如何在JAVA中利用DOM解析XML文件-創(chuàng)新互聯(lián)
如何在JAVA中利用DOM解析XML文件,針對這個問題,這篇文章詳細介紹了相對應(yīng)的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。

代碼如下
import java.io.IOException;
import javax.xml.parsers.*;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class Domtest {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//創(chuàng)建一個DocumentBuilderFactory對象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//創(chuàng)建一個Doucumentbuild對象
DocumentBuilder db=dbf.newDocumentBuilder();
//解析對應(yīng)的xml文件
Document doc=db.parse("tes.xml");
//根據(jù)標簽名獲取Node節(jié)點list
NodeList nodelist=doc.getElementsByTagName("book");
System.out.println("共有"+nodelist.getLength()+"本書");
//遍歷每一個book節(jié)點
for(int i=0;i<nodelist.getLength();i++) {
System.out.println("第"+i+"本書");
//獲取個book節(jié)點
//使用Node類型獲取book
Node book=nodelist.item(i);
System.out.println("Name: "+book.getNodeName()+" Value: "+book.getNodeValue()+" Type: "+book.getNodeType());
//獲取Node節(jié)點中的屬性
NamedNodeMap attrs= book.getAttributes();
//遍歷獲取屬性
for(int j=0;j<attrs.getLength();j++) {
Node x=attrs.item(j);
//System.out.println(x.getNodeName()+" "+x.getNodeValue()+" "+x.getNodeType());
}
//使用Element對象獲取節(jié)點
Element node =(Element) nodelist.item(i);
//使用Element對象下的getAttribute方法可以獲取指定名字的屬性值
String id=node.getAttribute("id");
System.out.println(id);
String type=node.getAttribute("type");
System.out.println(type);
//使用Node節(jié)點下的getChildNode可以獲取Nodelist數(shù)組,以此進行循環(huán)解析
NodeList childnode=book.getChildNodes();
for(int j=0;j<childnode.getLength();j++) {//getLength后會獲取9個節(jié)點,因為text類型也算節(jié)點,一個<name>……</name>算一個節(jié)點,所以共有9個節(jié)點,而這些節(jié)點中,只有對象節(jié)點是我們需要的
Node x=childnode.item(j);
if(x.getNodeType()==Node.ELEMENT_NODE){//當節(jié)點類型為Element時,獲取該節(jié)點
//獲取element類型的節(jié)點名
System.out.println("節(jié)點"+j+"的名字:"+x.getNodeName()+" 值:/"+x.getLastChild().getNodeValue()+"/種類為"+x.getLastChild().getNodeType());//<name>xyz<name>,xyz屬于<name>的子節(jié)點,使用getfirstChild或getLastNode效果相同
System.out.println("節(jié)點"+j+"的名字:"+x.getNodeName()+" 值:/"+x.getTextContent()+"/種類為"+x.getNodeType());//getTextContent方法可以獲取節(jié)點中所有的text內(nèi)容 將<name>xyz</name>改為<name><a>123</a>xyz</name>,會獲取到xyz123
}
}
}
}
}
