Python如何提取PDF表格數(shù)據(jù)-創(chuàng)新互聯(lián)
小編給大家分享一下Python如何提取PDF表格數(shù)據(jù),相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
目前創(chuàng)新互聯(lián)公司已為千余家的企業(yè)提供了網(wǎng)站建設(shè)、域名、雅安服務(wù)器托管、網(wǎng)站托管、服務(wù)器租用、企業(yè)網(wǎng)站設(shè)計(jì)、東光網(wǎng)站維護(hù)等服務(wù),公司將堅(jiān)持客戶導(dǎo)向、應(yīng)用為本的策略,正道將秉承"和諧、參與、激情"的文化,與客戶和合作伙伴齊心協(xié)力一起成長,共同發(fā)展。從 PDF 表格中獲取數(shù)據(jù)是一項(xiàng)痛苦的工作。不久前,一位開發(fā)者提供了一個(gè)名為 Camelot 的工具,使用三行代碼就能從 PDF 文件中提取表格數(shù)據(jù)。
PDF 文件是一種非常常用的文件格式,通常用于正式的電子版文件。它能夠很好的將不同的排版格式固定下來,形成版面清晰且美觀的展示效果。然而,對(duì)于想要從 PDF 中提取信息的人們來說,PDF 是個(gè)噩夢(mèng),尤其是表格。
大量的學(xué)術(shù)報(bào)告、論文、分析文章都使用 PDF 展示其中的表格數(shù)據(jù),但是對(duì)于如果想要直接從表格中復(fù)制數(shù)據(jù)則會(huì)非常麻煩。不久前,有一位開發(fā)者提供了一個(gè)可從文字 PDF 中提取表格信息的工具——Camelot,能夠直接將大部分表格轉(zhuǎn)換為 Pandas 的 Dataframe。
項(xiàng)目地址:https://github.com/camelot-dev/camelot
Camelot 是什么
據(jù)項(xiàng)目介紹稱,Camelot 是一個(gè) Python 工具,用于將 PDF 文件中的表格數(shù)據(jù)提取出來。
具體而言,用戶可以像使用 Pandas 那樣打開 PDF 文件,然后利用這個(gè)工具提取表格數(shù)據(jù),最后再指定輸出的形式(如 csv 文件)。
代碼示例
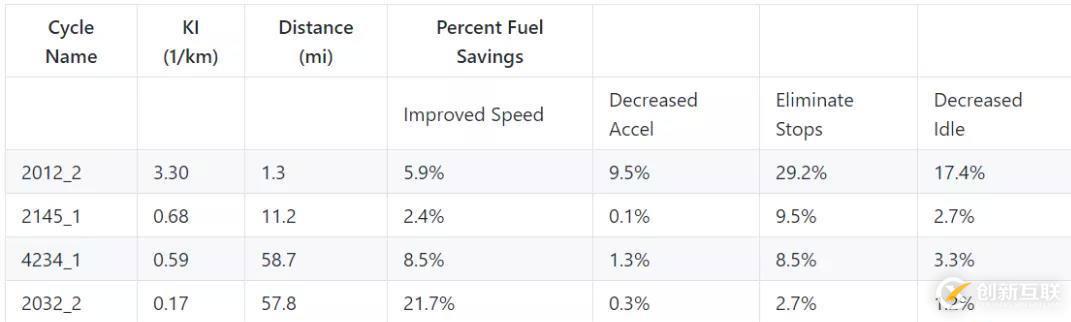
項(xiàng)目提供的 PDF 文件如圖所示,假設(shè)用戶需要提取這些文字之間的表格 2-1 中的信息。
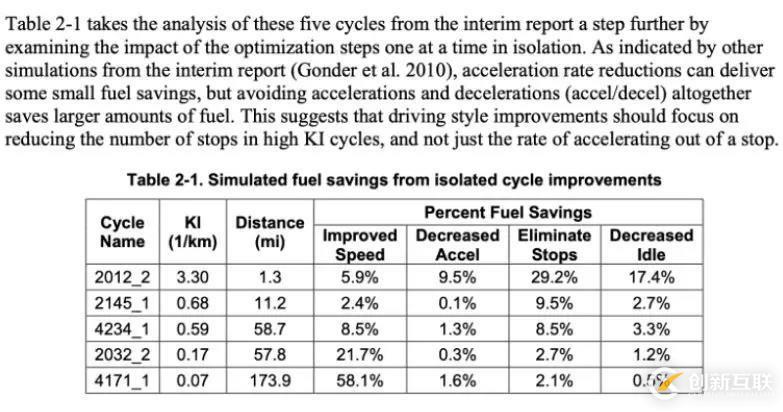
PDF 文件。我們需要提取表格 2-1。
使用 Camelot 提取表格數(shù)據(jù)的代碼如下:
>>> import camelot
>>> tables = camelot.read_pdf('foo.pdf') #類似于Pandas打開CSV文件的形式
>>> tables[0].df # get a pandas DataFrame!
