SQL中如何連接JOIN表
本篇文章給大家分享的是有關(guān)SQL中如何連接JOIN表,小編覺(jué)得挺實(shí)用的,因此分享給大家學(xué)習(xí),希望大家閱讀完這篇文章后可以有所收獲,話不多說(shuō),跟著小編一起來(lái)看看吧。
創(chuàng)新互聯(lián)是一家集網(wǎng)站建設(shè),碌曲企業(yè)網(wǎng)站建設(shè),碌曲品牌網(wǎng)站建設(shè),網(wǎng)站定制,碌曲網(wǎng)站建設(shè)報(bào)價(jià),網(wǎng)絡(luò)營(yíng)銷,網(wǎng)絡(luò)優(yōu)化,碌曲網(wǎng)站推廣為一體的創(chuàng)新建站企業(yè),幫助傳統(tǒng)企業(yè)提升企業(yè)形象加強(qiáng)企業(yè)競(jìng)爭(zhēng)力。可充分滿足這一群體相比中小企業(yè)更為豐富、高端、多元的互聯(lián)網(wǎng)需求。同時(shí)我們時(shí)刻保持專業(yè)、時(shí)尚、前沿,時(shí)刻以成就客戶成長(zhǎng)自我,堅(jiān)持不斷學(xué)習(xí)、思考、沉淀、凈化自己,讓我們?yōu)楦嗟钠髽I(yè)打造出實(shí)用型網(wǎng)站。
CROSS JOIN(交叉連接)
最基本的JOIN操作是真正的笛卡爾乘積。它只是組合一個(gè)表中的每一行和另一個(gè)表中的每一行。維基百科通過(guò)一副卡片給出了笛卡爾乘積的***例子,交叉連接ranks表和suits表:

在現(xiàn)實(shí)世界的場(chǎng)景中,CROSS JOIN在執(zhí)行報(bào)告時(shí)非常有用,例如,你可以生成一組日期(例如一個(gè)月的天數(shù))并與數(shù)據(jù)庫(kù)中的所有部門(mén)交叉連接,以創(chuàng)建完整的天/部門(mén)表。使用PostgreSQL語(yǔ)法:
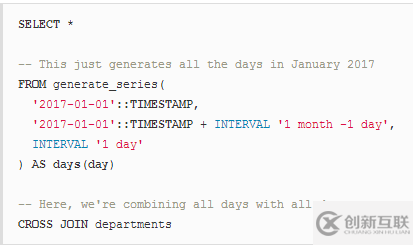
想象一下,我們有以下數(shù)據(jù):
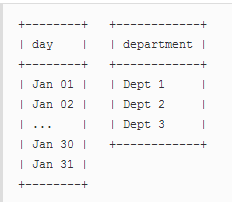
現(xiàn)在結(jié)果將如下所示:
+--------+------------+| day | department | +--------+------------+ | Jan 01 | Dept 1 || Jan 01 | Dept 2 | | Jan 01 | Dept 3 || Jan 02 | Dept 1 | | Jan 02 | Dept 2 || Jan 02 | Dept 3 | | ... | ... || Jan 31 | Dept 1 | | Jan 31 | Dept 2 || Jan 31 | Dept 3 | +--------+------------+
現(xiàn)在,在每個(gè)天/部門(mén)組合中,你可以計(jì)算該部門(mén)的每日收入,或其他。
特點(diǎn)
CROSS JOIN是笛卡爾乘積,即“乘法”中的乘積。數(shù)學(xué)符號(hào)使用乘號(hào)表示此操作:A×B,或在本文例子中:days×departments。
與“普通”算術(shù)乘法一樣,如果兩個(gè)表中有一個(gè)為空(大小為零),則結(jié)果也將為空(大小為零)。這是完全有道理的。如果我們將前面的31天與0個(gè)部門(mén)組合,我們將獲得0天/部門(mén)組合。同樣的,如果我們將空日期范圍與任何數(shù)量的部門(mén)組合,我們也會(huì)獲得0天/部門(mén)組合。
換一種說(shuō)法:
size(result) = size(days) * size(departments)
替代語(yǔ)法
以前,在ANSI JOIN語(yǔ)法被引入到SQL之前,大家就會(huì)在FROM子句中寫(xiě)以逗號(hào)分隔的表格列表來(lái)編寫(xiě)CROSS JOIN。上面的查詢等價(jià)于:
SELECT *FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day), departments
一般來(lái)說(shuō),我強(qiáng)烈建議使用CROSS JOIN關(guān)鍵字,而不是以逗號(hào)分隔的表格列表,因?yàn)槿绻阌幸獾叵胍獔?zhí)行CROSS JOIN,那么沒(méi)有什么可以比使用實(shí)際的關(guān)鍵字能更好地傳達(dá)這個(gè)意圖(對(duì)下一個(gè)開(kāi)發(fā)人員而言)。何況用逗號(hào)分隔的表格列表中有這么多地方都有可能會(huì)出錯(cuò)。你肯定不希望看到這樣的事情!
