊端;
- 第二點(diǎn)是 Heapster 里面為了保證數(shù)據(jù)的離線能力,提供了很多的 sink,而這個 sink 包含了類似像 influxdb、sls、釘釘?shù)鹊纫幌盗?sink。這個 sink 主要做的是把數(shù)據(jù)采集下來,并且把這個數(shù)據(jù)離線走,然后很多客戶會用 influxdb 做這個數(shù)據(jù)離線,在 influxdb 上去接入類似像 grafana 監(jiān)控?cái)?shù)據(jù)的一個可視化的軟件,來實(shí)踐監(jiān)控?cái)?shù)據(jù)的可視化。
但是后來社區(qū)發(fā)現(xiàn),這些 sink 很多時候都是沒有人來維護(hù)的。這也導(dǎo)致整個 Heapster 的項(xiàng)目有很多的 bug,這個 bug 一直存留在社區(qū)里面,是沒有人修復(fù)的,這個也是會給社區(qū)的項(xiàng)目的活躍度包括項(xiàng)目的穩(wěn)定性帶來了很多的挑戰(zhàn)。
基于這兩點(diǎn)原因,K8s 把 Heapster 進(jìn)行了 break 掉,然后做了一個精簡版的監(jiān)控采集組件,叫做 metrics-server。
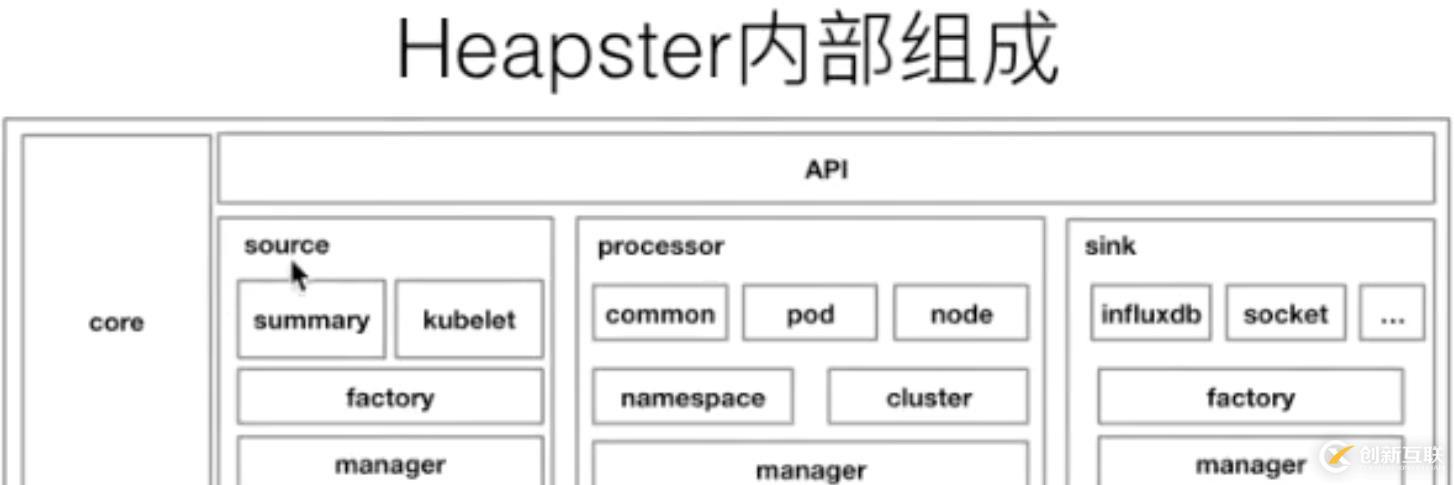
上圖是 Heapster 內(nèi)部的一個架構(gòu)。大家可以發(fā)現(xiàn)它分為幾個部分,第一個部分是 core 部分,然后上層是有一個通過標(biāo)準(zhǔn)的 http 或者 https 暴露的這個 API。然后中間是 source 的部分,source 部分相當(dāng)于是采集數(shù)據(jù)暴露的不同的接口,然后 processor 的部分是進(jìn)行數(shù)據(jù)轉(zhuǎn)換以及數(shù)據(jù)聚合的部分。最后是 sink 部分,sink 部分是負(fù)責(zé)數(shù)據(jù)離線的,這個是早期的 Heapster 的一個應(yīng)用的架構(gòu)。那到后期的時候呢,K8s 做了這個監(jiān)控接口的一個標(biāo)準(zhǔn)化,逐漸就把 Heapster 進(jìn)行了裁剪,轉(zhuǎn)化成了 metrics-server。
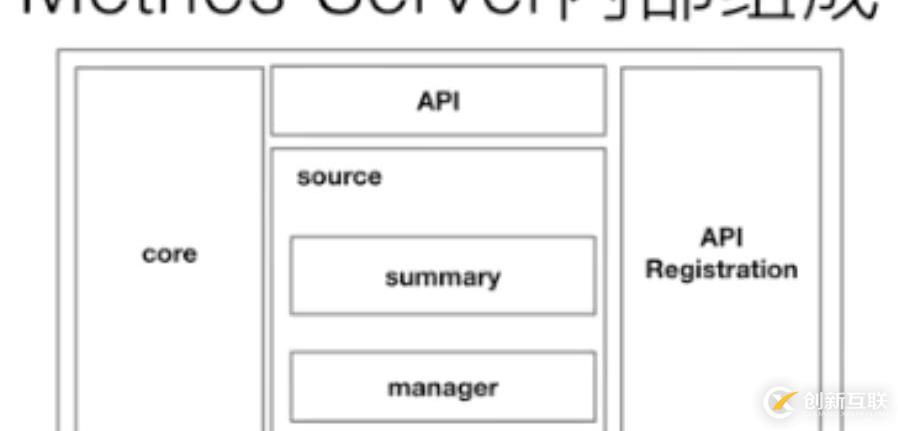
目前 0.3.1 版本的 metrics-server 大致的一個結(jié)構(gòu)就變成了上圖這樣,是非常簡單的:有一個 core 層、中間的 source 層,以及簡單的 API 層,額外增加了 API Registration 這層。這層的作用就是它可以把相應(yīng)的數(shù)據(jù)接口注冊到 K8s 的 API server 之上,以后客戶不再需要通過這個 API 層去訪問 metrics-server,而是可以通過這個 API 注冊層,通過 API server 訪問 API 注冊層,再到 metrics-server。這樣的話,真正的數(shù)據(jù)消費(fèi)方可能感知到的并不是一個 metrics-server,而是說感知到的是實(shí)現(xiàn)了這樣一個 API 的具體的實(shí)現(xiàn),而這個實(shí)現(xiàn)是 metrics-server。這個就是 metrics-server 改動大的一個地方。
Kubernetes 的監(jiān)控接口標(biāo)準(zhǔn)
在 K8s 里面針對于監(jiān)控,有三種不同的接口標(biāo)準(zhǔn)。它將監(jiān)控的數(shù)據(jù)消費(fèi)能力進(jìn)行了標(biāo)準(zhǔn)化和解耦,實(shí)現(xiàn)了一個與社區(qū)的融合,社區(qū)里面主要分為三類。