//為了將獲取到的xml文件中內(nèi)容保存下來,可以將內(nèi)容保存到對象數(shù)組中一次來存儲數(shù)據(jù)<?xml version="1.0" encoding="UTF-8" ?> <Bookstore> <book id="1" type="text"> <name>冰與火之歌</name> <author>喬治馬丁</author> <year>2014</year> <price>80</price> </book> <book id="2"> <name>安徒生童話</name> <year>2004</year> <price>79</price> <language>English</language> </book> </Bookstore>
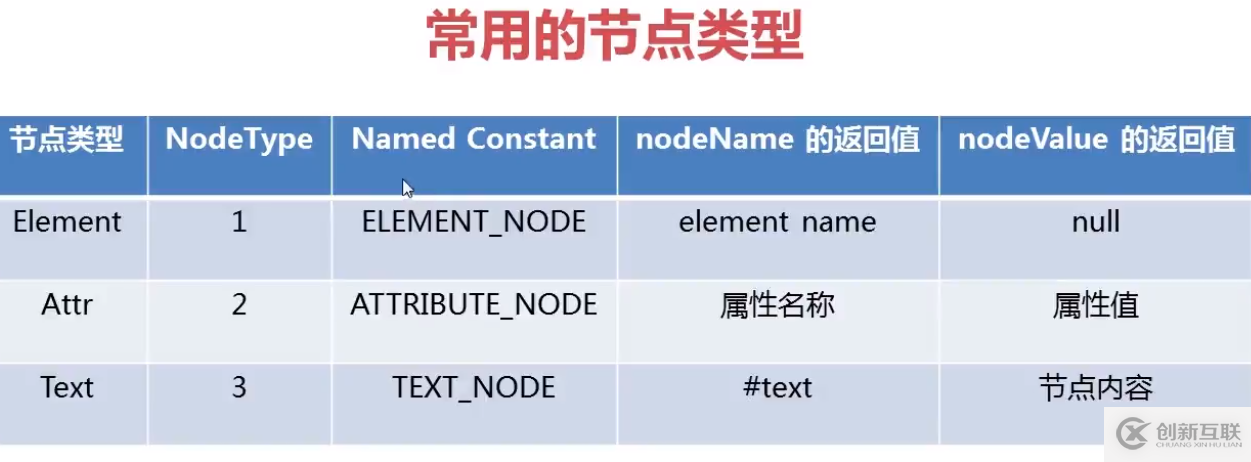
注意點
1 空白換行符也算節(jié)點,所以遍歷節(jié)點時需要注意這些無用的節(jié)點會混在list中
2 text類節(jié)點返回Name值都是#text,而Element類節(jié)點返回value值都是null,需要注意
關(guān)于如何在JAVA中利用DOM解析XML文件問題的解答就分享到這里了,希望以上內(nèi)容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關(guān)注創(chuàng)新互聯(lián)網(wǎng)站建設(shè)公司行業(yè)資訊頻道了解更多相關(guān)知識。
另外有需要云服務(wù)器可以了解下創(chuàng)新互聯(lián)建站vcdvsql.cn,海內(nèi)外云服務(wù)器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務(wù)器、裸金屬服務(wù)器、高防服務(wù)器、香港服務(wù)器、美國服務(wù)器、虛擬主機、免備案服務(wù)器”等云主機租用服務(wù)以及企業(yè)上云的綜合解決方案,具有“安全穩(wěn)定、簡單易用、服務(wù)可用性高、性價比高”等特點與優(yōu)勢,專為企業(yè)上云打造定制,能夠滿足用戶豐富、多元化的應(yīng)用場景需求。
本文題目:如何在JAVA中利用DOM解析XML文件-創(chuàng)新互聯(lián)
文章地址:http://vcdvsql.cn/article16/pjggg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供微信公眾號、微信小程序、定制開發(fā)、網(wǎng)站制作、品牌網(wǎng)站設(shè)計、軟件開發(fā)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時需注明來源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- Yii2.0模態(tài)彈出框以及ajax提交表單的實例用法-創(chuàng)新互聯(lián)
- python交互繪制Julia集-創(chuàng)新互聯(lián)
- golang會代替java成為主流嗎-創(chuàng)新互聯(lián)
- 怎么在Linux系統(tǒng)中傳輸文件-創(chuàng)新互聯(lián)
- C++用兩個棧實現(xiàn)一個隊列(面試官的小結(jié))-創(chuàng)新互聯(lián)
- xamarinAndroid如何實現(xiàn)ListView萬能適配器-創(chuàng)新互聯(lián)
- SparkonYarn安裝配置-創(chuàng)新互聯(lián)

- 學習網(wǎng)站建設(shè)的步驟 2017-12-19
- 雖說企業(yè)網(wǎng)站建設(shè)應(yīng)順勢而為但也不可過于盲目追求 2022-05-22
- 影響響應(yīng)式網(wǎng)站建設(shè)價格的六點要素 2022-05-02
- 上海網(wǎng)站建設(shè)網(wǎng)創(chuàng)新互聯(lián) 2020-11-11
- 為什么成都網(wǎng)站建設(shè)公司獨受大家青睞 2016-08-25
- 網(wǎng)站建設(shè)要把握哪些重點 2016-04-06
- 網(wǎng)站制作公司:企業(yè)網(wǎng)站建設(shè)有要了解的常識 2022-05-02
- 成都網(wǎng)站建設(shè)公司告訴你企業(yè)做網(wǎng)絡(luò)推廣為何如此重要 2013-07-29
- 長沙高端定制網(wǎng)站建設(shè)公司哪家好? 2022-09-24
- 網(wǎng)站建設(shè)公司學會選擇客戶可以獲得更好發(fā)展 2022-05-23
- 企業(yè)網(wǎng)站建設(shè)傳感設(shè)備對數(shù)字圖像采集在網(wǎng)頁設(shè)計中的應(yīng)用 2022-05-03
- 鄭州專業(yè)網(wǎng)站建設(shè):保證網(wǎng)站加載速度要做好這幾點 2021-12-29