INNER JOIN(Theta-JOIN)
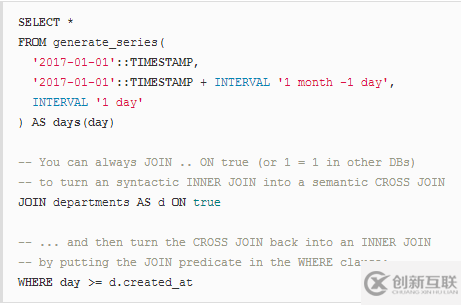
構(gòu)建在先前的CROSS JOIN操作之上,INNER JOIN(或者只是簡(jiǎn)單的JOIN,有時(shí)也稱為“THETA”JOIN)允許通過(guò)某些謂詞過(guò)濾笛卡爾乘積的結(jié)果。大多數(shù)時(shí)候,我們把這個(gè)謂詞放在ON子句中,它可能是這樣的:
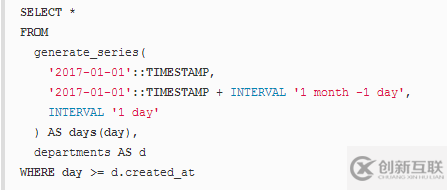
SELECT * -- Same as before FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) -- Now, exclude all days/departments combinations for -- days before the department was created JOIN departments AS d ON day >= d.created_at
在大多數(shù)數(shù)據(jù)庫(kù)中,INNER關(guān)鍵字是可選的,因此我在本文中略去了。
請(qǐng)注意INNER JOIN操作是如何允許在ON子句中放置任意謂詞的,這在執(zhí)行報(bào)告時(shí)也非常有用。就像在之前的CROSS JOIN示例中一樣,我們將所有日期與所有部門(mén)結(jié)合在一起,但是我們只保留那些部門(mén)已經(jīng)存在的天/部門(mén)組合,即部門(mén)創(chuàng)建在天之前。
再次,使用此數(shù)據(jù):
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | ... | | Dept 3 | Jan 12 | | Jan 30 | +------------+------------+ | Jan 31 | +--------+
現(xiàn)在結(jié)果將如下所示:
+--------+------------+ | day | department | +--------+------------+ | Jan 10 | Dept 1 | | Jan 11 | Dept 1 | | Jan 11 | Dept 2 | | Jan 12 | Dept 1 | | Jan 12 | Dept 2 | | Jan 12 | Dept 3 | | Jan 13 | Dept 1 | | Jan 13 | Dept 2 | | Jan 13 | Dept 3 | | ... | ... | | Jan 31 | Dept 1 | | Jan 31 | Dept 2 | | Jan 31 | Dept 3 | +--------+------------+
因此,我們?cè)?月10日之前沒(méi)有任何結(jié)果,因?yàn)檫@些行被過(guò)濾掉了。
特點(diǎn)
INNER JOIN操作是過(guò)濾后的CROSS JOIN操作。這意味著如果兩個(gè)表中有一個(gè)是空的,那么結(jié)果也保證為空。但是與CROSS JOIN不同的是,由于謂詞的存在,我們總能獲得比CROSS JOIN提供的更少的結(jié)果。
換一種說(shuō)法:
size(result) <= size(days) * size(departments)
替代語(yǔ)法
雖然ON子句對(duì)于INNER JOIN操作是強(qiáng)制的,但是你不需要在其中放置JOIN謂詞(雖然從可讀性角度強(qiáng)烈推薦)。大多數(shù)數(shù)據(jù)庫(kù)將以同樣的方式優(yōu)化以下等價(jià)查詢:
當(dāng)然,再次,那只是為讀者模糊了查詢,但你可能有你的理由,對(duì)吧?如果我們進(jìn)一步,那么下面的查詢也是等效的,因?yàn)榇蠖鄶?shù)優(yōu)化器可以指出等價(jià)物并轉(zhuǎn)而執(zhí)行INNER JOIN:
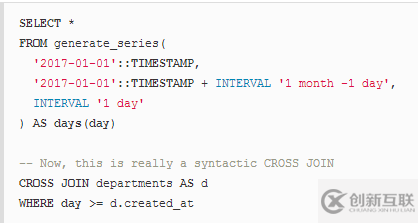
…并且,如前所述,CROSS JOIN只是用逗號(hào)分隔的表格列表的語(yǔ)法糖。在這種情況下,我們保留WHERE子句以獲得在引入ANSI JOIN語(yǔ)法之前人們經(jīng)常做的事情:
所有這些語(yǔ)法都了做同樣的事情,通常沒(méi)有性能損失,但顯然,它們比原始的INNER JOIN語(yǔ)法更不可讀。
EQUI JOIN
有時(shí),在著作中,你會(huì)聽(tīng)到EQUI JOIN這個(gè)術(shù)語(yǔ),其中“EQUI”不是SQL關(guān)鍵字,而只是作為一種特殊的INNER JOIN寫(xiě)法。
事實(shí)上,令人奇怪的是“EQUI”JOIN是特殊情況,因?yàn)槲覀冊(cè)赟QL中EQUI JOIN做得最多,并且在OLTP應(yīng)用程序中,我們只是通過(guò)主鍵/外鍵關(guān)系JOIN。例如:
SELECT *FROM actor AS aJOIN film_actor AS fa ON a.actor_id = fa.actor_idJOIN film AS f ON f.film_id = fa.film_id
上述查詢選擇了所有演員及其電影。有兩個(gè)INNER JOIN操作,一個(gè)將actors連接到film_actor關(guān)系表中的相應(yīng)條目(因?yàn)檠輪T可以演許多電影,而電影可以有許多演員出演),并且另一個(gè)連接每個(gè)film_actor與關(guān)于電影本身的附加信息的關(guān)系。
特點(diǎn)
該操作的特點(diǎn)與“一般的”INNER JOIN操作的特點(diǎn)相同。“EQUI”JOIN仍然結(jié)果集減少了的笛卡爾乘積(CROSS JOIN),即僅包含給定演員在給定電影中實(shí)際播放的那些演員/電影組合。
因此,換句話說(shuō):
size(result) <= size(actor) * size(film)
結(jié)果大小等于演員大小乘以電影大小,但是每個(gè)演員在每部電影中都出演是不太可能的。
替代語(yǔ)法:USING
再次,和前面一樣,我們可以寫(xiě)INNER JOIN操作,而不使用實(shí)際的INNER JOIN語(yǔ)法,而是使用CROSS JOIN或以逗號(hào)分隔的表格列表。這很無(wú)聊,但更有趣的是以下兩種替代語(yǔ)法,其中之一是非常有用的:
SELECT *FROM actorJOIN film_actor USING (actor_id)JOIN film USING (film_id)
USING子句替換ON子句,并允許列出必須在JOIN操作的兩側(cè)出現(xiàn)的一組列。如果你以與Sakila數(shù)據(jù)庫(kù)相同的方式仔細(xì)設(shè)計(jì)數(shù)據(jù)庫(kù),即每個(gè)外鍵列具有與它們引用的主鍵列相同的名稱(例如actor.actor_id = film_actor.actor_id),那么你至少可以在這些數(shù)據(jù)庫(kù)中使用USING 用于“EQUI”JOIN:
