C++之二叉搜索樹詳解-創新互聯
- 前言
- 一、二叉搜索樹的概念
- 二、二叉搜索樹的操作
- 1.節點類
- 2.二叉搜索樹類內部定義
- 3.遍歷操作
- 4.構造函數
- 5.拷貝構造函數
- 6.賦值運算符重載
- 7.析構函數
- 8.插入函數
- 非遞歸實現
- 遞歸實現
- 9.刪除函數
- 非遞歸實現
- 遞歸實現
- 10.查找函數
- 非遞歸實現
- 遞歸實現
- 三、二叉搜索樹的應用
- K模型
- KV模型
- 四、二叉搜索樹的性能分析
- 總結

對于已經學習C++/C語言的朋友來說,二叉樹這個概念相信已經再熟悉不過了,我們平時接觸的二叉樹可能都很簡單,今天我們來看一個比較有難度的二叉樹,他的名字就是——二叉搜索樹,只是聽名字就知道他其實是用來搜索數據用的,那么他到底有什么特別之處呢?下面讓我們一起來看看吧。
一、二叉搜索樹的概念二叉搜索樹又稱二叉排序樹(二叉查找樹),它或者是一棵空樹,或者是具有以下性質的二叉樹:
1.若它的左子樹不為空,則左子樹上所有結點的值都小于根結點的值。
2.若它的右子樹不為空,則右子樹上所有結點的值都大于根結點的值。
3.他的左右子樹也分別為二叉樹搜索樹
上面的這棵樹就是一個典型的二叉搜索樹。
既然已經大概知道一棵二叉搜索樹是什么樣子的了,那么就讓我們一起來實現一下吧。
1.節點類我們知道二叉樹其實就是一個一個的結點連接在一起,然后遵循我們前面所說的概念,就能夠形成一棵二叉搜索樹了,所以結點類是必不可少的。
template//模板參數
struct BSTreeNode
{
struct BSTreeNode* _left;//左指針
struct BSTreeNode* _right;//右指針
K _key; //結點存儲的值(節點值)
//構造函數,實現對創建的結點的初始化
BSTreeNode(const K& key)
:_left(nullptr)
,_right(nullptr)
,_key(key)
{}
}; 注: 因為我們后面定義的二叉搜索樹需要用到我們這里定義的結點類,所以直接將他定義為struct的形式,因為struct中的成員函數和成員變量默認是共有的,這樣方便我們后面的調用。
2.二叉搜索樹類內部定義templateclass BSTree
{
typedef BSTreeNodeNode; //typedef使代碼更簡潔
public:
//構造函數
//這樣可以讓編譯器強制自己生成默認構造函數
BSTree() = default;
//拷貝構造
BSTree(const BSTree& t){}
//析構函數
~BSTree(){}
BSTree& operator=(BSTreet){}
//插入操作
bool Insert(const K& key){}
//刪除操作
bool Erase(const K& key){}
//中序遍歷
void InOrder(){}
//查找操作
bool Find(const K& key)
private:
//子函數
Node* _Copy(Node* root){}
void _InOrder(Node* root){}
void _Destory(Node* root){}
private:
Node* _root = nullptr;
}; 因為我們之后要查看我們創建的樹到底符不符合我們的要求以及一些接口實現的正確性,所以我們需要將其中存儲的數據打印出來,這里還有一個細節,如果我們以中序遍歷的方式去遍歷整棵二叉樹的話,最后的打印結果是以升序的方式排布的,這樣方便我們查看。
void _InOrder(Node* root)
{
if (root == nullptr)
return;
_InOrder(root->_left);//遍歷左子樹
cout<< root->_key<< " ";
_InOrder(root->_right);//遍歷右子樹
}
void InOrder()
{
_InOrder(_root);//調用子函數
cout<< endl;
}這里大家可以看到我們上面給出了兩個函數,其中_InOrder是用訪問限定符private修飾的,這里為什么要這么操作呢?