第一類 Resource Metrice
對應(yīng)的接口是 metrics.k8s.io,主要的實(shí)現(xiàn)就是 metrics-server,它提供的是資源的監(jiān)控,比較常見的是節(jié)點(diǎn)級別、pod 級別、namespace 級別、class 級別。這類的監(jiān)控指標(biāo)都可以通過 metrics.k8s.io 這個接口獲取到。
第二類 Custom Metrics
對應(yīng)的 API 是 custom.metrics.k8s.io,主要的實(shí)現(xiàn)是 Prometheus。它提供的是資源監(jiān)控和自定義監(jiān)控,資源監(jiān)控和上面的資源監(jiān)控其實(shí)是有覆蓋關(guān)系的,而這個自定義監(jiān)控指的是:比如應(yīng)用上面想暴露一個類似像在線人數(shù),或者說調(diào)用后面的這個數(shù)據(jù)庫的 MySQL 的慢查詢。這些其實(shí)都是可以在應(yīng)用層做自己的定義的,然后并通過標(biāo)準(zhǔn)的 Prometheus 的 client,暴露出相應(yīng)的 metrics,然后再被 Prometheus 進(jìn)行采集。
而這類的接口一旦采集上來也是可以通過類似像 custom.metrics.k8s.io 這樣一個接口的標(biāo)準(zhǔn)來進(jìn)行數(shù)據(jù)消費(fèi)的,也就是說現(xiàn)在如果以這種方式接入的 Prometheus,那你就可以通過 custom.metrics.k8s.io 這個接口來進(jìn)行 HPA,進(jìn)行數(shù)據(jù)消費(fèi)。
第三類 External Metrics
External Metrics 其實(shí)是比較特殊的一類,因?yàn)槲覀冎?K8s 現(xiàn)在已經(jīng)成為了云原生接口的一個實(shí)現(xiàn)標(biāo)準(zhǔn)。很多時候在云上打交道的是云服務(wù),比如說在一個應(yīng)用里面用到了前面的是消息隊(duì)列,后面的是 RBS 數(shù)據(jù)庫。那有時在進(jìn)行數(shù)據(jù)消費(fèi)的時候,同時需要去消費(fèi)一些云產(chǎn)品的監(jiān)控指標(biāo),類似像消息隊(duì)列中消息的數(shù)目,或者是接入層 SLB 的 connection 數(shù)目,SLB 上層的 200 個請求數(shù)目等等,這些監(jiān)控指標(biāo)。
那怎么去消費(fèi)呢?也是在 K8s 里面實(shí)現(xiàn)了一個標(biāo)準(zhǔn),就是 external.metrics.k8s.io。主要的實(shí)現(xiàn)廠商就是各個云廠商的 provider,通過這個 provider 可以通過云資源的監(jiān)控指標(biāo)。在阿里云上面也實(shí)現(xiàn)了阿里巴巴 cloud metrics adapter 用來提供這個標(biāo)準(zhǔn)的 external.metrics.k8s.io 的一個實(shí)現(xiàn)。
Promethues - 開源社區(qū)的監(jiān)控“標(biāo)準(zhǔn)”
接下來我們來看一個比較常見的開源社區(qū)里面的監(jiān)控方案,就是 Prometheus。Prometheus 為什么說是開源社區(qū)的監(jiān)控標(biāo)準(zhǔn)呢?
