分布式系統(事務處理)-創新互聯
- 事務(Transaction)
- 分布式事務
- 原子提交協議
- 單階段提交
- 兩階段提交
- 三階段提交
- 串行等價 / 并發控制
- 分布式死鎖
- 鎖超時
- 全局等待圖
- 邊追逐算法
- 事務放棄時的恢復
- 服務器崩潰后的恢復
- 恢復文件
- 重組恢復文件
- 日志
- 從Crash 中恢復
- 2PC 的恢復
特性:ACID
- 原子性(Atomic):對于外部世界,事務不可分割
- 一致性(Consistent):事務不違反系統不變量(system invariants)
- 隔離性(Isolated):并發事務之間互不干擾
- 持久性(Durable):一旦事務提交,其影響是永久的
事務的 API,
T = open Transaction{# 對象訪問
# 數據運算
...
abort Transaction
...
}close Transaction事務的實現技術,
- 串行等價 / 并發控制:兩階段鎖、時間戳排序、樂觀并發控制
- 事務放棄后的恢復:嚴格兩階段鎖
故障模型,
- 磁盤故障:
- 寫操作失敗、文件寫錯誤、數據塊損壞
- 校驗和、原子寫
- 服務器故障:
- 運行時崩潰、重啟時崩潰
- 進程替換
- 通信故障:
- 延遲、丟失、重復、損壞
- 校驗和、可靠的 RPC 機制
- 無拜占庭故障
訪問由多個服務器管理的對象的事務被稱為分布式事務。當一個分布式事務結束時,所有參與該事務的服務器必須全部提交,或全部放棄。有一個服務器扮演協調者,由它來保證在所有的服務器(參與者)上獲得同一結果。協調者和參與者之間最常用的協議是兩階段提交協議(two-phase commit,2PC)。
有兩種分布式事務:
- 平面事務(flat transaction):每個事務等一個請求結束后才發起下一個請求,順序訪問各個服務器上的對象。
- 嵌套事務(nested transaction):每個事務包含若干子事務,同一層次的事物可以并發執行;如果它們訪問服務器上不同的對象,那么這些事務可以并行執行。

協調者提供Coordinator接口,有三個基本操作
- open Transaction,由客戶調用,返回事務標識(TID)
- close Transaction,由客戶調用,
- abort Transaction ,由協調者或參與者調用
Coordinator接口提供一個額外的方法 join(TID,reference to participant),該方法在一個新的參與者參加到事務中的時候使用
通知協調者,一個新的參與者已加入到事務 TID 中
協調者將新的參與者記錄到參與者列表中

