小機上運行ORACLE需要注意的進程調度BUG
前 言
創(chuàng)新互聯(lián)是創(chuàng)新、創(chuàng)意、研發(fā)型一體的綜合型網(wǎng)站建設公司,自成立以來公司不斷探索創(chuàng)新,始終堅持為客戶提供滿意周到的服務,在本地打下了良好的口碑,在過去的10年時間我們累計服務了上千家以及全國政企客戶,如石涼亭等企業(yè)單位,完善的項目管理流程,嚴格把控項目進度與質量監(jiān)控加上過硬的技術實力獲得客戶的一致夸獎。
小y這個名字,是筆者臨時想的一個筆名,其實沒有什么特殊的含義,就暫且用他來代表我們這些為各個數(shù)據(jù)中心奉獻自己青春的一群默默無聞的IT人吧!
小y今天要和大家分享的是一個疑難雜癥的分析過程。如果大家有耐心讀完這個案例,一定會或多或少有些收獲,也就沒浪費小y的一片苦心。
具體來說是一個應用間歇性局部掛起案例的分析過程,報告中將對Oracle數(shù)據(jù)庫穩(wěn)定運行的共性風險和隱患作出提醒。
據(jù)客戶反映,應用會間歇性出現(xiàn)異常,包括insert單條記錄在內的操作長時間無法完成,按照客戶的說法,數(shù)據(jù)庫內可能有“死鎖”現(xiàn)象,希望能夠找到問題發(fā)生的根因,提出解決方案,以避免問題再次發(fā)生。
2015年12月23日,問題再次發(fā)生,客戶再次聯(lián)系到小y,小y通過遠程方式進行了信息收集和故障診斷,最終定位了問題的根本原因。
環(huán)境介紹:
操作系統(tǒng) HPUX IA64 B.11.31 數(shù)據(jù)庫 ORACLE 10.2.0.5,單實例 |
>>> 2.1 異常時刻數(shù)據(jù)庫出現(xiàn)異常等待

可以看到:
有2個會話在等待行鎖(拿不到事務鎖,需要一直等待),另外有一個會話在等待“undo segment extension”。
>>>> 2.2 梳理異常等待之間的關系
1)分析行鎖等待的阻塞者

可以看到:
SID 285/290的兩個會話都是被SID=315的會話阻塞了,他們在等待行鎖,時間已經超過60000秒。
2)查看阻塞者SID=315在做什么

可以看到:
SID=315的會話阻塞了其他兩個會話,他本身也處于一個資源的等待上,在等待“undo segment extension”,已經等了70384秒了!該等待事件沒有阻塞者。
3)SID=315在執(zhí)行的SQL語句
INSERT INTO TABLE_NAME(COL1,COL2,COL3,COL4,COL5,COL6,COL7)VALUES(:1,:2,:3,:4,:5,:6,:7) |
>>>> 2.3 什么是“undo segment extension”等待事件
“undo segment extension”即等待回滾段擴展完成。當執(zhí)行增刪改等操作時,數(shù)據(jù)庫需要回滾段來存儲前鏡像,當回滾段空間不足時,則需要擴展。
具體來說,undo segment的擴展或者回收(extend / shrink)都是前臺進程通過通知SMON后臺進程來完成的。
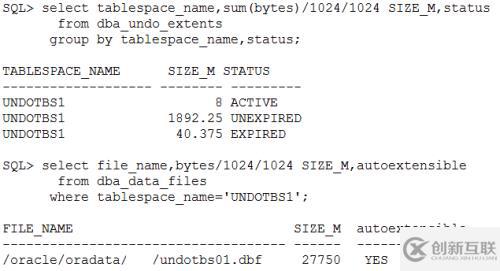
發(fā)出下列命令查看undo的使用情況,UNDO表有空有1個文件27750M,其中目前活動的值有8M,未過undo retention的1892M,過了undo retention的有40M未發(fā)現(xiàn)異常。
>>>> 2.4 收集數(shù)據(jù)庫hanganalyze和systemstate信息
發(fā)出下列命令異常時候的hanganalyze和systemstate信息
SQL> oradebug setmypid Statement processed. SQL> oradebug hanganalyze 3 Hang Analysis in /oracle/admin/xxdb/udump/xxdb_ora_14136.trc SQL> SQL> oradebug dump systemstate 266 Statement processed. SQL> oradebug tracefile_name /oracle/admin/xxdb/udump/xxdb_ora_14136.trc |
>>>> 2.5 問題在收集信息后自動解決
在發(fā)出上述命令收集相關信息后,再次檢查,發(fā)現(xiàn)數(shù)據(jù)庫異常等待居然已經自動解決掉了。
從原理和經驗分析,這是因為oradebug 在收集systemstate dump時,其中會調用dbx等OS命令去做進程堆棧的打印,此時會將進行wakeup(喚醒)。
如下所示
>>>> 2.6 獲得SID:315會話的活動會話歷史
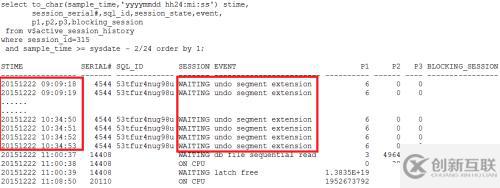
可以看到,確實一直在等待undo segment extension
>>>> 2.7 分析systemstate dump定位問題根因
其中SID=315的會話在等待”undo segment extension”,該會話對應PROCESS 19 SSD當中的信息如下:
PROCESS 19: ---------------------------------------- SO: c00000003949b948, type: 2, owner: 0000000000000000, flag: INIT/-/-/0x00 (process) Oracle pid=19, calls cur/top: c0000000397209b0/c0000000397209b0, flag: (0) - int error: 0, call error: 0, sess error: 0, txn error 0 (post info) last post received: 0 0 121 last post received-location: kcbzww last process to post me: c000000039496148 1 22 last post sent: 0 0 121 last