- 一是因?yàn)槭紫?Prometheus 是 CNCF 云原生社區(qū)的一個畢業(yè)項(xiàng)目。然后第二個是現(xiàn)在有越來越多的開源項(xiàng)目都以 Prometheus 作為監(jiān)控標(biāo)準(zhǔn),類似說我們比較常見的 Spark、Tensorflow、Flink 這些項(xiàng)目,其實(shí)它都有標(biāo)準(zhǔn)的 Prometheus 的采集接口。
- 第二個是對于類似像比較常見的一些數(shù)據(jù)庫、中間件這類的項(xiàng)目,它都有相應(yīng)的 Prometheus 采集客戶端。類似像 ETCD、zookeeper、MySQL 或者說 PostgreSQL,這些其實(shí)都有相應(yīng)的這個 Prometheus 的接口,如果沒有的,社區(qū)里面也會有相應(yīng)的 exporter 進(jìn)行接口的一個實(shí)現(xiàn)。
那我們先來看一下 Prometheus 整個的大致一個結(jié)構(gòu)。
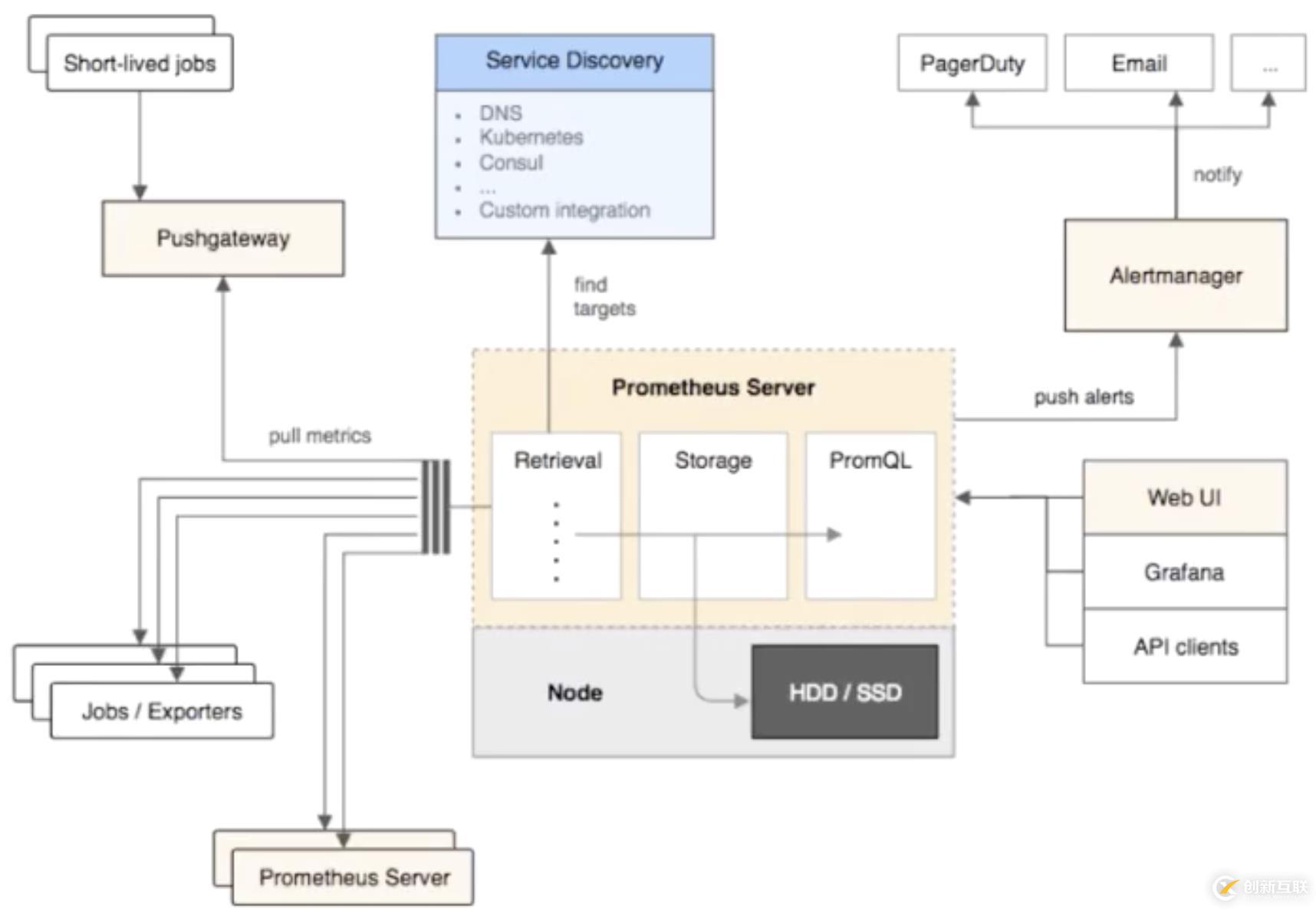
上圖是 Prometheus 采集的數(shù)據(jù)鏈路,它主要可以分為三種不同的數(shù)據(jù)采集鏈路。
- 第一種,是這個 push 的方式,就是通過 pushgateway 進(jìn)行數(shù)據(jù)采集,然后數(shù)據(jù)線到 pushgateway,然后 Prometheus 再通過 pull 的方式去 pushgateway 去拉數(shù)據(jù)。這種采集方式主要應(yīng)對的場景就是你的這個任務(wù)可能是比較短暫的,比如說我們知道 Prometheus,最常見的采集方式是拉模式,那帶來一個問題就是,一旦你的數(shù)據(jù)聲明周期短于數(shù)據(jù)的采集周期,比如我采集周期是 30s,而我這個任務(wù)可能運(yùn)行 15s 就完了。這種場景之下,可能會造成有些數(shù)據(jù)漏采。對于這種場景最簡單的一個做法就是先通過 pushgateway,先把你的 metrics push下來,然后再通過 pull 的方式從 pushgateway 去拉數(shù)據(jù),通過這種方式可以做到,短時間的不丟作業(yè)任務(wù)。
- 第二種是標(biāo)準(zhǔn)的 pull 模式,它是直接通過拉模式去對應(yīng)的數(shù)據(jù)的任務(wù)上面去拉取數(shù)據(jù)。
- 第三種是 Prometheus on Prometheus,就是可以通過另一個 Prometheus 來去同步數(shù)據(jù)到這個 Prometheus。
這是三種 Prometheus 中的采集方式。那從數(shù)據(jù)源上面,除了標(biāo)準(zhǔn)的靜態(tài)配置,Prometheus 也支持 service discovery。也就是說可以通過一些服務(wù)發(fā)現(xiàn)的機(jī)制,動態(tài)地去發(fā)現(xiàn)一些采集對象。在 K8s 里面比較常見的是可以有 Kubernetes 的這種動態(tài)發(fā)現(xiàn)機(jī)制,只需要配置一些 annotation,它就可以自動地來配置采集任務(wù)來進(jìn)行數(shù)據(jù)采集,是非常方便的。
etheus 提供了一個外置組件叫 Alentmanager,它可以將相應(yīng)的報(bào)警信息通過郵件或者短信的方式進(jìn)行數(shù)據(jù)的一個告警。在數(shù)據(jù)消費(fèi)上面,可以通過上層的 API clients,可以通過 web UI,可以通過 Grafana 進(jìn)行數(shù)據(jù)的展現(xiàn)和數(shù)據(jù)的消費(fèi)。