當客戶啟動一個事務時,
- 客戶向協調者發送 open Transaction 請求
- 協調者返回 TID 給客戶
- 客戶直接發送 request 給參與者,并攜帶上 TID
- 參與者收到請求,調用 join 方法通知協調者,參與到該事務中
- 每個參與者記錄所有參與事務的可恢復對象(Recoverable objects)
- 事務結束后,協調者決定提交或者放棄事務
事務的原子特性要求,分布式事務結束時,它的所有操作要么全部成功,要么全部取消。
在一個分布式事務中,存在
客戶-協調者-參與者三方協調者、參與者之間僅有的通信是 join 請求
客戶請求了多個服務器上的操作,客戶請求協調者提交事務,協調者啟動提交協議
由協調者告訴所有參與者是提交或放棄:
- 協調者不斷地向所有參與者發送提交或放棄請求,
- 直到所有參與者確認已執行完相應操作。
存在問題:不允許任何服務器單方面放棄自己的事務,然而實際上每個服務器都可能會掛掉。
兩階段提交兩階段提交協議(2PC:Two-Phrase Commit),它允許任何一個服務器自行放棄屬于自己的事務。
故障模型:
- 異步通信系統,消息可能丟失、損壞、重復
- 服務器僅可能 crash,沒有隨機故障
- 繞過 FLP 不可能:crash 的進程被替換,新進程從持久存儲和其他進程中獲取故障前的信息
一些操作:
can Commit (trans)?
協調者詢問參與者,能否提交事務。參與者回復 Yes / No
do Commit (trans).
協調者通知參與者,讓其提交事務。參與者提交事務
do Abort (trans).
協調者通知參與者,讓其放棄事務。參與者放棄事務
have Committed (trans, participant).
參與者通知協調者,自己完成了提交。
get Decision (trans).
當參與者投票 Yes 一段時間后,未收到 do Commit 或者 do Abort 指令。那么就主動詢問協調者,事務最終的投票結果。
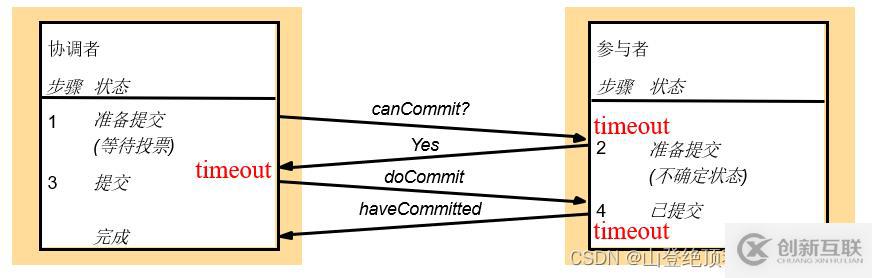
兩階段提交協議,
- 投票階段:
- 協調者發送 can Commit 給所有參與者,詢問它們是否可以提交(能否完成事務、是否完成事務)
- 參與者如果投票 Yes,那么進入 prepared 狀態(要在持久存儲中保存好事務的 update)
- 參與者如果投票 No,那么立即放棄事務,并 rollback 到事務之前的狀態(可恢復對象)
- 提交階段:
- 協調者收集所有的 votes,
- 如果全是 Yes,那么決定 commit,通知參與者提交事務
- 如果存在 No,或者出現故障,那么決定 abort,通知參與者放棄事務
- 投了 Yes 的參與者,等待協調者的決定(在持久存儲中記錄這個 decision)
- 如果是 do Commit,那么提交自己的事務,并向協調者發送 have Committed 確認完成提交
- 如果是 do Abort,那么就放棄事務,并 rollback 到事務之前的狀態
- 如果等候超時,那么向協調者發送 get Decision,獲取最終的決定
- 協調者收集所有的 votes,
三種超時情況:
- 投票階段,參與者完成事務之后,等待 can Commit 超時:單方面決定 abort 事務
- 提交階段,協調者等待 votes 超時:發送 do Abort 給參與者
- 提交階段,投票 Yes 的參與者處于“不確定”狀態,如果等待 decision 超時:不斷發送 get Decision 給協調者
- 由于可能出現任意多次的服務器或者通信故障,因此 2PC 僅保證最終完成,但沒有時間限制(期間阻塞參與者,阻塞期間可能出現數據不一致)
2PC 需要 N N N 個 can Commit 消息, N N N 個 Yes / No 應答, N N N 個 do Commit 消息,一共 3 3 3 輪通信 3 N 3N 3N 個消息的開銷(不包含 N N N 個 have Committed 以及若干 g e t D e c i s i o n get Decision getDecision 消息)
2PC 的優化:
- One RM:只有一個資源管理器,退化為單階段提交,只需 3 3 3 輪通信(而非 4 4 4 輪)。
- Read-Only Trans:只讀事務,無論最終是提交還是放棄,都只需要釋放對象的讀鎖。一旦收到 can Commit,就可以釋放鎖,然后就用 prepared-read-only 回應協調者,告訴協調者后續不必發送 do Commit 或者 do Abort 決定。
- Presumed abort:推斷事務一定會放棄,可以直接不寫日志
- Cooperative Termination Protocol:協調終止協議,減少等待。每個參與者不僅知道協調者地址,還知道其他參與者的地址。參與者會保留 decision 一段時間。
三階段提交協議(2PC:Two-Phrase Commit),通過引入 pre-commit 階段,以及 timeout 策略,來減少整個集群的阻塞時間,提升系統性能。
第一階段:can - commit
協調者向各個參與者發送 can Commit,詢問是否可以執行事務操作,并等待回復。
各個參與者依據自身狀況回復一個預估值(此時不執行事務,輕量級),
- 如果預估自己能夠正常執行事務,那么就回應 Yes 投票,并進入 prepared 狀態
- 否則,回應 No 投票,立即放棄事務
第二階段:pre - commit
協調者根據第一階段的投票結果,采取相應操作:
- 所有的參與者都返回 Yes,發送 pre Commit 預備提交事務
- 一個或多個參與者返回 No,發送 do Abort 放棄事務
- 協調者等待超時,發送 do Abort 放棄事務
投票 Yes 的參與者根據收到的指令,采取相應操作:
- 收到 pre Commit,那么就執行事務,
- 如果完成了事務,發送 Yes 給協調者(但不要提交事務),并進入 pre-committed 狀態
- 如果執行事務失敗,就發送 No 給協調者,放棄事務
- 收到 do Abort,那么放棄事務,rollback
- 如果超時,那么放棄事務,rollback
- 收到 pre Commit,那么就執行事務,
第三階段:do - commit
協調者根據第二階段的參與者執行情況,采取相應操作:
- 所有的參與者都返回 Yes,發送 do Commit 提交事務
- 一個或多個參與者返回 No,發送 do Abort 放棄事務
- 協調者等待超時,發送 do Abort 放棄事務
投票 Yes 的參與者根據收到的指令,采取相應操作:
- 收到 do Commit,那么提交事務
- 收到 do Abort,那么放棄事務,rollback
- 如果超時,那么默認提交事務(消除了無限期的阻塞,但這可能會導致數據不一致)
分布式系統的每個服務器上,都管理著很多的對象,它們負責保證并發事務訪問這些對象時保持一致性。
- 每個服務器負責對自己的對象應用并發控制機制
- 分布式事務中所有服務器共同保證事務以串性等價方式執行
- 可能的問題:
- 更新丟失,兩個事務同時讀取了舊值( a ′ : = a + 1 , a ′ : = a + 2 a':=a+1,a':=a+2 a′:=a+1,a′:=a+2),導致其中一個事務的 update 被覆蓋( a ′ ≠ a + 3 a' \neq a+3 a′=a+3)
- 不一致檢索,一個檢索事務觀察了多個正在更新的值( a ′ : = a ? 1 , b ′ : = b + 1 a':=a-1,b':=b+1 a′:=a?1,b′:=b+1),導致檢索結果與實際不一致( a + b ≠ a ′ + b ′ a+b \neq a'+b' a+b=a′+b′)
串行等價性:
- 條件一:某個事務對于一個對象所有的訪問,相對于其他事務的訪問,是串行化的(一個事務中對同一對象的多次訪問,都位于一個連續的臨界區內)
- 條件二:兩個事務所有的沖突操作對(讀寫沖突、寫寫沖突),必須以相同的次序執行訪問(只要事務 T T T 的對于一個對象的沖突訪問在事務 U U U 之前,那么對于其他對象的沖突訪問都是同樣的因果序)
串行等價的交錯執行:并發事務交錯執行各個操作,它的綜合效果與按某種次序,一次只執行一個事務的效果一樣(讀操作返回相同的值;事務結束時,所有對象的實例變量也具有相同的值)。
- 可以解決更新丟失的問題:

- 可以解決不一致檢索的問題:

通過加鎖來實現并發控制,達到串行等價性:
- 加鎖,串行化對象的訪問(條件一)。事務把一個對象的所有訪問,全都包含在同一個臨界區內(一個對象只能加一次鎖)
- 兩階段鎖,確保沖突操作對的執行次序相同(條件二)。事務釋放了任意一個鎖之后,不允許申請任何新的鎖(鎖增長階段、鎖收縮階段)
- 嚴格兩階段鎖,防止臟數據讀取和過早寫入問題。事務獲取到的鎖,必須在決定 commit 或者 abort 之后,才可以釋放(減小粒度,降低影響范圍)
服務器上某個對象的鎖,由本地鎖管理器持有,
- 每當有事務請求訪問對象時,鎖管理器就對這個對象嘗試加鎖。如果加鎖失敗,那么需要等待前一個事務解鎖
- 如果多個事務訪問各個對象的加鎖次序不同(事務
T
T
T 先訪問
a
a
a 后訪問
b
b
b,事務
U
U
U 先訪問
b
b
b 后訪問
a
a
a),這可能會導致事務之間的循環依賴,導致死鎖
- 單服務器死鎖:要么避免死鎖發生,要么檢測(鎖超時、等待圖)并解除死鎖
- 分布式死鎖:多個服務器中的對象訪問相互等待,在局部等待圖中可能無法發現環路,必須構造出全局等待圖
思路:
- 每個鎖都設定時間期限。一旦超時,那么鎖就變成可剝奪的。
- 如果沒有事務在等待此對象,那么原本的事務依舊鎖住這個對象
- 如果有其他事務正在等待這個對象,那么這個對象被解鎖后交給等待事務,而被剝奪的事務將被放棄
問題:
- 沒有死鎖的系統,事務依舊可能因為鎖超時被剝奪,從而被放棄
- 當系統過載時,長時間運行的事務將被經常性放棄
- 恰當的超時時間長度難以確定
對于服務器 X , Y , Z X,Y,Z X,Y,Z 上的對象 A ; B ; C , D A;B;C,D A;B;C,D,交錯執行的事務 U , V , W U,V,W U,V,W 有如下等待關系:

對應的全局等待圖為:

為了找到全局環,需要服務器之間進行通信。
- 集中式的死鎖檢測:
- 一個服務器擔任全局死鎖檢測器,收集、合并各個服務器上的局部等待圖
- 其他服務器不定期地發送局部等待圖給死鎖檢測器
- 死鎖檢測器一旦在全局等待圖中發現死鎖環,那么就決定放棄某一個事務,通知其他服務器
- 問題:
- 可用性差、缺乏容錯、無伸縮性
- 假死鎖:收集到的局部等待圖是老舊的,全局等待圖中有環,但是有些事務已經放棄了某些鎖,實際上不存在死鎖
- 分布式的死鎖檢測:可伸縮、可容錯
不需要構造全局等待圖,而是在服務器之間轉發 probe(探詢)消息,
- 事務的協調者,記錄這個事務是活動的還是在等待某個對象
- 事務的參與者的本地鎖服務器,通知協調者這個事務開始或停止等待
- 當某個事務被放棄時,它的協調者通知所有參與者放棄事務,并釋放相關的鎖
- 發送規則:當事務依賴關系為 T 1 → T 2 T_1 \to T_2 T1?→T2?,并且 T 2 T_2 T2? 一直在等待其他事務,那么服務器發送 probe 消息