解釋:
這里的_InOrder是InOrder函數的子函數,因為_root是私有成員,用戶去調用這里的遍歷函數的話就需要傳入根結點,但是我們經過封裝后,用戶是無法訪問_root這個成員變量的,所以才有了這里的子函數的誕生,類內的函數是可以訪問類內的所有成員變量的,我們可以通過子函數去實現函數的功能,用戶在調用函數的不需要傳入任何參數,這樣既沒有會暴露我們的底層實現,也實現了函數的功能。
在后面的操作中涉及到遞歸函數的時候,也會這樣使用。
這里得構造函數是一定要自己實現的,因為后面我們需要拷貝構造函數,他其實也是一個構造函數,根據我們前面所學的,當我們自己寫了一個構造函數的時候,編譯器是無法再自動生成默認構造函數的。就不能再像下面的這種情況進行樹的定義,所以構造函數一定要自己顯示寫一個。
//沒有默認構造函數的話,就不能像這樣進行構造
BSTreet; 構造函數有三種寫法:
//1.可以這么寫,順便進行初始化
BSTree()
:_root(nullptr)//創建一個空樹
{}
//2.可以這么寫,內置類型編譯器可以自動初始化
BSTree(){}
//3.可以這么寫
//這樣可以讓編譯器強制自己生成默認構造函數
BSTree() = default;這里又要用到我們前面遍歷函數所講的子函數,道理是相同的,這里就不再進行描述。
//利用遞歸實現拷貝構造的子函數
Node* _Copy(Node* root)
{
//如果是空樹的話直接返回
if (root == nullptr)
return nullptr;
Node* copyRoot = new Node(root->_key);//先拷貝根結點
copyRoot->_left = _Copy(root->_left);//拷貝左子樹
copyRoot->_right = _Copy(root->_right);//拷貝右子樹
return copyRoot; //返回拷貝的樹的根結點
}
BSTree(const BSTree& t)
{
//因為需要_root私有成員,所以需要一個子函數。
_root = _Copy(t._root); //拷貝子函數
} 注意: 這里的拷貝構造函數實現的是深拷貝。
6.賦值運算符重載關于賦值運算符重載一般情況下是有兩種方法的,我們將其稱為現代寫法和傳統寫法。