總結(jié)起來 Prometheus 有如下五個特點(diǎn):
- 第一個特點(diǎn)就是簡介強(qiáng)大的接入標(biāo)準(zhǔn),開發(fā)者只需要實(shí)現(xiàn) Prometheus Client 這樣一個接口標(biāo)準(zhǔn),就可以直接實(shí)現(xiàn)數(shù)據(jù)的一個采集;
- 第二種就是多種的數(shù)據(jù)采集、離線的方式。可以通過 push 的方式、 pull 的方式、Prometheus on Prometheus的方式來進(jìn)行數(shù)據(jù)的采集和離線;
- 第三種就是和 K8s 的兼容;
- 第四種就是豐富的插件機(jī)制與生態(tài);
- 第五個是 Prometheus Operator 的一個助力,Prometheus Operator 可能是目前我們見到的所有 Operator 里面做的最復(fù)雜的,但是它里面也是把 Prometheus 這種動態(tài)能力做到淋漓盡致的一個 Operator,如果在 K8s 里面使用 Prometheus,比較推薦大家使用 Prometheus Operator 的方式來去進(jìn)行部署和運(yùn)維。
kube-eventer - Kubernetes 事件離線工具
最后,我們給大家介紹一個 K8s 中的事件離線工具叫做 kube-eventer。kube-eventer 是阿里云容器服務(wù)開源出的一個組件,它可以將 K8s 里面,類似像 pod eventer、node eventer、核心組件的 eventer、crd 的 eventer 等等一系列的 eventer,通過 API sever 的這個 watch 機(jī)制離線到類似像 SLS、Dingtalk、kafka、InfluxDB,然后通過這種離線的機(jī)制進(jìn)行一個時間的審計(jì)、監(jiān)控和告警,我們現(xiàn)在已經(jīng)把這個項(xiàng)目開源到 GitHub 上了,大家有興趣的話可以來看一下這個項(xiàng)目。
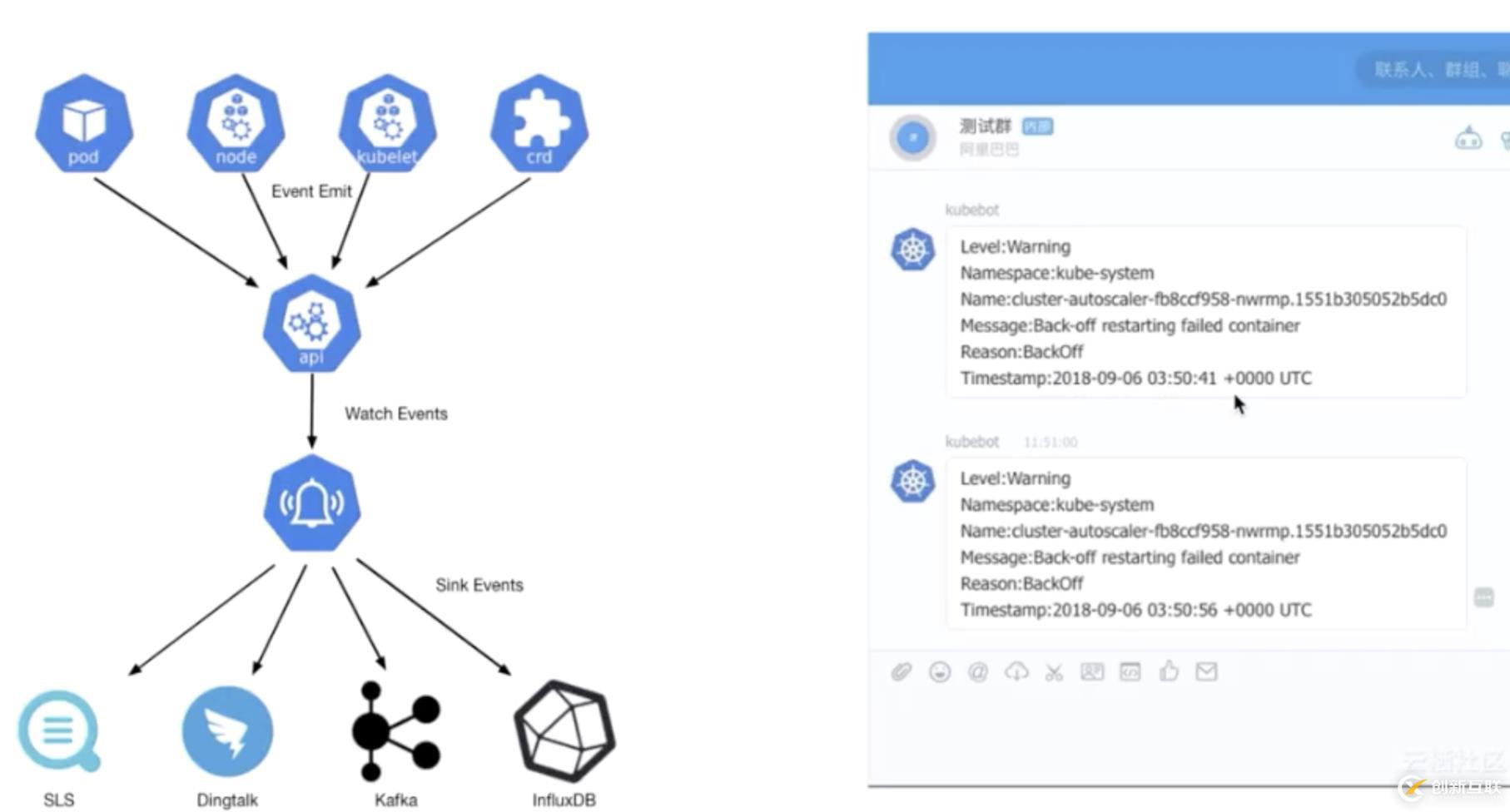
那上面這張圖其實(shí)就是 Dingtalk 的一個報(bào)警圖。可以看見里面有一個 warning 的事件,這個事件是在 kube-system namespace 之下,具體的這個 pod,大致的一個原因是這個 pod 重啟失敗了,然后大致 reason 就是 backoff,然后具體發(fā)生事件是什么時間。可以通過這個信息來做到一個 Checkups。
三、日志
日志的場景
接下來給大家來介紹一下在 K8s 里面日志的一個部分。首先我們來看一下日志的場景,日志在 K8s 里面主要分為四個大的場景:
1. 主機(jī)內(nèi)核的日志
- 第一個是主機(jī)內(nèi)核的日志,主機(jī)內(nèi)核日志可以協(xié)助開發(fā)者進(jìn)行一些常見的問題與診斷,比如說網(wǎng)棧的異常,類似像我們的 iptables mark,它可以看到有?controller table?這樣的一些 message;
- 第二個是驅(qū)動異常,比較常見的是一些網(wǎng)絡(luò)方案里面有的時候可能會出現(xiàn)驅(qū)動異常,或者說是類似 GPU 的一些場景,驅(qū)動異常可能是比較常見的一些錯誤;
- 第三個就是文件系統(tǒng)異常,在早期 docker 還不是很成熟的場景之下,overlayfs 或者是 AUFS,實(shí)際上是會經(jīng)常出現(xiàn)問題的。在這些出現(xiàn)問題后,開發(fā)者是沒有太好的辦法來去進(jìn)行監(jiān)控和診斷的。這一部分,其實(shí)是可以主機(jī)內(nèi)核日志里面來查看到一些異常;