post sent-location: kcbzww last process posted by me: c000000039496148 1 22 (latch info) wait_event=0 bits=0 Process Group: DEFAULT, pseudo proc: c000000039529928 O/S info: user: oracle, term: UNKNOWN, ospid: 11880 OSD pid info: Unix process pid: 11880, p_w_picpath: oracle@ap-machine- *** 2015-12-22 10:34:53.431 Short stack dump: ksdxfstk()+48<-ksdxcb()+1200<-sspuser()+368<-<kernel><-_pw_wait()+48<-pw_wait()+128<-sskgpwwait()+384<-skgpwwait()+208<-ksliwat()+1728<-kslwaitns_timed()+112<-kskthbwt()+400<-kslwait()+640<-ktugur()+4416<-ktuchg()+1280<-ktbchg2()+704<-kdiins0()+267536<-kdiinsp()+320<-kauxsin()+2960<-insidx()+1744<-insrow()+1440<-insdrv()+960<-inscovexe()+1408<-insExecStmtExecIniEngine()+176<-insexe()+1040<-opiexe()+13776<-kpoal8()+3808<-opiodr()+2144<-ttcpip()+1680<-opitsk()+2368<-opiino()+1664<-opiodr()+2144<-opidrv()+1248<-sou2o()+240<-opimai_real()+496<-main()+240<-main_opd_entry()+80 ---------------------------------------- SO: c0000000396d80d8, type: 4, owner: c00000003949b948, flag: INIT/-/-/0x00 (session) sid: 315 trans: c0000000355b2a28, creator: c00000003949b948, flag: (100041) USR/- BSY/-/-/-/-/- DID: 0001-0013-00000027, short-term DID: 0000-0000-00000000 txn branch: 0000000000000000 oct: 2, prv: 0, sql: c0000000384bad50, psql: c0000000384bad50, user: 33/XXDB service name: xxdb O/S info: user: , term: , ospid: 1234, machine: rvwapp2-1 program: waiting for 'db file sequential read' wait_time=0, seconds since wait started=0 file#=c, block#=2f359, blocks=1 blocking sess=0x0000000000000000 seq=42271 Dumping Session Wait History for 'undo segment extension' count=1 wait_time=2 min 45 sec segment#=6, =0, =0 for 'buffer busy waits' count=1 wait_time=0.000009 sec file#=2, block#=59, class#=1b for 'SQL*Net message from client' count=1 wait_time=0.000087 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message to client' count=1 wait_time=0.000001 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message from client' count=1 wait_time=0.000086 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message to client' count=1 wait_time=0.000001 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message from client' count=1 wait_time=0.000086 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message to client' count=1 wait_time=0.000001 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message from client' count=1 wait_time=0.000087 sec driver id=28444553, #bytes=1, =0 for 'SQL*Net message to client' count=1 wait_time=0.000001 sec driver id=28444553, #bytes=1, =0 Sampled Session History of session 315 serial 4544 --------------------------------------------------- The sampled session history is constructed by