現代寫法
BSTree& operator=(BSTreet)//函數在接收傳入的參數的時候會先自動調用拷貝構造函數創建t對象
{
swap(_root, t._root);//將本對象的_root結點與t對象中的_root進行交換,就實現可兩棵樹數據互換,即拷貝成功
return *this; //這樣返回的話也就可以支持連續賦值
} 傳統寫法
傳統寫法就是將傳入的樹的結點一一進行拷貝后再鏈接在一起就可以了。
BSTree& operator=(BSTree& t)
{
if (this != &t) //防止自己給自己賦值
{
_root = _Copy(t._root);
}
return *this;//支持連續賦值
} 這里也需要實現一個子函數,因為我們在銷毀樹的時候也需要傳入私有成員–根結點。
void _Destory(Node* root)
{
//空樹直接返回
if (root == nullptr)
{
return;
}
//轉化為子問題
_Destory(root->_left);//銷毀左子樹
_Destory(root->_right);//銷毀右子樹
delete root; //釋放根結點
root = nullptr;
}
//析構函數
~BSTree()
{
//調用子函數
_Destory(_root);
}二叉搜索樹的插入
插入的具體過程如下:
a. 樹為空,則直接新增結點,賦值給root指針
b. 樹不空,按二叉搜索樹性質查找插入位置,插入新結點
若樹不為空其具體操作如下:
1.若插入的結點的值小于根結點的值,則需要進入左子樹進行插入
2.若插入的結點的值大于根結點的值,則需要進入右子樹進行插入
3.若插入的結點的值與根結點的值相等,則插入失敗
重復上面的操作,找到與自己相等的結點,插入失敗,直接返回。若是走到了空結點的位置,則說明在該樹中沒有與之相等的值,進行插入操作即可。
非遞歸實現下面的key變量即為我們要插入的值,因為我們最后還要將新建的節點與前面的結點(也就是父結點)連接起來,所以還需要個結點記錄父結點(即parent)
bool Insert(const K& key)
{
//剛進入查找時,根結點為空,說明是空樹,直接插入即可