- 再往下是影響節(jié)點(diǎn)的一些異常,比如說內(nèi)核里面的一些?kernel panic,或者是一些 OOM,這些也會在主機(jī)日志里面有相應(yīng)的一些反映。
2. Runtime 的日志
第二個是 runtime 的日志,比較常見的是 Docker 的一些日志,我們可以通過 docker 的日志來排查類似像刪除一些 Pod Hang 這一系列的問題。
3. 核心組件的日志
第三個是核心組件的日志,在 K8s 里面核心組件包含了類似像一些外置的中間件,類似像 etcd,或者像一些內(nèi)置的組件,類似像 API server、kube-scheduler、controller-manger、kubelet 等等這一系列的組件。而這些組件的日志可以幫我們來看到整個 K8s 集群里面管控面的一個資源的使用量,然后以及目前運(yùn)行的一個狀態(tài)是否有一些異常。
還有的就是類似像一些核心的中間件,如 Ingress 這種網(wǎng)絡(luò)中間件,它可以幫我們來看到整個的一個接入層的一個流量,通過 Ingress 的日志,可以做到一個很好的接入層的一個應(yīng)用分析。
4. 部署應(yīng)用的日志
最后是部署應(yīng)用的日志,可以通過應(yīng)用的日志來查看業(yè)務(wù)層的一個狀態(tài)。比如說可以看業(yè)務(wù)層有沒有 500 的請求?有沒有一些 panic?有沒有一些異常的錯誤的訪問?那這些其實(shí)都可以通過應(yīng)用日志來進(jìn)行查看的。
日志的采集
首先我們來看一下日志采集,從采集位置是哪個劃分,需要支持如下三種:
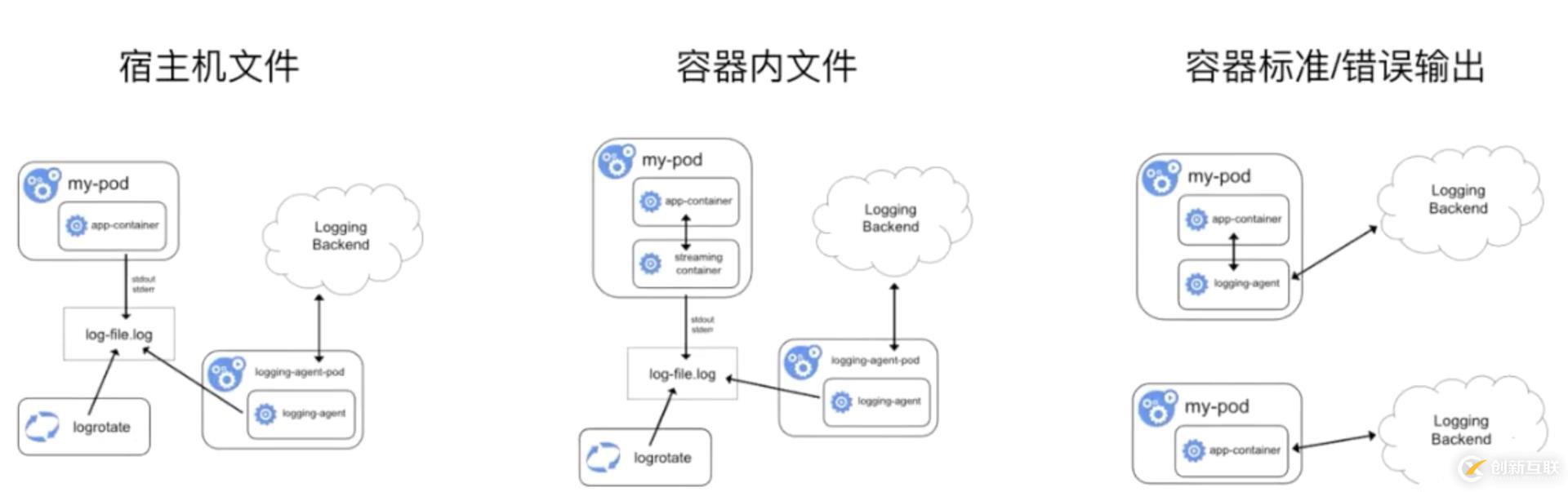
首先是宿主機(jī)文件,這種場景比較常見的是說我的這個容器里面,通過類似像 volume,把日志文件寫到了宿主機(jī)之上。通過宿主機(jī)的日志輪轉(zhuǎn)的策略進(jìn)行日志的輪轉(zhuǎn),然后再通過我的宿主機(jī)上的這個 agent 進(jìn)行采集;
- 第二種是容器內(nèi)有日志文件,那這種常見方式怎么處理呢,比較常見的一個方式是說我通過一個 Sidecar 的?streaming?的 container,轉(zhuǎn)寫到 stdout,通過 stdout 寫到相應(yīng)的 log-file,然后再通過本地的一個日志輪轉(zhuǎn),然后以及外部的一個 agent 采集;
- 第三種我們直接寫到 stdout,這種比較常見的一個策略,第一種就是直接我拿這個 agent 去采集到遠(yuǎn)端,第二種我直接通過類似像一些 sls 的標(biāo)準(zhǔn) API 采集到遠(yuǎn)端。
那社區(qū)里面其實(shí)比較推薦的是使用?Fluentd?的一個采集方案,F(xiàn)luentd 是在每一個節(jié)點(diǎn)上面都會起相應(yīng)的 agent,然后這個 agent 會把數(shù)據(jù)匯集到一個 Fluentd 的一個 server,這個 server 里面可以將數(shù)據(jù)離線到相應(yīng)的類似像 elasticsearch,然后再通過 kibana 做展現(xiàn);或者是離線到 influxdb,然后通過 Grafana 做展現(xiàn)。這個其實(shí)是社區(qū)里目前比較推薦的一個做法。
四、總結(jié)
最后給大家做一下今天課程的總結(jié),以及給大家介紹一下在阿里云上面監(jiān)控和日志的最佳實(shí)踐。在課程開始的時候,給大家介紹了監(jiān)控和日志并不屬于 K8s 里面的核心組件,而大部分是定義了一個標(biāo)準(zhǔn)的一個接口方式,然后通過上層的這個云廠商進(jìn)行各自的一個適配。
阿里云容器服務(wù)監(jiān)控體系
監(jiān)控體系組件介紹
首先,我先給大家來介紹一下在阿里云容器服務(wù)里面的監(jiān)控體系,這張圖實(shí)際上是監(jiān)控的一個大圖。