sampling the target session every 1 second. The sampling process captures at each sample if the session is in a non-idle wait, an idle wait, or not in a wait. If the session is in a non-idle wait then one interval is shown for all the samples the session was in the same non-idle wait. If the session is in an idle wait or not in a wait for consecutive samples then one interval is shown for all the consecutive samples. Though we display these consecutive samples in a single interval the session may NOT be continuously idle or not in a wait (the sampling process does not know). The history is displayed in reverse chronological order. sample interval: 1 sec, max history 120 sec --------------------------------------------------- [120 samples, 10:32:52 - 10:34:53] waited for 'undo segment extension', seq_num: 42270 p1: 'segment#'=0x6 p2: ''=0x0 p3: ''=0x0 time_waited: >= 120 sec (still in wait) --------------------------------------------------- Sampled Session History Summary: longest_non_idle_wait: 'undo segment extension' [120 samples, 10:32:52 - 10:34:53] time_waited: >= 120 sec (still in wait) |
可以看到:
進程在被ORADEBUG間接喚醒后,不再等待undo segment extension,而是做” db file sequential read”。
從前面的分析得知,“undo segment extension”即等待回滾段擴展完成。當執(zhí)行增刪改等操作時,數(shù)據(jù)庫需要回滾段來存儲前鏡像,當回滾段空間不足時,則需要擴展。具體來說,undo segment的擴展或者回收(extend / shrink)都是前臺進程通過通知SMON后臺進程來完成的。CallStack堆棧的調用中,最后停在“pw_wait”的調用上,即說明在等待SMON返回擴展UNDO SEGMENT成功與否的消息。
因此,我們需要查看SMON進程的狀態(tài)。
檢查SMON的信息如下:
PROCESS 8: ---------------------------------------- SO: c000000039496148, type: 2, owner: 0000000000000000, flag: INIT/-/-/0x00 (process) Oracle pid=8, calls cur/top: c00000003971e868/c00000003971e868, flag: (16) SYSTEM int error: 0, call error: 0, sess error: 0, txn error 0 (post info) last post received: 0 0 121 last post received-location: kcbzww last process to post me: c0000000394a0948 211 0 last post sent: 0 0 24 last post sent-location: ksasnd last process posted by me: c000000039495148 1 6 (latch info) wait_event=0 bits=0 Process Group: DEFAULT, pseudo proc: c000000039529928 O/S info: user: oracle, term: UNKNOWN, ospid: 10072 OSD pid info: Unix process pid: 10072, p_w_picpath: oracle@ap-machine- (SMON) Short stack dump: ksdxfstk()+48<-ksdxcb()+1200<-sspuser()+368<-<kernel><-_pw_wait()+48<-pw_wait()+352<-sskgpwwait()+384<-skgpwwait()+208<-ksliwat()+1728<-kslwaitns_timed()+112<-kskthbwt()+400<-kslwait()+640<-ktmmon()+1168<-ktmSmonMain()+64<-ksbrdp()+2368<-opirip()+1184<-opidrv()+1184<-sou2o()+240<-opimai_real()+336<-main()+240<-main_opd_entry()+80 ---------------------------------------- ---------------------------------------- SO: c0000000396ead68, type: 4, owner: c000000039496148, flag: INIT/-/-/0x00 (session) sid: 329 trans: 0000000000000000, creator: c000000039496148, flag: (100051) USR/- BSY/-/-/-/-/- DID: 0001-0008-00000002, short-term DID: 0000-0000-00000000 txn branch: 0000000000000000 oct: 0, prv: 0, sql: 0000000000000000, psql: 0000000000000000, user: 0/SYS service name: SYS$BACKGROUND waiting for 'smon timer' wait_time=0, seconds since wait started=3109 sleep time=12c, failed=0, =0 blocking sess=0x0000000000000000 seq=7382 Dumping Session Wait History for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 11 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 for 'smon timer' count=1 wait_time=4 min 53 sec sleep time=12c, failed=0, =0 Sampled Session History of session 329 serial 1 |
可以看到,SMON進程在等“SMON TIMER”,即空閑等待。
這說明SMON沒有因為阻塞在異常的等待上,導致無法騰出時間來處理前臺進程發(fā)過來的undo segment擴展請求。
>>>> 2.8 定位問題的根本原因
綜上所有現(xiàn)象:
1) 前臺進程SID 315向smon發(fā)送一條消息,請求對回滾段進行擴展,并在“undo segment extension“事件上等待,進程callStack停在pw_wait,即post/wait,等待消息的返回;
2) SMON進程在等待”SMON TIMER”,即空閑等待。此時SMON可能已經完成了UNDO SEGMENT的擴展請求并返回了前臺進程;也可能沒有收到前臺進程發(fā)送過來的請求;
3) ORADEBUG對SID 315收集信息并間接喚醒了該前臺進程后,前臺進行可以繼續(xù)往下工作,這說明,步驟2)的消息已經返回給前臺進程,只是由于操作系統(tǒng)調度進制的問題,未能即使將前臺進程調度到CPU上,拿到UNDO擴展成功的消息。
結上所述,我們可以判定:造成該故障的根本原因是操作系統(tǒng)調度機制的問題。
環(huán)境介紹:
操作系統(tǒng) HPUX IA64 B.11.31 數(shù)據(jù)庫 ORACLE 10.2.0.5,單實例 |
因此,我們在ORACLE官方網(wǎng)站BUG中以“Hpux pw_wait“做關鍵字索HPUX已知的調度缺陷,可知命中操作系統(tǒng)缺陷。
The problem is a defect in the pw_wait() O/S system call. 即HPUX11.31上,當安裝了PHKL_37456這個調度補丁后,操作系統(tǒng)調用pw_wait存在缺陷,導致進程無法從post/wait中被喚醒,解決方案是Solution: on 11.31 install PHKL_38397 or later equivalent. |
以下是官網(wǎng)原文
Processes Hang Waiting on 'cursor: pin S wait on X' (and other Wait Events) on HP-UX 11.23 and 11.31 Itanium Systems (Doc ID 580273.1) In this Document SymptomsChangesCauseSolutionAPPLIES TO: Oracle Database - Enterprise Edition - Version 9.2.0.1 and later SYMPTOMS Process hangs indefinitely waiting on one of the following wait events:
There is no blocker process. 0: c0000000003e2ff0 : pw_wait() + 0x30 (/usr/lib/hpux64/libc.so.1) First few calls of the call stacks will differ depending on the particular wait event. ( Attached to process 6144 ("ora_j032_SATAVA02") [64-bit] ) CHANGES The following HP Patch Bundle for 11.31 may have been recently applied Note: it has been brought to our attention that the problem may also occur on HP-UX 11.23 systems. CAUSE The problem is a defect in the pw_wait() O/S system call. Please note that the wait events shown above 'cursor: pin S wait on X' and 'kksfbc child completion' can occur for a number of other legitimate reasons, so presence of these waits alone does not indicate that the problem described in this article has been