Derby
Firebird
HSQLDB
Ingres
MariaDB
MySQL
Oracle
PostgreSQL
SQLite
Vertica
不幸的是,這些數(shù)據(jù)庫(kù)不支持這個(gè)語(yǔ)法:
Access
Cubrid
DB2
H2
HANA
Informix
SQL Server
Sybase ASE
Sybase SQL Anywhere
雖然這產(chǎn)生的結(jié)果與ON子句完全相同(幾乎相同),但讀取和寫(xiě)入更快。我之所以“幾乎”是因?yàn)橐恍?shù)據(jù)庫(kù)(以及SQL標(biāo)準(zhǔn))指定,任何出現(xiàn)在USING子句中的列失去其限定。例如:
SELECT f.title, -- Ordinary column, can be qualified f.film_id, -- USING column, shouldn't be qualified film_id -- USING column, correct / non-ambiguous here FROM actor AS aJOIN film_actor AS fa USING (actor_id)JOIN film AS f USING (film_id)
另外,當(dāng)然,這種語(yǔ)法有點(diǎn)限制。有時(shí),你的表中有多個(gè)外鍵,但不是所有鍵都具有主鍵列名稱。例如:
CREATE TABLE film ( .. language_id BIGINT REFERENCES language, original_language_id BIGINT REFERENCES language, )
如果你想通過(guò)ORIGINAL_LANGUAGE_ID連接,則必須訴諸ON子句。
備選語(yǔ)法:NATURAL JOIN
“EQUI”JOIN的一個(gè)更極端和更少有用的形式是NATURAL JOIN子句。前面的例子可以通過(guò)NATURAL JOIN替換USING來(lái)進(jìn)一步“改進(jìn)”,像這樣:
SELECT *FROM actorNATURAL JOIN film_actorNATURAL JOIN film
請(qǐng)注意,我們不再需要指定任何JOIN標(biāo)準(zhǔn),因?yàn)镹ATURAL JOIN將自動(dòng)從它加入的兩個(gè)表中獲取所有共享相同名稱的列,并將它們放置在“隱藏”的USING子句中。正如我們前面所看到的,由于主鍵和外鍵具有相同的列名,這看起來(lái)很有用。
真相是:這是沒(méi)用的。在Sakila數(shù)據(jù)庫(kù)中,每個(gè)表還有一個(gè)LAST_UPDATE列,這是NATURAL JOIN會(huì)自動(dòng)考慮的。因此NATURAL JOIN查詢等價(jià)于:
SELECT *FROM actorJOIN film_actor USING (actor_id, last_update)JOIN film USING (film_id, last_update)
…這當(dāng)然完全沒(méi)有任何意義。所以,馬上將NATURAL JOIN拋之腦后吧(除了一些非常罕見(jiàn)的情況,例如當(dāng)連接Oracle的診斷視圖,如v$sql NATURAL JOIN v$sql_plan等,用于ad-hoc分析)
OUTER JOIN
我們之前已經(jīng)見(jiàn)識(shí)過(guò)INNER JOIN,它僅針對(duì)左/右表的組合返回結(jié)果,其中ON謂詞產(chǎn)生true。
OUTER JOIN允許我們保留rowson的左/ 右側(cè),因此我們就找不到匹配的組合。讓我們回到日期和部門(mén)的例子:
SELECT *FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) LEFT JOIN departments AS d ON day >= d.created_at
同樣,OUTER關(guān)鍵字是可選的,所以我在示例中省略了它。
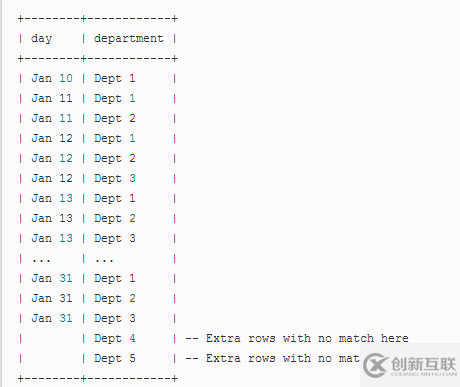
此查詢與INNER JOIN計(jì)數(shù)器部分有著非常微妙的不同,它每天總會(huì)返回至少一行,即使在給定的某一天沒(méi)有在該天創(chuàng)建的部門(mén)。例如:所有部門(mén)都在1月10日創(chuàng)建。上述查詢?nèi)詫⒎祷?月1日至9日:
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | ... | | Dept 3 | Jan 12 | | Jan 30 | +------------+------------+ | Jan 31 | +--------+
除了我們之前在INNER JOIN示例中獲得的行之外,我們現(xiàn)在還有從1月1日到9日的所有日期,其中包含NULL部門(mén):

換句話說(shuō),每一天在結(jié)果中至少出現(xiàn)一次。 LEFT JOIN對(duì)左表執(zhí)行此操作,即它保留結(jié)果中來(lái)自左表的所有行。
正式地說(shuō),LEFT OUTER JOIN是一個(gè)像這樣帶有UNION的INNER JOIN:

RIGHT OUTER JOIN正好相反。它保留結(jié)果中來(lái)自右表的所有行。讓我們添加更多部門(mén)
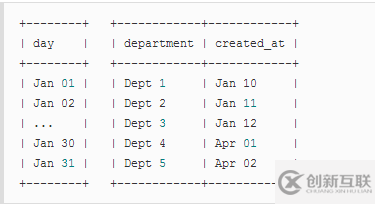
+--------+ +------------+------------+ | day | | department | created_at | +--------+ +------------+------------+ | Jan 01 | | Dept 1 | Jan 10 | | Jan 02 | | Dept 2 | Jan 11 | | ... | | Dept 3 | Jan 12 | | Jan 30 | | Dept 4 | Apr 01 | | Jan 31 | | Dept 5 | Apr 02 | +--------+ +------------+------------+
新的部門(mén)4和5將不會(huì)在以前的結(jié)果中,因?yàn)樗鼈兪窃?月31日之后的某一天創(chuàng)建的。但是它將顯示在右連接結(jié)果中,因?yàn)椴块T(mén)是連接操作的右表,并且來(lái)自右表中的所有行都將被保留。運(yùn)行此查詢:
SELECT *FROM generate_series( '2017-01-01'::TIMESTAMP, '2017-01-01'::TIMESTAMP + INTERVAL '1 month -1 day', INTERVAL '1 day' ) AS days(day) RIGHT JOIN departments AS d ON day >= d.created_at
將產(chǎn)生:
在大多數(shù)情況下,每個(gè)LEFT OUTER JOIN表達(dá)式都可以轉(zhuǎn)換為等效的RIGHT OUTER JOIN表達(dá)式,反之亦然。因?yàn)镽IGHT OUTER JOIN通常不太可讀,大多數(shù)人只使用LEFT OUTER JOIN。
FULL OUTER JOIN
***,還有FULL OUTER JOIN,它保留JOIN操作兩側(cè)的所有行。在我們的示例中,這意味著每一天在結(jié)果中至少出現(xiàn)一次,就像每個(gè)部門(mén)在結(jié)果中至少出現(xiàn)一次一樣。
讓我們?cè)賮?lái)看一下這個(gè)數(shù)據(jù):
現(xiàn)在,讓我們運(yùn)行這個(gè)查詢:
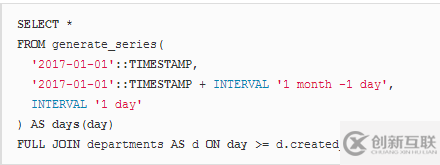
現(xiàn)在結(jié)果看起來(lái)像這樣:

如果你堅(jiān)持,正式地說(shuō)來(lái),LEFT OUTER JOIN是一個(gè)像這樣帶有UNION的INNER JION:

備選語(yǔ)法:“EQUI”O(jiān)UTER JOIN
上面的例子再次使用了某種“帶過(guò)濾器的笛卡爾積”JOIN。然而,更常見(jiàn)的是“EQUI”O(jiān)UTER JOIN方法,其中我們連接了主鍵/外鍵關(guān)系。讓我們回到Sakila數(shù)據(jù)庫(kù)示例。一些演員沒(méi)有在任何電影中出演,那么我們可能希望像這樣查詢:
SELECT * FROM actor LEFT JOIN film_actor USING (actor_id) LEFT JOIN film USING (film_id)
此查詢將返回所有actors至少一次,無(wú)論他們是否在電影中出演。如果我們還想要所有沒(méi)有演員的電影,那么我們可以使用FULL OUTER JOIN來(lái)組合結(jié)果:
SELECT * FROM actor FULL JOIN film_actor USING (actor_id) FULL JOIN film USING (film_id)
當(dāng)然,這也適用于NATURAL LEFT JOIN,NATURAL RIGHT JOIN,NATURAL FULL JOIN,但同樣的,這些都沒(méi)有用,因?yàn)槲覀儗⒃俅问褂肬SING(…,LAST_UPDATE),這使之完全沒(méi)有任何意義。
備選語(yǔ)法:Oracle和SQL Server style OUTER JOIN
這兩個(gè)數(shù)據(jù)庫(kù)在ANSI語(yǔ)法建立之前有OUTER JOIN。它看起來(lái)像這樣:
-- Oracle SELECT *FROM actor a, film_actor fa, film f WHERE a.actor_id = fa.actor_id(+)AND fa.film_id = f.film_id(+) -- SQL Server SELECT *FROM actor a, film_actor fa, film fWHERE a.actor_id *= fa.actor_id AND fa.film_id *= f.film_id
很好,假定某個(gè)時(shí)間點(diǎn)(在80年代??),ANSI沒(méi)有指定OUTER JOIN。但80年代是在30多年前,所以,可以安全地說(shuō)這個(gè)東西已經(jīng)過(guò)時(shí)了。
SQL Server做了正確的事情,很久以前就棄用(以及后面刪除)了語(yǔ)法。因?yàn)橄蚝蠹嫒菪缘脑颍琌racle仍然支持。
但是關(guān)于這種語(yǔ)法沒(méi)有什么是合理或可讀的。所以不要使用它。用ANSI JOIN替換。
PARTITIONED OUTER JOIN
這是Oracle特定的,但我必須說(shuō),這是一個(gè)真正的恥辱,因?yàn)闆](méi)有其他數(shù)據(jù)庫(kù)偷竊該功能。還記住我們用來(lái)將每一天與每個(gè)部門(mén)組合的CROSS JOIN操作?因?yàn)椋袝r(shí),這是我們想要的結(jié)果:所有的組合,并且如果有一個(gè)匹配的話也匹配行中的值。
這很難用文字描述,用例子講就容易多了。下面是使用Oracle語(yǔ)法的查詢:
WITH -- Using CONNECT BY to generate all dates in January days(day) AS ( SELECT DATE '2017-01-01' + LEVEL - 1 FROM dual CONNECT BY LEVEL <= 31 ), -- Our departments departments(department, created_at) AS ( SELECT 'Dept 1', DATE '2017-01-10' FROM dual UNION ALL SELECT 'Dept 2', DATE '2017-01-11' FROM dual UNION ALL SELECT 'Dept 3', DATE '2017-01-12' FROM dual UNION ALL SELECT 'Dept 4', DATE '2017-04-01' FROM dual UNION ALL SELECT 'Dept 5', DATE '2017-04-02' FROM dual ) SELECT * FROM days LEFT JOIN departments PARTITION BY (department) -- This is where the magic happens ON day >= created_at
不幸的是,PARTITION BY用在具有不同含義的各種上下文中(例如針對(duì)窗口函數(shù))。在這種情況下,這意味著我們通過(guò)departments.department列“partition”我們的數(shù)據(jù),為每個(gè)部門(mén)創(chuàng)建一個(gè)“partition”。現(xiàn)在,每個(gè)(partition)分區(qū)將獲得每一天的副本,無(wú)論在我們的謂詞中是否有匹配(不像在普通的LEFT JOIN情況下,我們有一堆“缺少部門(mén)”的日期)。上面的查詢結(jié)果現(xiàn)在是這樣的:
+--------+------------+------------+ | day | department | created_at | +--------+------------+------------+ | Jan 01 | Dept 1 | | -- Didn't match, but still get row | Jan 02 | Dept 1 | | -- Didn't match, but still get row | ... | Dept 1 | | -- Didn't match, but still get row | Jan 09 | Dept 1 | | -- Didn't match, but still get row | Jan 10 | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 11 | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 12 | Dept 1 | Jan 10 | -- Matches, so get join result | ... | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 31 | Dept 1 | Jan 10 | -- Matches, so get join result | Jan 01 | Dept 2 | | -- Didn't match, but still get row | Jan 02 | Dept 2 | | -- Didn't match, but still get row | ... | Dept 2 | | -- Didn't match, but still get row | Jan 09 | Dept 2 | | -- Didn't match, but still get row | Jan 10 | Dept 2 | | -- Didn't match, but still get row | Jan 11 | Dept 2 | Jan 11 | -- Matches, so get join result | Jan 12 | Dept 2 | Jan 11 | -- Matches, so get join result | ... | Dept 2 | Jan 11 | -- Matches, so get join result | Jan 31 | Dept 2 | Jan 11 | -- Matches, so get join result | Jan 01 | Dept 3 | | -- Didn't match, but still get row | Jan 02 | Dept 3 | | -- Didn't match, but still get row | ... | Dept 3 | | -- Didn't match, but still get row | Jan 09 | Dept 3 | | -- Didn't match, but still get row | Jan 10 | Dept 3 | | -- Didn't match, but still get row | Jan 11 | Dept 3 | | -- Didn't match, but still get row | Jan 12 | Dept 3 | Jan 12 | -- Matches, so get join result | ... | Dept 3 | Jan 12 | -- Matches, so get join result | Jan 31 | Dept 3 | Jan 12 | -- Matches, so get join result | Jan 01 | Dept 4 | | -- Didn't match, but still get row | Jan 02 | Dept 4 | | -- Didn't match, but still get row | ... | Dept 4 | | -- Didn't match, but still get row | Jan 31 | Dept 4 | | -- Didn't match, but still get row | Jan 01 | Dept 5 | | -- Didn't match, but still get row | Jan 02 | Dept 5 | | -- Didn't match, but still get row | ... | Dept 5 | | -- Didn't match, but still get row | Jan 31 | Dept 5 | | -- Didn't match, but still get row +--------+------------+
正如你所看到的,我已經(jīng)為5個(gè)部門(mén)創(chuàng)建了5個(gè)分區(qū)。每個(gè)分區(qū)通過(guò)每一天來(lái)組合部門(mén),但不像CROSS JOIN時(shí)做的那樣,我們現(xiàn)在實(shí)際得到的是LEFT JOIN .. ON ..結(jié)果,萬(wàn)一謂詞有匹配的話。這在Oracle報(bào)告中是一個(gè)非常好的功能!
SEMI JOIN
在關(guān)系代數(shù)中,存在半連接操作的概念,遺憾的是這在SQL中沒(méi)有語(yǔ)法表示。如果有語(yǔ)法的話,可能會(huì)是LEFT SEMI JOIN和RIGHT SEMI JOIN,就像Cloudera Impala語(yǔ)法擴(kuò)展提供的那樣。
什么是“SEMI” JOIN?
當(dāng)寫(xiě)下如下虛構(gòu)查詢時(shí):
SELECT * FROM actor LEFT SEMI JOIN film_actor USING (actor_id)
我們真正的意思是,我們想要電影中出演的所有演員。但我們不想在結(jié)果中出現(xiàn)任何電影,只要演員。更具體地說(shuō),我們不想讓每個(gè)演員出現(xiàn)多次,即一部電影出現(xiàn)一次。我們希望每個(gè)演員在結(jié)果中只出現(xiàn)一次(或零次)。
Semi在拉丁語(yǔ)中為“半”的意思,即我們只實(shí)現(xiàn)“半連接”,在這種情況下,即左半部分。
在SQL中,有兩個(gè)可以模擬“SEMI”JOIN的替代語(yǔ)法
備選語(yǔ)法:EXISTS
這是更強(qiáng)大和更冗長(zhǎng)的語(yǔ)法
SELECT * FROM actor a WHERE EXISTS ( SELECT * FROM film_actor fa WHERE a.actor_id = fa.actor_id )
我們正在尋找存在于一部電影的所有演員,即在電影中演出的演員。使用這種語(yǔ)法(即,“SEMI”JOIN被放置在WHERE子句中),很明顯我們可以在結(jié)果中最多得到每個(gè)演員一次。語(yǔ)法中沒(méi)有實(shí)際的JOIN。
盡管如此,大多數(shù)數(shù)據(jù)庫(kù)能夠識(shí)別這里真正發(fā)生的是“SEMI”JOIN,而不僅僅是一個(gè)普通的EXISTS()謂詞。例如,對(duì)上述查詢考慮Oracle執(zhí)行計(jì)劃:
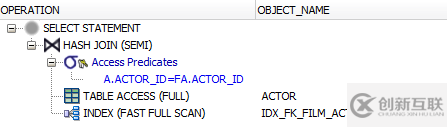
注意Oracle如何調(diào)用操作“HASH JOIN(SEMI)” ——此處存在SEMI關(guān)鍵字。 PostgreSQL也是這樣:
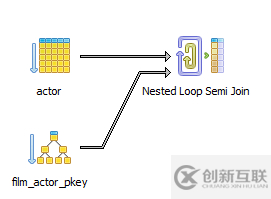
或SQL Server:
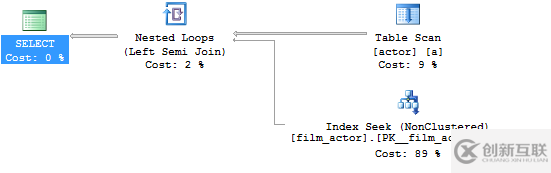
除了是正確的***解決方案,使用“SEMI”JOIN而不是INNER JOIN也有一些性能優(yōu)勢(shì),因?yàn)閿?shù)據(jù)庫(kù)可以在找到***個(gè)匹配后立即停止查找匹配項(xiàng)!