邊追逐算法,
- 算法啟動:
- 當服務器 A A A 發現事務 T T T 等待事務 U U U,并且被阻塞的 U U U 在等待服務器 B B B 上的對象,那么 A A A 發送一個形如 ( T → U ) (T \to U) (T→U) 的探詢消息給 B B B,啟動一次死鎖檢查
- 實際上,服務器發送 probe 給協調者,由協調者轉發 probe 給下一個服務器,共需要 2 2 2 個消息
- 如果事務 U U U 和其他事務 V V V 共享鎖,那么將探詢消息轉發給這些鎖的擁有者
- 死鎖檢測:
- 當服務器 B B B 收到了 ( T → U ) (T \to U) (T→U) 消息,檢查事務 U U U 是否在等待其他事務
- 如果 U → V U \to V U→V,那么它就增加新邊,把形如 ( T → U → V ) (T \to U \to V) (T→U→V) 的探詢消息,繼續發送到 V V V 等待的服務器 C C C 上
- 每當服務器在 probe 上增加一條新邊,檢查是否存在環路(對于 N N N 個事務組成的環路,需要 2 ( N ? 1 ) 2(N-1) 2(N?1) 個消息)
- 死鎖解除:
- 當檢測到環路,其中的某個事務將被放棄(可能多個服務器同時發現同一個死鎖環)
- 設定事務的優先級,將環路中的最低優先級的事務放棄(避免同時放棄多個事務)
- 向下傳遞:讓 probe 消息只能從高優先級的事務傳遞到低優先級的事務上(減少通信量)
如果事務取消,那么服務器必須保證其他并發事務無法看到被取消事務的影響
- 臟數據讀取(dirty read):一個被放棄的事務對某個對象先執行了寫操作,之后另一個被提交的事務對這個對象執行了讀操作。

如圖,事務 U U U 讀取了事務 T T T 未提交的臟數據,這個臟數據會影響 U U U 的執行結果(比如發送 130 130 130 給客戶),而已經提交的事務不能被取消(Undo)。
- 過早寫入(premature writes):不同的事務對同一個對象執行寫操作,其中一個寫操作被放棄。

如圖,兩個事務 U , T U,T U,T 同時對于對象 a a a 執行寫操作,當 U U U 被提交后 T T T 再被放棄,對象 a a a 將被恢復為最初的狀態(前映像,before images),從而 U U U 提交的寫操作丟失。
- 事務的串行等價的交錯執行
- 對于同一對象的讀寫操作,就如同兩個事務串行執行執行一樣,但不要求提交或放棄
- 只能保證兩個事務都提交時的隔離特性
- 事務的嚴格執行,
- 對于一個對象的讀寫操作,都必須推遲到對同一對象執行寫操作的其他事務提交或者放棄之后
- 可以真正保證事務的隔離特性
恢復管理器(Recovery Manager, RM)
- 對已提交事務,將對象保存在持久存儲中的恢復文件(日志、陰影版本)上
- 重新組織恢復文件,以提高恢復的性能
- 回收恢復文件中的存儲空間
- 處理介質故障,需要在獨立磁盤上對恢復文件做一個拷貝
- 服務器崩潰后,服務器上對象的恢復
- 2PC 的恢復
恢復文件的組織結構,
- 對象:某個對象的數值
- 事務狀態:
- 事務標識 TID
- 事務狀態(prepared, committed, aborted)
- 其他用于 2PC 的狀態
- 意圖列表:TID 以及一系列的意圖記錄
- 對象標識 UID
- 對象在恢復文件中的位置
意圖列表的作用,
- 對應每個事務,都記錄下它們修改的對象列表(值、引用)
- 當某個事務提交時,Server 根據意圖列表來確定受影響的對象,
- 將事務的臨時對象版本,替換為對象的提交版本
- 把對象的新值,寫入到服務器的恢復文件上
- 當某個事務放棄時,Server 刪除對應的所有臨時對象版本
- 在 2PC 中,一旦參與者進入 prepared 狀態,那么它的 RM 必須把意圖列表、對象的臨時版本、事務狀態都寫入恢復文件
- 做檢查點的過程,是將下列信息寫到一個新的恢復文件
- 當前服務器上所有已提交的對象版本
- 事務的狀態記錄和尚未完全提交事務的意圖列表
- 還包括與 2PC 有關的信息
- 更換恢復文件的過程
- 在舊的恢復文件中增加一個標記
- 進行上述寫動作到一個新的恢復文件,然后將那個標記以后的項,拷貝到這個新的恢復文件
- 用新的恢復文件替換舊的恢復文件
- 檢查點的目的是,使得恢復更快和回收文件空間,要時不時做一下
日志是恢復文件的一種具體形式,記錄了服務器上執行的所有操作的歷史
- 最近檢查點的快照 + 快照之后的事務操作歷史
- 操作歷史:對象值、事務狀態、意圖列表
- 日志中的次序,反映了各個事務進入 prepared / committed / aborted 狀態的次序
每當事務準備好、提交、放棄時,Server 就調用自己的 RM,
- 當某事務 prepare,就讓 RM 把意圖列表中的對象,都 append 到日志中;同時,事務的 prepared 狀態以及它的意圖列表也被寫入
- 當某事物 commit 或者 abort,就讓 RM 把對應的 committed / aborted 狀態寫入日志
- 日志的寫操作(append),
- 假定是原子的:如果 crash,那么只有最后一次的 append 可能是不完整的
- 把多次寫緩沖起來,順序寫盤比隨機寫盤快得多