encountered. You will need to verify in detail the other symptoms described here when investigating the issue you are facing. The problem is also reported to occur on HP-UX 11.23. We have no information at this time on specific PHKL patch levels are susceptible to it, only that it is fixed starting with PHKL_37809. SOLUTION A number of options are available to work around or resolve this problem:
1. identify the Unix process id of the hanging process 2. use oradebug on it as follows (the unlimit command is sufficient to stop the hang) SQL> oradebug setospid <unix process id> 3. alternatively, if there are many processes hanging on 'cursor: pin S wait on X', or time is short, a systemstate dump (at minimum level 1 to minimize the amount of trace that will be written) will be the quickest way to go over all hanging processes and wake them up: SQL> oradebug setmypid
Note: the patches whose names begin with PHKL_ are HP-UX patches. Please check with HP-UX support on the latest applicable patch numbers as such patches are regularly updated and superceded. |
>>>> 3.1 原因總結:應用程序中的下列INSERT語句
INSERT INTO TABLE_NAME(COL1,COL2,COL3,COL4,COL5,COL6,COL7)VALUES(:1,:2,:3,:4,:5,:6,:7) |
之所以執(zhí)行不下去,不是因為死鎖,而是因為該會話即SID=315的會話,需要執(zhí)行DML,因此需要UNDO SEGMENT即回滾段來存儲前鏡像,但發(fā)現(xiàn)回滾段空間不足,需要通知SMON后臺進程來完成擴展的請求,但是長時間沒有獲得回滾段擴展成功與否的返回消息。前臺進程和SMON之間通過POST/WAIT進制來通訊。
由于操作系統(tǒng)HPUX調度的缺陷,具體來說是pw_wait系統(tǒng)調用(post/wait)存在缺陷,當SMON進程完成回滾段擴展后,消息返回時,前臺進程SID=315并沒有能被及時調度到CPU上繼續(xù)處理后續(xù)工作,即體現(xiàn)出來就是等待在“undo segment extension“事件上等待,當我們人為使用ORADEBUG對SID 315收集信息并間接喚醒了該前臺進程后,前臺進行可以繼續(xù)往下工作,這更加印證了SMON已經將消息已經返回給前臺進程,只是由于操作系統(tǒng)調度進制的問題,未能即使將前臺進程調度到CPU上,拿到UNDO擴展成功的消息
造成該故障的根本原因是操作系統(tǒng)調度機制的問題,該問題命中操作系統(tǒng)HPUX上的已知缺陷。
The problem is a defect in the pw_wait() O/S system call. 即HPUX11.31上,當安裝了PHKL_37456這個調度補丁后,操作系統(tǒng)調用pw_wait存在缺陷,導致進程無法從post/wait中被喚醒,解決方案是Solution: on 11.31 install PHKL_38397 or later equivalent. |
>>>> 3.2 建議
Solution: on 11.31 install PHKL_38397 or later equivalent.
請系統(tǒng)管理員為操作系統(tǒng)安裝PHKL_38397補丁。
分享名稱:小機上運行ORACLE需要注意的進程調度BUG
文章鏈接:http://vcdvsql.cn/article12/iipedc.html
成都網(wǎng)站建設公司_創(chuàng)新互聯(lián),為您提供網(wǎng)站營銷、服務器托管、外貿建站、云服務器、網(wǎng)頁設計公司、用戶體驗
聲明:本網(wǎng)站發(fā)布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創(chuàng)新互聯(lián)

- 『微信公眾號運營用戶體驗』微信運營過程中如何維護好老客戶? 2022-06-13
- 微信公眾號運營的九大步驟 2014-05-29
- 微信公眾號的盈利模式有幾種? 2014-05-25
- 創(chuàng)新互聯(lián)建站:微信公眾號使用教程介紹 2015-10-29
- 如何構架微信公眾號運營平臺 2016-09-17
- 微信公眾號運營推廣做好三點很重要 2020-12-15
- 微信公眾號代運營這種操作靠譜嗎? 2014-05-11
- 公眾平臺新增素材管理接口,對所有認證公眾號開放 2016-09-05
- 成都微信公眾號“閱讀數(shù)”是怎么算的? 2023-03-25
- 微信公眾號裂變漲粉的操作方法是什么? 2014-05-26
- 如何快速推廣微信公眾號? 2015-08-09
- 微信公眾號軟文廣告營銷策略 2022-12-01