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root;
Node* parent = nullptr;
//循環找空,cur走到空則找到了自己的位置
while (cur)//(cur != nullptr)
{
//key大于當前結點的值,根據性質需要到右子樹去尋找
if (key >cur->_key)
{
parent = cur;
cur = cur->_right;
}
//key小于當前結點的值,根據性質需要到左子樹去尋找
else if (key< cur->_key)
{
parent = cur;
cur = cur->_left;
}
//上面的兩種情況都不是的話,說明key值與當前節點的值相等,插入失敗
else
return false;
}
//循環結束后說明找到了屬于自己的位置,創建結點
cur = new Node(key);
//此時還需要判斷一下節點與父結點的關系
//大于父結點的值,插入到父結點的右邊
if (key >parent->_key)
parent->_right = cur;
//否則插入父結點的左邊
else
parent->_left = cur;
//插入成功返回true
return true;
}//子函數實現遞歸
bool _InsertR(Node*& root, const K& key)//注意引用,十分重要
{
//查找時,根結點為空,說明是空樹或找到了插入的位置,直接插入
if (root == nullptr)
{
root = new Node(key);
//插入成功,返回true
return true;
}
//key大于當前結點的值,根據性質需要到右子樹去尋找
if (key >root->_key)
{
//進入右子樹
return _InsertR(root->_right, key);
}
//key小于當前結點的值,根據性質需要到左子樹去尋找
else if (key< root->_key)
{
//進入左子樹
return _InsertR(root->_left, key);
}
//上面的兩種情況都不是的話,說明key值與當前結點的值相等,插入失敗
else
return false;
}
//外部函數對遞歸函數實現封裝
