怎么用Python來分析紅樓夢里的人物關系-創新互聯
這篇文章主要介紹了怎么用Python來分析紅樓夢里的人物關系,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
創新互聯服務項目包括興慶網站建設、興慶網站制作、興慶網頁制作以及興慶網絡營銷策劃等。多年來,我們專注于互聯網行業,利用自身積累的技術優勢、行業經驗、深度合作伙伴關系等,向廣大中小型企業、政府機構等提供互聯網行業的解決方案,興慶網站推廣取得了明顯的社會效益與經濟效益。目前,我們服務的客戶以成都為中心已經輻射到興慶省份的部分城市,未來相信會繼續擴大服務區域并繼續獲得客戶的支持與信任!數據準備
紅樓夢 TXT 文件一份
金陵十二釵 + 賈寶玉 人物名稱列表
人物列表內容如下:
寶玉 nr 黛玉 nr 寶釵 nr 湘云 nr 鳳姐 nr 李紈 nr 元春 nr 迎春 nr 探春 nr 惜春 nr 妙玉 nr 巧姐 nr 秦氏 nr
這份列表,同時也是為了做分詞時使用,后面的 nr 就是人名的意思。
數據處理
讀取數據并加載詞典
with open("紅樓夢.txt", encoding='gb18030') as f:
honglou = f.readlines()
jieba.load_userdict("renwu_forcut")
renwu_data = pd.read_csv("renwu_forcut", header=-1)
mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]這樣,我們就把紅樓夢讀取到了 honglou 這個變量當中,同時也通過 load_userdict 將我們自定義的詞典加載到了 jieba 庫中。
對文本進行分詞處理并提取
tmpNames = []
names = {}
relationships = {}
for h in honglou:
h.replace("賈妃", "元春")
h.replace("李宮裁", "李紈")
poss = pseg.cut(h)
tmpNames.append([])
for w in poss:
if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist:
continue
tmpNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1首先,因為文中"賈妃", "元春","李宮裁", "李紈" 混用嚴重,所以這里直接做替換處理。
然后使用 jieba 庫提供的 pseg 工具來做分詞處理,會返回每個分詞的詞性。
之后做判斷,只有符合要求且在我們提供的字典列表里的分詞,才會保留。
一個人每出現一次,就會增加一,方便后面畫關系圖時,人物 node 大小的確定。
對于存在于我們自定義詞典的人名,保存到一個臨時變量當中 tmpNames。
處理人物關系
for name in tmpNames: for name1 in name: for name2 in name: if name1 == name2: continue if relationships[name1].get(name2) is None: relationships[name1][name2] = 1 else: relationships[name1][name2] += 1
對于出現在同一個段落中的人物,我們認為他們是關系緊密的,每同時出現一次,關系增加1.
保存到文件
with open("relationship.csv", "w", encoding='utf-8') as f:
f.write("Source,Target,Weight\n")
for name, edges in relationships.items():
for v, w in edges.items():
f.write(name + "," + v + "," + str(w) + "\n")
with open("NameNode.csv", "w", encoding='utf-8') as f:
f.write("ID,Label,Weight\n")
for name, times in names.items():
f.write(name + "," + name + "," + str(times) + "\n")文件1:人物關系表,包含首先出現的人物、之后出現的人物和一同出現次數
文件2:人物比重表,包含該人物總體出現次數,出現次數越多,認為所占比重越大。
制作關系圖表
使用 pyecharts 作圖
def deal_graph():
relationship_data = pd.read_csv('relationship.csv')
namenode_data = pd.read_csv('NameNode.csv')
relationship_data_list = relationship_data.values.tolist()
namenode_data_list = namenode_data.values.tolist()
nodes = []
for node in namenode_data_list:
if node[0] == "寶玉":
node[2] = node[2]/3
nodes.append({"name": node[0], "symbolSize": node[2]/30})
links = []
for link in relationship_data_list:
links.append({"source": link[0], "target": link[1], "value": link[2]})
g = (
Graph()
.add("", nodes, links, repulsion=8000)
.set_global_opts(title_opts=opts.TitleOpts(title="紅樓人物關系"))
)
return g首先把兩個文件讀取成列表形式
對于“寶玉”,由于其占比過大,如果統一進行縮放,會導致其他人物的 node 過小,展示不美觀,所以這里先做了一次縮放
最后得出的關系圖
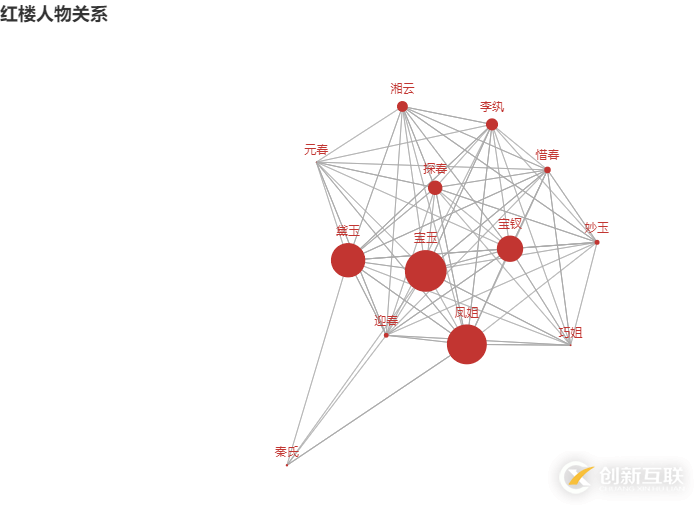
所有代碼已經上傳至 Github
最后,我還準備了一份更加全面的紅樓人物字典,可以在代碼倉庫中找到-“renwu_total”,感興趣的小伙伴也可以嘗試下,制作一個全人物的關系圖。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“怎么用Python來分析紅樓夢里的人物關系”這篇文章對大家有幫助,同時也希望大家多多支持創新互聯成都網站設計公司,關注創新互聯成都網站設計公司行業資訊頻道,更多相關知識等著你來學習!
另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、網站設計器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
分享文章:怎么用Python來分析紅樓夢里的人物關系-創新互聯
新聞來源:http://vcdvsql.cn/article16/cescdg.html
成都網站建設公司_創新互聯,為您提供關鍵詞優化、微信小程序、App設計、企業網站制作、網站排名、小程序開發
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 面對客戶提出的一些不合理的要求 專業的建站公司會這樣去做 2022-05-22
- 深圳建站公司創新互聯:一文看懂營銷型網站建設 2021-04-30
- 怎樣辨別成都建站公司好壞? 2022-06-03
- 專業的成都建站公司設計出各種網站 2013-11-19
- 怎樣找到一家靠譜的建站公司? 2016-09-16
- 為什么需要創新互聯建站公司為你做網站。 2019-07-21
- 為什么要選擇成都建站公司? 2023-02-09
- 不同的建站公司為何給出的網站制作價格不一樣呢? 2022-07-16
- 企業建站應該如何挑選網站建站公司 2021-02-14
- 網站建設制作高端定制網站大概多少錢為什么有些建站公司報價這么便宜 2021-12-07
- 不同的營銷型網站建站公司報價為何不一樣? 2022-08-05
- 深圳建站公司談交換鏈接中的小花招 2022-05-28