替代語(yǔ)法:IN
IN和EXISTS完全等同于“SEMI”JOIN模擬。以下查詢將在大多數(shù)數(shù)據(jù)庫(kù)(不是MySQL)中生成與先前EXISTS查詢相同的計(jì)劃:
SELECT *FROM actor WHERE actor_id IN ( SELECT actor_id FROM film_actor )
如果你的數(shù)據(jù)庫(kù)支持“SEMI”JOIN操作的兩種語(yǔ)法,你或許可以從文體的角度選擇你喜歡的。
這與下面的JOIN是不一樣的。
ANTI JOIN
原則上,“ANTI”JOIN正好與“SEMI”JOIN相反。當(dāng)寫(xiě)下如下虛構(gòu)查詢時(shí):
SELECT *FROM actor LEFT ANTI JOIN film_actor USING (actor_id)
…我們正在做的是找出所有沒(méi)有在任何電影中出演的演員。不幸的是,再次,SQL并沒(méi)有這個(gè)操作的內(nèi)置語(yǔ)法,但我們可以用EXISTS來(lái)模擬它:
替代語(yǔ)法:NOT EXISTS
以下查詢正好有預(yù)期的語(yǔ)義:
SELECT *FROM actor a WHERE NOT EXISTS ( SELECT * FROM film_actor fa WHERE a.actor_id = fa.actor_id )
(危險(xiǎn))替代語(yǔ)法:NOT IN
小心!雖然EXISTS和IN是等效的,但NOT EXISTS和NOT IN是不等效的。因?yàn)镹ULL值!
在這種特殊情況下,下面的NOT IN查詢等同于先前的NOT EXISTS查詢,因?yàn)槲覀兊膄ilm_actor表在film_actor.actor_id上有一個(gè)NOT NULL約束
SELECT *FROM actor WHERE actor_id NOT IN ( SELECT actor_id FROM film_actor )
然而,如果actor_id變?yōu)榭煽眨敲床樵儗⑹清e(cuò)誤的。不相信嗎?嘗試運(yùn)行:
SELECT *FROM actorWHERE actor_id NOT IN (1, 2, NULL)
它不會(huì)返回任何記錄。為什么?因?yàn)镹ULL在SQL中是UNKNOWN值。所以,上面的謂詞如下是一樣的:
SELECT *FROM actor WHERE actor_id NOT IN (1, 2, UNKNOWN)
并且因?yàn)槲覀儾荒艽_定actor_id是否在一個(gè)值為UNKNOWN(是4?還是5?抑或-1?)的一組值中,因此整個(gè)謂詞變?yōu)閁NKNOWN
SELECT *FROM actorWHERE UNKNOWN
如果你想了解更多,這里有一篇Joe Celko寫(xiě)的關(guān)于三值邏輯的好文章。
當(dāng)然,這樣還不夠:
不要在SQL中使用NOT IN謂詞,除非你添加常量,非空值。
——Lukas Eder。現(xiàn)在。
甚至不要在存在NOT NULL約束時(shí)進(jìn)行冒險(xiǎn)。也許,一些DBA可能暫時(shí)關(guān)閉約束來(lái)加載一些數(shù)據(jù),但是你的查詢當(dāng)下卻會(huì)是錯(cuò)的。只使用NOT EXISTS。或者,在某些情況下…
(危險(xiǎn))替代語(yǔ)法:LEFT JOIN / IS NULL
奇怪的是,有些人喜歡以下語(yǔ)法:
SELECT *FROM actor aLEFT JOIN film_actor faUSING (actor_id)WHERE film_id IS NULL
這是正確的,因?yàn)槲覀儯?/p>
連接電影加到演員
保留所有演員而不保留電影(LEFT JOIN)
保留沒(méi)有出演電影的演員(film_id IS NULL)
好吧,我個(gè)人不怎么喜歡這種語(yǔ)法,因?yàn)樗稽c(diǎn)也沒(méi)有傳達(dá)“ANTI”JOIN的意圖。而且有可能會(huì)很慢,因?yàn)槟愕膬?yōu)化器不認(rèn)為這是一個(gè)“ANTI”JOIN操作(或者事實(shí)上,它不能正式證明它可能是)。所以,再次,使用NOT EXISTS代替。
一個(gè)有趣的(但有點(diǎn)過(guò)時(shí))博客文章比較了這三個(gè)語(yǔ)法:
https://explainextended.com/2009/09/15/not-in-vs-not-exists-vs-left-join-is-null-sql-server
LATERAL JOIN
LATERAL是SQL標(biāo)準(zhǔn)中相對(duì)較新的關(guān)鍵字,并且它得到了PostgreSQL和Oracle的支持。SQL Server人員有一個(gè)特定于供應(yīng)商的替代語(yǔ)法,總是使用APPLY關(guān)鍵字(這個(gè)我個(gè)人更喜歡)。讓我們看一個(gè)使用PostgreSQL / Oracle LATERAL關(guān)鍵字的例子:

事實(shí)上,與其在所有部門(mén)和所有日子之間進(jìn)行CROSS JOIN,為什么不直接為每個(gè)部門(mén)生成必要的日期?這就是LATERAL的作用。它是任何JOIN操作(包括INNER JOIN,LEFT OUTER JOIN等)右側(cè)的前綴,允許右側(cè)從左側(cè)訪問(wèn)列。