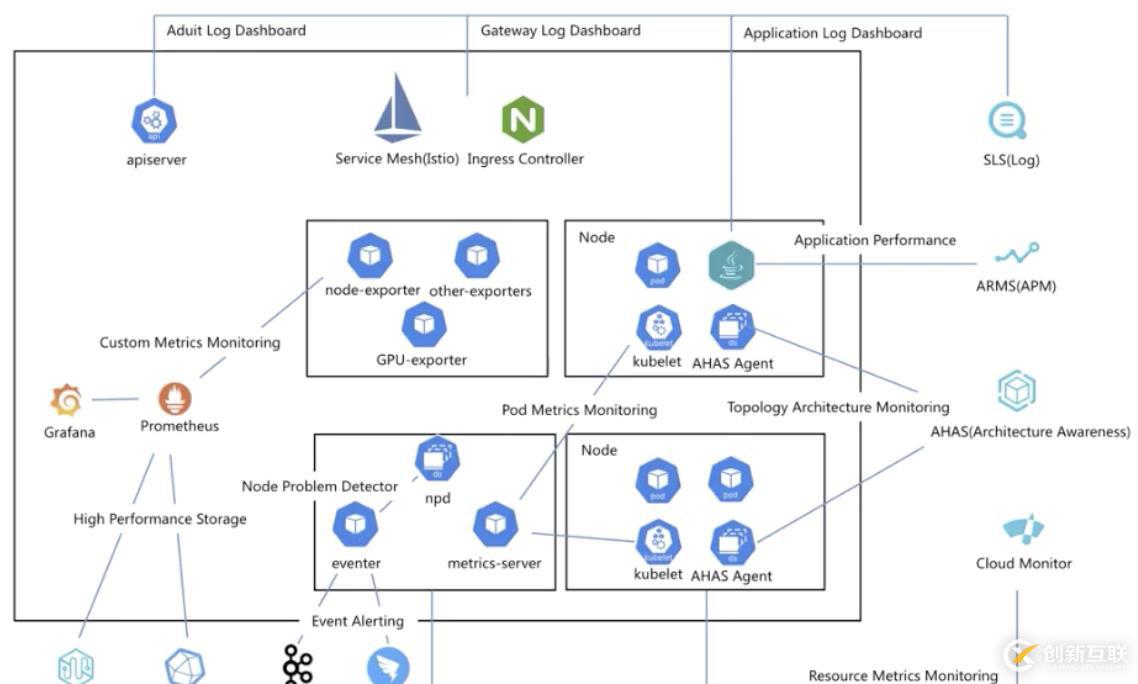
右側(cè)的四個產(chǎn)品是和監(jiān)控日志相關(guān)比較緊密的四個產(chǎn)品:
sls
第一個是 SLS,就是日志服務(wù),那剛才我們已經(jīng)提到了在 K8s 里面日志分為很多種不同的采集,比如說有核心組件的日志、接入層的日志、還有應(yīng)用的日志等等。在阿里云容器服務(wù)里面,可以通過 API server 采集到審計(jì)的日志,然后可以通過類似像 service mesh 或者 ingress controller 采集到接入層的日志,然后以及相應(yīng)的應(yīng)用層采集到應(yīng)用的日志。
有了這條數(shù)據(jù)鏈路之后,其實(shí)還不夠。因?yàn)閿?shù)據(jù)鏈路只是幫我們做到了一個數(shù)據(jù)的離線,我們還需要做上層的數(shù)據(jù)的展現(xiàn)和分析。比如說像審計(jì),可以通過審計(jì)日志來看到今天有多少操作、有多少變更、有沒有attack、系統(tǒng)有沒有異常。這些都可以通過審計(jì)的 Dashboard 來查看。
ARMS
第二個就是應(yīng)用的一個性能監(jiān)控。性能監(jiān)控上面,可以通過這個 ARMS 這樣的產(chǎn)品來去進(jìn)行查看。ARMS 目前支持的 JAVA、PHP 兩種語言,可以通過 ARMS 來做應(yīng)用的一個性能診斷和問題的一個調(diào)優(yōu)。
AHAS
第三個是比較特殊的叫 AHAS。AHAS 是一個架構(gòu)感知的監(jiān)控,我們知道在 K8s 里面,很多時候都是通過一些微服的架構(gòu)進(jìn)行部署的。微服帶來的問題就是組件會變的非常多,組件的副本處也會變的很多。這會帶來一個在拓?fù)涔芾砩厦娴囊粋€復(fù)雜性。
如果我們想要看一個應(yīng)用在 K8s 中流量的一個走向,或者是針對流量異常的一個排查,其實(shí)沒有一個很好的可視化是很復(fù)雜的。AHAS 的一個作用就是通過網(wǎng)絡(luò)棧的一個監(jiān)控,可以繪制出整個 K8s 中應(yīng)用的一個拓?fù)潢P(guān)系,然后以及相應(yīng)的資源監(jiān)控和網(wǎng)絡(luò)的帶寬監(jiān)控、流量的監(jiān)控,以及異常事件的一個診斷。任何如果有架構(gòu)拓?fù)涓兄囊粋€層面,來實(shí)現(xiàn)另一種的監(jiān)控解決方案。
Cloud Monitor
最后是 Cloud Monitor,也就是基礎(chǔ)的云監(jiān)控。它可以采集標(biāo)準(zhǔn)的 Resource Metrics Monitoring,來進(jìn)行監(jiān)控?cái)?shù)據(jù)的一個展現(xiàn),可以實(shí)現(xiàn) node、pod 等等監(jiān)控指標(biāo)的一個展現(xiàn)和告警。
阿里云增強(qiáng)的功能
這一部分是阿里云在開源上做的增強(qiáng)。首先是 metrics-server,文章開始提到了 metrics-server 做了很多的一個精簡。但是從客戶的角度來講,這個精簡實(shí)際上是把一些功能做了一個裁剪,這將會帶來很多不便。比如說有很多客戶希望將監(jiān)控?cái)?shù)據(jù)離線到類似像 SLS 或者是 influxdb,這種能力實(shí)際上用社區(qū)的版本是沒有辦法繼續(xù)來做的,這個地方阿里云繼續(xù)保留了常見的維護(hù)率比較高的 sink,這是第一個增強(qiáng)。