bool InsertR(const K& key)
{
//直接調用子函數
return _InsertR(_root, key);
}注意: 本函數中最精華的地方就是傳的是引用參數,因為有引用的存在,我們就不需要去記錄父節點所在的位置,直接修改root的指向,同時也就修改了父結點的指向。
9.刪除函數在實現二叉搜索樹的函數中,刪除操作是最復雜的,其中的情況有很多。
首先查找元素是否在二叉搜索樹中,如果不存在,則返回,否則要刪除的結點可能分下面的四種情況:
a.要刪除的結點無孩子結點
b.要刪除的結點左子樹為空
c.要刪除的結點右子樹為空
d.要刪除的結點左右子樹均不為空
看起來要刪除結點是有4中情況,實際情況中情況a可以與情況b或者情況c合并起來,因此真正的刪除過程如下:
1.要刪除的結點左子樹為空(左右子樹均為空)
2.要刪除的結點右子樹為空
3.要刪除的結點左右子樹均不為空
只是這么看的話,可能比較抽象,下面我們將其分開剖析,然后再結合畫圖,一起看看如何實現其代碼。
情況1:要刪除的結點左子樹為空(左右子樹均為空)
這里我們將前面所說的情況a放入情況b中一起講解。
這里為了更好地演示,我會將幾個空結點也畫出來。
1.先來看左右子樹均為空的場景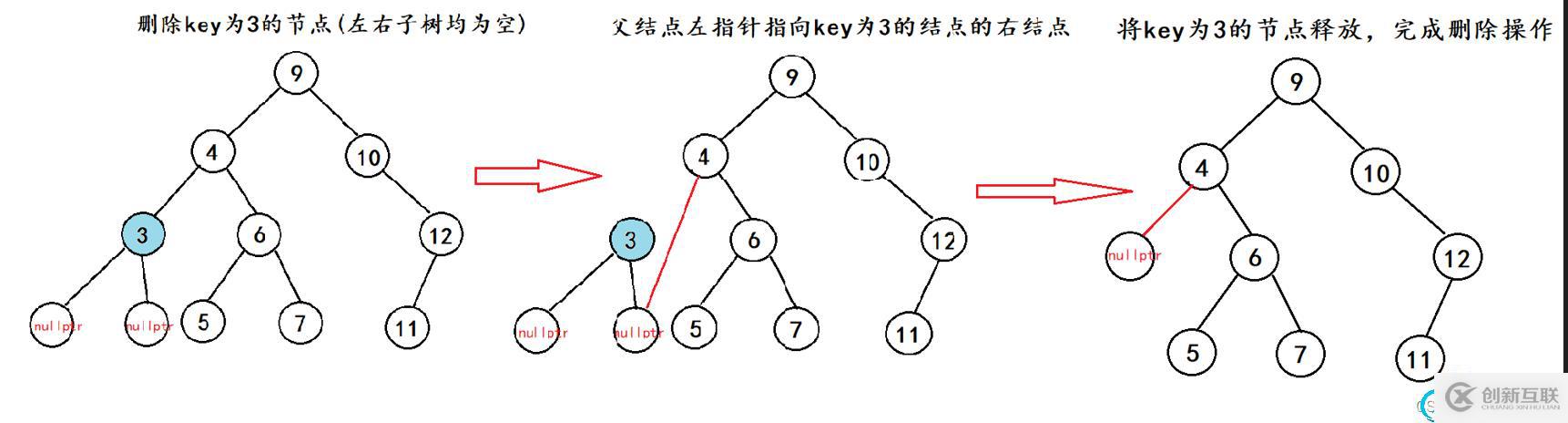
2.再來看一下左子樹為空的場景
場景1: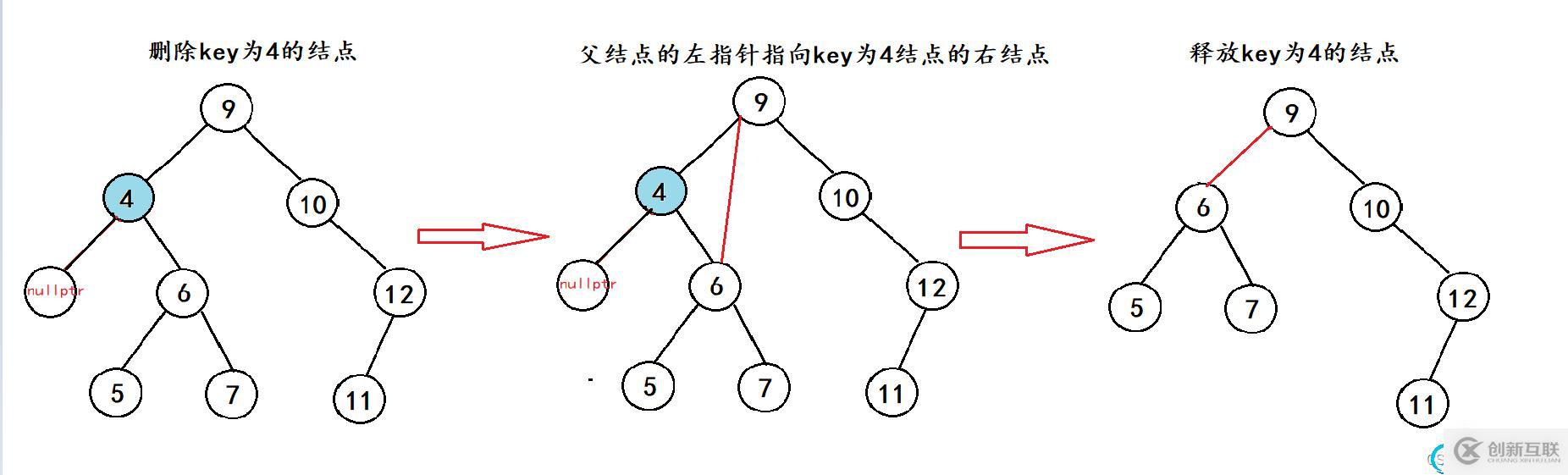
通過上面兩個圖的對比,我們可以看出在情況a與情況b中的操作是相同的,所以我們可以將他們歸為一種情況去操作。
其實在刪除左子樹為空的結點的時候是有兩個場景的,上面的場景是要刪除的結點在父節點的左邊,下面的這種場景是要刪除的結點在父節點的右邊,但是他們共有的特性都是左子樹為空。所以只是在處理父節點的時候不同而已
場景2: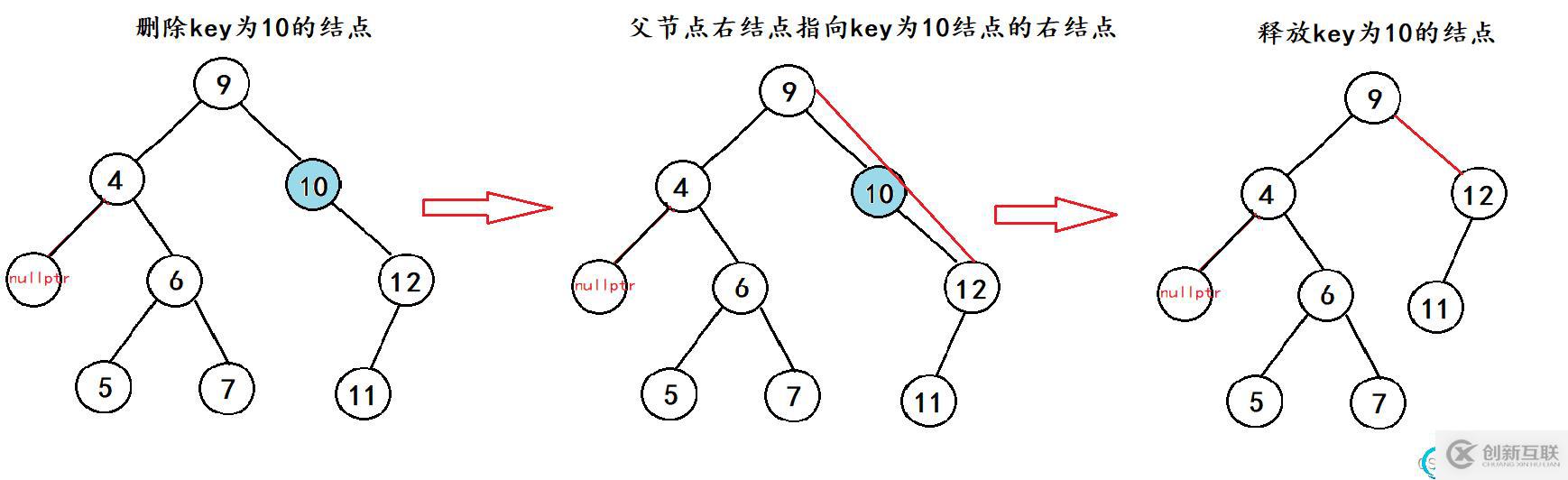
情況2:要刪除的結點右子樹為空
這種情況其實與情況1中的左子樹為空一樣,也有兩種場景,與父結點有關系,所以我們就直接放在一起了。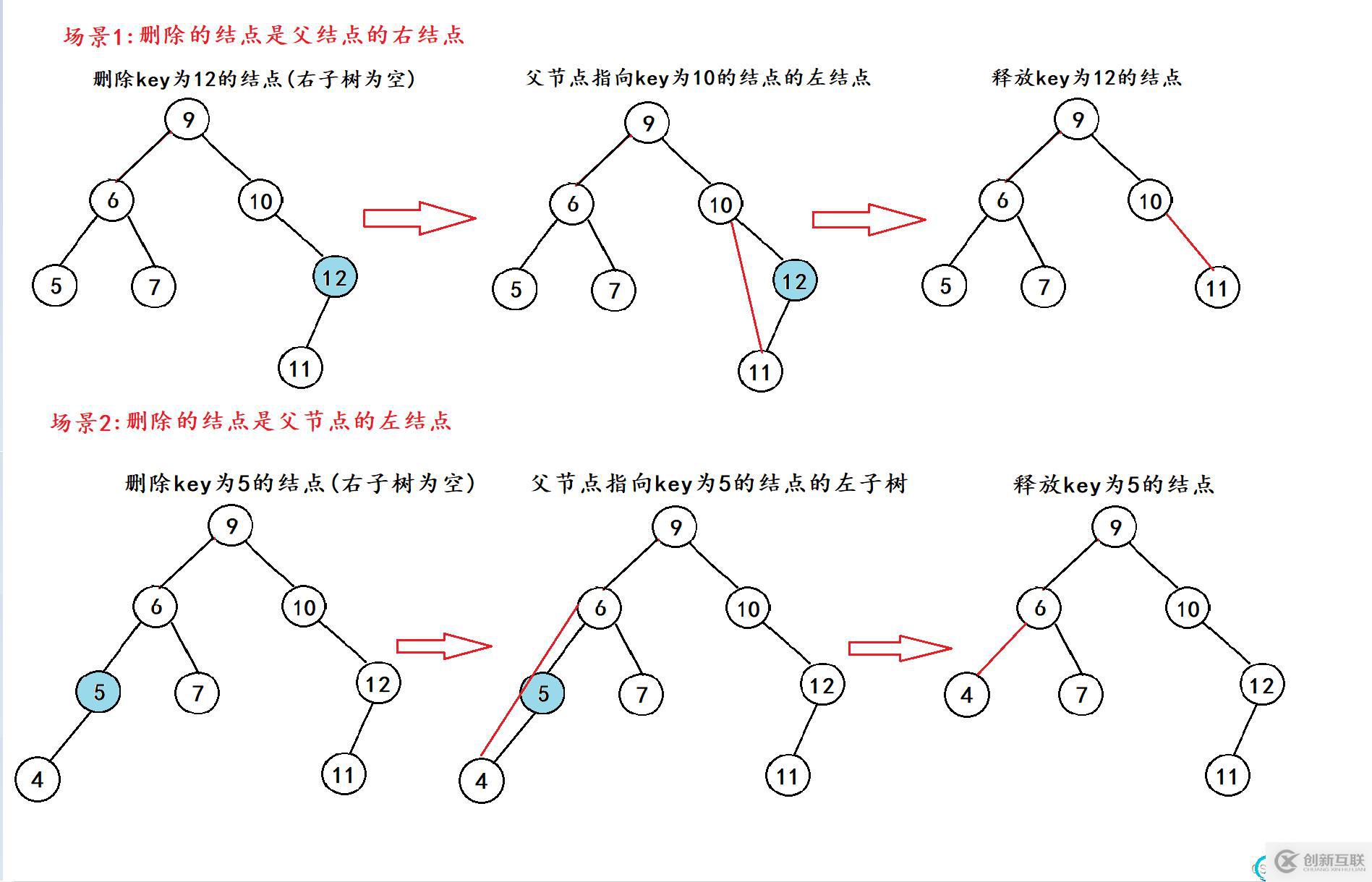
情況3.要刪除的結點左右子樹均不為空
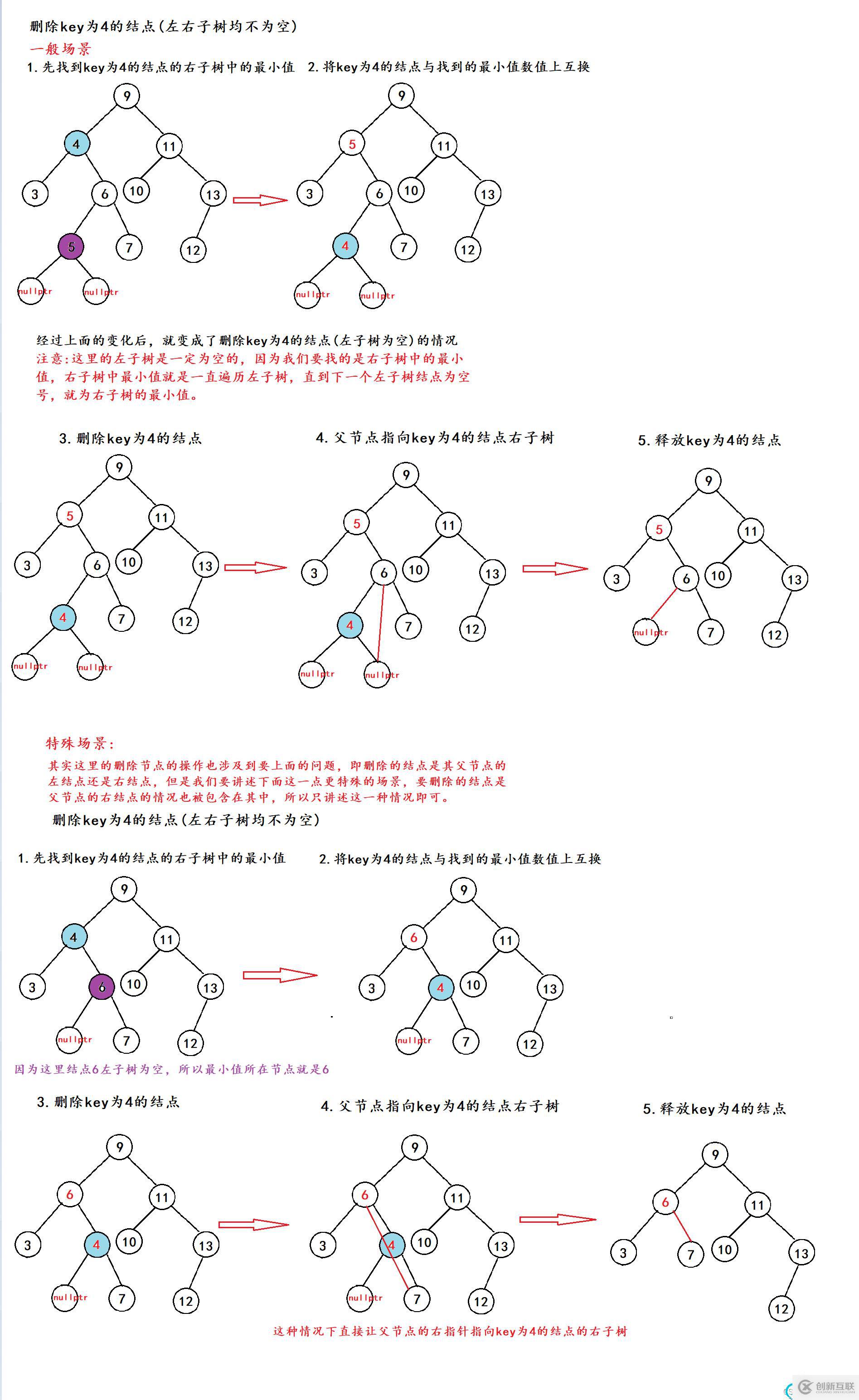