>>> tables.export('foo.csv', f='csv', compress=True) # json, excel, html, sqlite,可指定輸出格式
>>> tables[0].to_csv('foo.csv') # to_json, to_excel, to_html, to_sqlite, 導(dǎo)出數(shù)據(jù)為文件
>>> tables
<TableList n=1>
>>> tables[0]
<Table shape=(7, 7)> # 獲得輸出的格式
>>> tables[0].parsing_report
{
'accuracy': 99.02,
'whitespace': 12.24,
'order': 1,
'page': 1
}以下為輸出的結(jié)果,對(duì)于合并的單元格,Camelot 在抽取后做了空行處理,這是一個(gè)穩(wěn)妥的方法。
安裝方法
項(xiàng)目作者提供了三種安裝方法。首先,你可以使用 Conda 進(jìn)行安裝,這是最簡單的。
conda install -c conda-forge camelot-py
最流行的安裝方法是使用 pip 安裝。
pip install camelot-py[cv]
還可以從項(xiàng)目中克隆代碼,并使用源碼安裝。
git clone https://www.github.com/camelot-dev/camelot cd camelot pip install ".[cv]"
以上是“Python如何提取PDF表格數(shù)據(jù)”這篇文章的所有內(nèi)容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內(nèi)容對(duì)大家有所幫助,如果還想學(xué)習(xí)更多知識(shí),歡迎關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道!
名稱欄目:Python如何提取PDF表格數(shù)據(jù)-創(chuàng)新互聯(lián)
本文網(wǎng)址:http://vcdvsql.cn/article10/cssodo.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供軟件開發(fā)、網(wǎng)站排名、品牌網(wǎng)站建設(shè)、企業(yè)建站、網(wǎng)站營銷、外貿(mào)網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- Django---forms各種類型表單使用-創(chuàng)新互聯(lián)
- 部署readthedocs私有文檔庫-創(chuàng)新互聯(lián)
- php變量名中不能包含的字符是什么-創(chuàng)新互聯(lián)
- oracle12c新特性索引壓縮COMPRESSADVANCEDLOW-創(chuàng)新互聯(lián)
- [故障解決]SFTP不能連接服務(wù)器怎么辦?-創(chuàng)新互聯(lián)
- mysql如何利用binlog進(jìn)行數(shù)據(jù)恢復(fù)詳解-創(chuàng)新互聯(lián)
- go語言中導(dǎo)入包的方法-創(chuàng)新互聯(lián)

- 網(wǎng)站設(shè)計(jì)時(shí),設(shè)計(jì)師如何考量背景圖的選擇? 2022-11-17
- 企業(yè)為什么要做雙語網(wǎng)站設(shè)計(jì) 2022-09-23
- 在無錫單頁面網(wǎng)站設(shè)計(jì)必知的技巧 2022-06-26
- 網(wǎng)站設(shè)計(jì)必須要考慮的問題 2021-06-22
- 極簡主義網(wǎng)站設(shè)計(jì)的7個(gè)特點(diǎn) 2019-04-17
- 網(wǎng)站設(shè)計(jì)對(duì)網(wǎng)站運(yùn)營產(chǎn)生的影響有哪些 2021-11-19
- 如何看待網(wǎng)站設(shè)計(jì)市場 2019-05-04
- 成都網(wǎng)站建設(shè)_企業(yè)網(wǎng)站設(shè)計(jì)_定制建站 2023-02-28
- 商城網(wǎng)站設(shè)計(jì)八大原則 2022-07-30
- 上海網(wǎng)站設(shè)計(jì)公司、上海網(wǎng)站建設(shè)公司為企業(yè)占據(jù)市場提供動(dòng)力支持 2020-11-06
- 松江網(wǎng)站設(shè)計(jì):什么是理想的網(wǎng)站結(jié)構(gòu)? 2020-11-15
- 深圳網(wǎng)站設(shè)計(jì)公司談首頁設(shè)計(jì)合理布局 2022-06-30