當服務器進程因崩潰而被替換后,新的進程執行:
- 首先將對象置為缺省的初始值,然后將控制轉給恢復管理器
- RM 的任務是恢復所有對象的值(使這些值反映所有已提交事務的效果,不包含任何未完成或放棄事務的效果)
- 通過逆向讀取日志文件來恢復對象值(如果從日志的開始進行恢復,通常要做更多的工作)
- 使用具有 committed 狀態的事務來恢復對象的值
- 這個過程一直進行到所有的對象都被恢復
- 為了恢復已提交事務的更新,RM 從日志文件的意圖列表中找對象的值
- 恢復過程必須是冪等的
- 通過逆向讀取日志文件來恢復對象值(如果從日志的開始進行恢復,通常要做更多的工作)
恢復管理器會用到兩個事務狀態:“完成” 和 “不確定”
- 參與者用 “不確定” 狀態,表示它的投票是 Yes,但尚未收到事務的提交決議
- 協調者用 “已提交” 狀態,來標記投票的結果是 Yes
- 參與者用 “已提交” 狀態,表示已通知投票結果
- 協調者用 “完成” 狀態,表示兩階段提交協議已經完成
此外,恢復文件還要增加兩類信息
- 協調者:事務標識,參與者列表
- 參與組合:事務標識,協調者

參與者:
- 在投票 Yes 之前,必須進入 prepared 狀態,在恢復文件中添加 “準備好” 狀態
- 在投票 Yes 時,在恢復文件中添加 “參與者” 記錄,并寫入 “不確定” 狀態
- 在投票 No 時,在恢復文件中寫入 “已放棄” 狀態
協調者:
- 第一階段準備提交時,在恢復文件中添加 “協調者” 記錄
- 第二階段做出決定后,在恢復文件中添加 “已提交” 或者 “已放棄” 狀態(一次性強制寫入)
- 協調者收到所有的 ack 消息后,在恢復文件中寫入 “完成” 狀態
在恢復文件中最新的事務狀態信息決定了故障時的事務狀態,RM 需要根據 Server 是協調者或參與者以及狀態的不同,進行事務恢復。如圖所示:

你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
本文標題:分布式系統(事務處理)-創新互聯
文章地址:http://vcdvsql.cn/article14/cdidge.html
成都網站建設公司_創新互聯,為您提供域名注冊、微信小程序、虛擬主機、網站制作、響應式網站、網站內鏈
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯
- 檢索對于網站設計多重要? 2021-05-22
- 如何才能做好品牌網站設計與建設 2023-03-19
- 深圳網站設計行業板塊越來越生動形象 2022-06-10
- 北京網站設計制作分析:網站建設需要注意的常見的幾大問題? 2021-04-29
- 網站要快從網站設計角度看怎樣去做呢 2023-02-14
- 一個備受歡迎的成都網站設計是怎樣的? 2022-12-19
- 網站設計制作的5大原則 2022-05-06
- 游戲網站設計的五個標準 2022-05-02
- 成都學校網站設計 2022-08-03
- 洛陽網站設計開發:設計一個網站該從何下手? 2021-09-03
- 如何做網站設計提高友好度? 2022-12-24
- 網站設計頁面的色彩搭配 2022-04-28