這當(dāng)然與關(guān)系代數(shù)不再有關(guān),因?yàn)樗鼜?qiáng)加了一個(gè)JOIN順序(從左到右)。有時(shí),這是OK的,有時(shí),你的表值函數(shù)(或子查詢)是如此復(fù)雜,于是那通常是你可以實(shí)際使用它的唯一方法。
另一個(gè)非常受歡迎的用例是將“TOP-N”查詢連接到常規(guī)表中。 如果你想找到每個(gè)演員,以及他們最暢銷的TOP 5電影:
SELECT a.first_name, a.last_name, f. *FROM actor AS a LEFT OUTER JOIN LATERAL ( SELECT f.title, SUM(amount) AS revenue FROM film AS f JOIN film_actor AS fa USING (film_id) JOIN inventory AS i USING (film_id) JOIN rental AS r USING (inventory_id) JOIN payment AS p USING (rental_id) WHERE fa.actor_id = a.actor_id GROUP BY f.film_id ORDER BY revenue DESC LIMIT 5) AS fON true
結(jié)果可能會(huì)是:
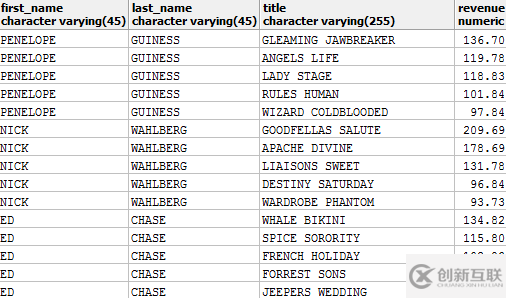
不要擔(dān)心派生表中一長(zhǎng)串的連接,這就是我們?nèi)绾卧赟akila數(shù)據(jù)庫(kù)中從FILM表到PAYMENT表獲取的原理:
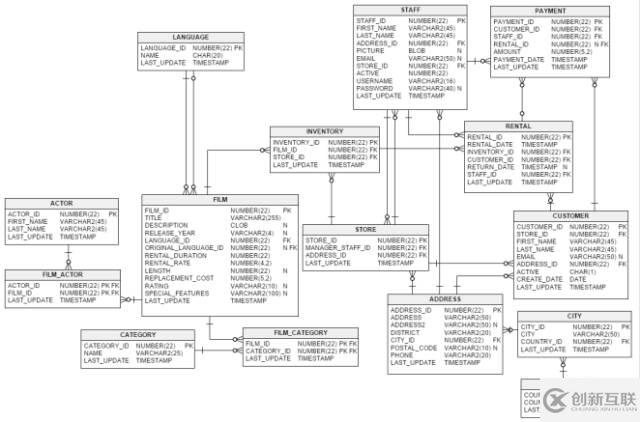
基本上,子查詢計(jì)算每個(gè)演員最暢銷的TOP 5電影。 因此,它不是“經(jīng)典的”派生表,而是返回多個(gè)行和一列的相關(guān)子查詢。 我們都習(xí)慣于寫(xiě)這樣的相關(guān)子查詢:
SELECT a.first_name, a.last_name, (SELECT count(*) FROM film_actor AS fa WHERE fa.actor_id = a.actor_id) AS films FROM actor AS a
特點(diǎn):
LATERAL關(guān)鍵字并沒(méi)有真正改變被應(yīng)用的JOIN類型的語(yǔ)義。如果你運(yùn)行CROSS JOIN LATERAL,結(jié)果大小仍然是
size(result) = size(left table) * size(right table)
即使右表是在左列表每行的基礎(chǔ)上產(chǎn)生的。
你也可以使用OUTER JOIN來(lái)使用LATERAL,即使你的表函數(shù)不返回右側(cè)的任何行,這樣的情況下,左側(cè)的行也將被保留。
替代語(yǔ)法:APPLY
SQL Server沒(méi)有選擇混亂的LATERAL關(guān)鍵字,它們很久以前就引入了APPLY關(guān)鍵字(更具體地說(shuō):CROSS APPLY和OUTER APPLY),這更有意義,因?yàn)槲覀儗?duì)表的每一行應(yīng)用一個(gè)函數(shù)。讓我們假設(shè)我們?cè)赟QL Server中有一個(gè)generate_series()函數(shù):
-- Use with care, this is quite inefficient! CREATE FUNCTION generate_series(@d1 DATE, @d2 DATE) RETURNS TABLE ASRETURN WITH t(d) AS ( SELECT @d1 UNION ALL SELECT DATEADD(day, 1, d) FROM t WHERE d < @d2 ) SELECT * FROM t;
然后,我們可以使用CROSS APPLY為每個(gè)部門(mén)調(diào)用函數(shù):
WITH departments AS ( SELECT * FROM ( VALUES ('Dept 1', CAST('2017-01-10' AS DATE)), ('Dept 2', CAST('2017-01-11' AS DATE)), ('Dept 3', CAST('2017-01-12' AS DATE)), ('Dept 4', CAST('2017-04-01' AS DATE)), ('Dept 5', CAST('2017-04-02' AS DATE)) ) d(department, created_at) ) SELECT * FROM departments AS d CROSS APPLY dbo.generate_series( d.created_at, -- We can dereference a column from department! CAST('2017-01-31' AS DATE) )這個(gè)語(yǔ)法的好處是——再次——我們對(duì)表的每一行應(yīng)用一個(gè)函數(shù),并且該函數(shù)產(chǎn)生行。聽(tīng)起來(lái)耳熟?在Java 8中,我們將對(duì)此使用Stream.flatMap()!考慮以下流的使用:
departments.stream() .flatMap(department -> generateSeries( department.createdAt, LocalDate.parse("2017-01-31")) .map(day -> tuple(department, day)) );這里發(fā)生了什么?