其實除了我們上面舉出的例子外,還有刪除父結點的值的情況,其實他們的操作都是類似的,都是將要刪除的值換出去,進而delete其他的結點。
bool Erase(const K& key)
{
//定義一個cur結點指針,進行查找
Node* cur = _root;
//定義一個結點保存父結點的指針
Node* parent = nullptr;
//查找我們要刪除的結點
while (cur)
{
//key大于當前結點的值,根據性質需要到右子樹去尋找
if (key >cur->_key)
{
parent = cur;
cur = cur->_right;
}
//key小于當前結點的值,根據性質需要到左子樹去尋找
else if (key< cur->_key)
{
parent = cur;
cur = cur->_left;
}
//上面兩種情況都不是,就是已經找到了,開始刪除
else
{
//1.左為空,只有右孩子
if (cur->_left == nullptr)
{
//如果是根結點,直接讓_root指向當前結點的右結點
if (cur == _root)
{
_root = cur->_right;
}
//如果不是根結點,需要判斷要刪除的結點是父節點的左結點還是右結點
else
{
//是父節點的左結點,則讓父親的左結點指向要刪除節點的右結點
if (parent->_left == cur)
{
parent->_left = cur->_right;
}
//是父節點的右結點,則讓父親的右結點指向要刪除節點的右結點
else
{
parent->_right = cur->_right;
}
}
//釋放結點的空間
delete cur;
cur = nullptr;//置空
}
//2.右為空,只有左孩子
else if (cur->_right == nullptr)
{
//如果是根結點,直接讓_root指向當前結點的右結點
if (cur == _root)
{
_root = cur->_left;
}
//如果不是根結點,需要判斷要刪除的結點是父節點的左結點還是右結點
else
{
//是父節點的左結點,則讓父親的左結點指向要刪除節點的左結點
if (parent->_left = cur)
{