然后是第二個增強(qiáng),因?yàn)樵?K8s 里面整合的一個生態(tài)的發(fā)展并不是以同樣的節(jié)奏進(jìn)行演進(jìn)的。比如說 Dashboard 的發(fā)布,并不是和 K8s 的大版本進(jìn)行匹配的。比如 K8s 發(fā)了 1.12,Dashboard 并不會也發(fā) 1.12 的版本,而是說它會根據(jù)自己的節(jié)奏來去發(fā)布,這樣會造成一個結(jié)果就是說以前依賴于 Heapster 的很多的組件在升級到 metrics-server 之后就直接 break 掉,阿里云在 metrics-server 上面做了完整的 Heapster 兼容,也就是說從目前 K8s 1.7 版本一直到 K8s 1.14 版本,都可以使用阿里云的 metrics-server,來做到完整的監(jiān)控組件的消費(fèi)的一個兼容。
還有就是 eventer 和 npd,上面提到了 kube-eventer 這個組件。然后在 npd 上面,我們也做了很多額外的增強(qiáng),類似像增加了很多監(jiān)控和檢測項(xiàng),類似像?kernel Hang、npd 的一個檢測、出入網(wǎng)的監(jiān)控、snat 的一個檢測。然后還有類似像 fd 的 check,這些其實(shí)都是在 npd 里面的一些監(jiān)控項(xiàng),阿里云做了很多的增強(qiáng)。然后開發(fā)者可以直接部署 npd 的一個 check,就可以實(shí)現(xiàn)節(jié)點(diǎn)診斷的一個告警,然后并通過 eventer 離線上的 kafka 或者是 Dingtalk。
再往上是 Prometheus 生態(tài),Prometheus 生態(tài)里面,在存儲層可以讓開發(fā)者對接,阿里云的 HiTSDB 以及 InfluxDB,然后在采集層提供了優(yōu)化的 node-exporter,以及一些場景化監(jiān)控的 exporter,類似像 Spark、TensorFlow、Argo 這類場景化的 exporter。還有就是針對于 GPU,阿里云做了很多額外的增強(qiáng),類似于像支持 GPU 的單卡監(jiān)控以及 GPU share 的監(jiān)控,然后在 Prometheus 上面,我們連同 ARMS 團(tuán)隊(duì)推出了托管版的 Prometheus,開發(fā)者可以使用開箱即用的 helm chats,不需要部署 Prometheus server,就可以直接體驗(yàn)到 Prometheus 的一個監(jiān)控采集能力。
阿里云容器服務(wù)日志體系
在日志上面,阿里云做了哪些增強(qiáng)呢?首先是采集方式上,做到了完整的一個兼容。可以采集 pod log 日志、核心組件日志、docker engine 日志、kernel 日志,以及類似像一些中間件的日志,都收集到 SLS。收集到 SLS 之后,我們可以通過數(shù)據(jù)離線到 OSS,離線到 Max Compute,做一個數(shù)據(jù)的離線和歸檔,以及離線預(yù)算。
然后還有是對于一些數(shù)據(jù)的實(shí)時消費(fèi),我們可以到 Opensearch、可以到 E-Map、可以到 Flink,來做到一個日志的搜索和上層的一個消費(fèi)。在日志展現(xiàn)上面,我們可以既對接開源的 Grafana,也可以對接類似像 DataV,去做數(shù)據(jù)展示,實(shí)現(xiàn)一個完整的數(shù)據(jù)鏈路的采集和消費(fèi)。
本文總結(jié)
- 首先主要為大家介紹了監(jiān)控,其中包括:四種容器場景下的常見的監(jiān)控方式;Kubernetes 的監(jiān)控演進(jìn)和接口標(biāo)準(zhǔn);兩種常用的來源的監(jiān)控方案;
- 在日志上我們主要介紹了四種不同的場景,介紹了 Fluentd 的一個采集方案;
- 最后向大家介紹了一下阿里云日志和監(jiān)控的一個最佳實(shí)踐。