DEPARTMENTS表只是一個(gè)Java部門(mén)流
我們使用一個(gè)為每個(gè)部門(mén)生成元組的函數(shù)來(lái)映射department流
這些元組包括部門(mén)本身,以及從部門(mén)CreatedAt日期開(kāi)始的一系列日期中生成的一天
同樣的故事! SQL CROSS APPLY / CROSS JOIN LATERAL與Java的Stream.flatMap()是一樣的。事實(shí)上,SQL和流并不是太不同。有關(guān)更多信息,請(qǐng)閱讀此博客文章。
注意:就像我們可以編寫(xiě)LEFT OUTER JOIN LATERAL一樣,我們還可以編寫(xiě)OUTER APPLY,以便保留JOIN表達(dá)式的左側(cè)。
MULTISET
很少數(shù)據(jù)庫(kù)實(shí)現(xiàn)這個(gè)(實(shí)際上,只有Oracle),但如果你思考它的話,它真的是一個(gè)超棒的JOIN類型。創(chuàng)建了嵌套集合。如果所有數(shù)據(jù)庫(kù)都實(shí)現(xiàn)它的話,那么我們就不需要ORM!
來(lái)一個(gè)假設(shè)的例子(使用SQL標(biāo)準(zhǔn)語(yǔ)法,而不是Oracle的),像這樣:
SELECT a.*, MULTISET ( SELECT f.* FROM film AS f JOIN film_actor AS fa USING (film_id) WHERE a.actor_id = fa.actor_id ) AS films FROM actor
MULTISET運(yùn)算符使用相關(guān)子查詢參數(shù),并在嵌套集合中聚合其所有生成的行。這和LEFT OUTER JOIN(我們得到了所有的演員,并且如果他們參演電影的話,我們也得到了他們的所有電影)的工作方式類似,但不是復(fù)制結(jié)果集中的所有演員,而是將它們收集到嵌套集合中。
就像我們?cè)贠RM中所做的那樣,當(dāng)獲取事物到這個(gè)結(jié)構(gòu)中時(shí):
@Entity class Actor { @ManyToMany List<Film> films; } @Entityclass Film { }忽略使用的JPA注釋的不完整性,我只想展示嵌套集合的強(qiáng)度。與在ORM中不同,SQL MULTISET運(yùn)算符允許將相關(guān)子查詢的任意結(jié)果收集到嵌套集合中——而不僅僅是實(shí)際實(shí)體。這比ORM強(qiáng)上百萬(wàn)倍。
備代語(yǔ)法:Oracle
正如我所說(shuō),Oracle實(shí)際上支持MULTISET,但是你不能創(chuàng)建ad-hoc嵌套集合。由于某種原因,Oracle選擇為這些嵌套集合實(shí)現(xiàn)名義類型化,而不是通常的SQL樣式結(jié)構(gòu)類型化。所以你必須提前聲明你的類型:
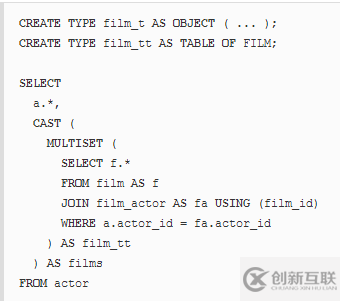
有點(diǎn)更冗長(zhǎng),但仍然取得了成功!真贊!
替代語(yǔ)法:PostgreSQL
超棒的PostgreSQL缺少了一個(gè)優(yōu)秀的SQL標(biāo)準(zhǔn)功能,但有一個(gè)解決方法:數(shù)組!這次,我們可以使用結(jié)構(gòu)類型,哇哦!所以下面的查詢將在PostgreSQL中返回一個(gè)嵌套的行數(shù)組:
SELECT a AS actor, array_agg( f ) AS filmsFROM actor AS aJOIN film_actor AS fa USING (actor_id)JOIN film AS f USING (film_id)GROUP BY a
結(jié)果是每個(gè)人的ORDBMS夢(mèng)想!嵌套記錄和集合無(wú)處不在(只有兩列):
actor films ------------- ---------------- (1,PENELOPE,GUINESS) {(1,ACADEMY DINOSAUR),(23,ANACONDA CONFESSIONS),...} (2,NICK,WAHLBERG) {(3,ADAPTATION HOLES),(31,APACHE DIVINE),...} (3,ED,CHASE) {(17,ALONE TRIP),(40,ARMY FLINTSTONES),...}以上就是SQL中如何連接JOIN表,小編相信有部分知識(shí)點(diǎn)可能是我們?nèi)粘9ぷ鲿?huì)見(jiàn)到或用到的。希望你能通過(guò)這篇文章學(xué)到更多知識(shí)。更多詳情敬請(qǐng)關(guān)注創(chuàng)新互聯(lián)行業(yè)資訊頻道。
新聞標(biāo)題:SQL中如何連接JOIN表
分享網(wǎng)址:http://vcdvsql.cn/article16/iijcgg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供App設(shè)計(jì)、網(wǎng)頁(yè)設(shè)計(jì)公司、網(wǎng)站策劃、網(wǎng)站營(yíng)銷、、定制網(wǎng)站
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 10M帶寬電信服務(wù)器托管一年多少錢(qián)? 2021-03-18
- 服務(wù)器托管有啥好處? 2021-01-26
- 服務(wù)器托管難?4個(gè)技巧幫你選擇好的機(jī)房 2022-10-08
- 如何判斷香港服務(wù)器托管價(jià)格是否合理 2022-10-04
- 杭州服務(wù)器托管公司有哪些? 2021-03-17
- 服務(wù)器之家淺談選擇服務(wù)器托管的三大優(yōu)勢(shì) 2022-10-03
- 服務(wù)器托管注意事項(xiàng) 2021-01-08
- 搭建網(wǎng)站選擇香港服務(wù)器租用還是香港服務(wù)器托管? 2022-10-02
- 服務(wù)器之家淺談高防秒解服務(wù)器托管要多少錢(qián)? 2022-10-04
- 服務(wù)器托管需要注意哪些方面? 2022-10-06
- 免備案服務(wù)器托管有什么好處? 2022-10-03
- 創(chuàng)新互聯(lián)服務(wù)器托管,為您的跨境電商保駕護(hù)航 2021-03-10