parent->_left = cur->_left;
}
//是父節點的右結點,則讓父親的右結點指向要刪除節點的左結點
else
{
parent->_right = cur->_left;
}
}
//釋放結點的空間
delete cur;
cur = nullptr;
}
//3.有左右孩子,替換法
//這里我們找右子樹的最小值
else
{
//定義一個結點記錄找到的最小值所在的結點
Node* min = cur->_right;
//定義一個結點記錄找到的最小值所在的結點的父節點
Node* minParent = cur;
//循環查找最小值所在的結點
while (min->_left)
{
minParent = min;//min結點發生變化的時候父節點也要變化
min = min->_left;//min結點變化
}
//循環結束表示已經找到最小值所在的結點
swap(cur->_key, min->_key);//交換數據
//min結點在父結點的左邊
if (minParent->_left == min)
{
minParent->_left = min->_right;
}
//min結點在父節點的右邊
else
{
minParent->_right = min->_right;
}
//釋放結點的空間
delete min;
min = nullptr;//置空
}
//刪除成功返回true
return true;
}
}
//刪除失敗返回false
return false;
}遞歸實現刪除操作的思路:
1.若樹為空樹(這里所說的樹可能是整棵大樹,也可能是遞歸時的子樹),則結點刪除失敗,直接返回false。
2.若所傳入的key值小于當前樹的根節點的值,則問題變為刪除左子樹中值為key的結點。
3.若所傳入的key值大于當前樹的根節點的值,則問題變為刪除右子樹中值為key的結點。
4.若所傳入的key值等于當前樹的根節點的值,則分析該結點滿足的我們上面分析的哪一種情況,刪除該結點。
bool _EraseR(Node*& root, const K& key)//注意引用
{
//若根節點為空,直接返回false
if (root == nullptr)
return false;