“ 阿里巴巴云原生微信公眾號(ID:Alicloudnative)關(guān)注微服務(wù)、Serverless、容器、Service Mesh等技術(shù)領(lǐng)域、聚焦云原生流行技術(shù)趨勢、云原生大規(guī)模的落地實(shí)踐,做最懂云原生開發(fā)者的技術(shù)公眾號。”
另外有需要云服務(wù)器可以了解下創(chuàng)新互聯(lián)cdcxhl.cn,海內(nèi)外云服務(wù)器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務(wù)器、裸金屬服務(wù)器、高防服務(wù)器、香港服務(wù)器、美國服務(wù)器、虛擬主機(jī)、免備案服務(wù)器”等云主機(jī)租用服務(wù)以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務(wù)可用性高、性價(jià)比高”等特點(diǎn)與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應(yīng)用場景需求。
名稱欄目:從零開始入門K8s|可觀測性:監(jiān)控與日志-創(chuàng)新互聯(lián)
分享鏈接:http://vcdvsql.cn/article6/eepig.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供做網(wǎng)站、服務(wù)器托管、搜索引擎優(yōu)化、靜態(tài)網(wǎng)站、網(wǎng)站建設(shè)、標(biāo)簽優(yōu)化
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 『高級篇』docker之微服務(wù)間如何通訊(六)-創(chuàng)新互聯(lián)
- Echarts+SpringMvc顯示后臺實(shí)時數(shù)據(jù)-創(chuàng)新互聯(lián)
- 云服務(wù)器怎么卸載軟件-創(chuàng)新互聯(lián)
- 解決koa2ctx.renderisnotafunction報(bào)錯問題-創(chuàng)新互聯(lián)
- 使用CSS怎么實(shí)現(xiàn)導(dǎo)航欄下劃線跟隨效果-創(chuàng)新互聯(lián)
- 怎么在php中利用array_slice取出數(shù)組中的一段序列-創(chuàng)新互聯(lián)
- MySQL中常見的日志問題有哪些-創(chuàng)新互聯(lián)

- 移動網(wǎng)站建設(shè)要注意哪些細(xì)節(jié) 2021-10-03
- 做好移動網(wǎng)站建設(shè)7大策略必讀 2022-08-08
- 移動網(wǎng)站建設(shè)都有那些常見問題? 2022-04-30
- 移動網(wǎng)站建設(shè)關(guān)于用戶注冊設(shè)計(jì)的技巧 2021-07-21
- 移動網(wǎng)站建設(shè)是未來的一個大好市場 2020-11-07
- 【網(wǎng)站建設(shè)】移動網(wǎng)站建設(shè)的常見問題匯總! 2022-01-17
- 深度好文教你移動網(wǎng)站建設(shè)技巧 2021-04-29
- 移動網(wǎng)站建設(shè)預(yù)算已成為有效方式 2016-08-21
- 移動網(wǎng)站建設(shè)與搜索引擎的關(guān)系 2023-03-27
- 移動網(wǎng)站建設(shè)需要注意什么?怎樣設(shè)計(jì)才能提高用戶體驗(yàn)? 2022-10-22
- 移動網(wǎng)站建設(shè)需要注意哪些事項(xiàng)? 2022-12-01
- 移動網(wǎng)站建設(shè)如何更好的引流量 2022-11-19