//若傳入的key值大于當前結點的值,則要刪除的結點在右子樹中
if (key >root->_key)
return _EraseR(root->_right, key);
//若傳入的key值小于當前結點的值,則要刪除的結點在左子樹中
else if(key< root->_key)
return _EraseR(root->_left, key);
//走到這里這里表示當前節點就為要刪除的的結點
else
{
//定義一個節點保存要刪除的結點的地址
Node* del = root;
//1.左為空,只有右孩子
if (root->_left == nullptr)
{
root = root->_right;
}
//2.右為空,只有左孩子
else if (root->_right == nullptr)
{
root = root->_left;
}
//3.有左右孩子
else
{
//定義一個結點記錄找到的最小值所在的結點
Node* min = root->_right;
//循環查找最小值,左為空,則當前節點中的值就為最小值
while (min->_left)
{
min = min->_left;
}
//交換最小值與要刪除的值
swap(root->_key, min->_key);
//替換后轉化為刪除右子樹中的節點(轉化為子問題)。
//因為我們的操作就是去右子樹中查找最小值,所以要刪除的結點一定在右子樹中。
return _EraseR(root->_right, key);
}
//釋放要刪除的結點的空間
delete del;
del = nullptr;//置空
//刪除成功,返回true
return true;
}
}
bool EraseR(const K& key)
{
//調用子函數
return _EraseR(_root, key);
}注意: 本函數中最精華的地方就是傳的是引用參數,因為有引用的存在,我們就不需要去記錄父節點所在的位置,直接修改root的指向,同時也就修改了父結點的指向。
10.查找函數查找函數就非常簡單了,我們只需要根據二叉搜索樹的性質去進行查找就可以了。
查找操作的思路:
1.若樹為空樹,則查找失敗,直接返回false
2.若所傳入的key值小于當前樹的根節點的值,則應該去左子樹中查找
3.若所傳入的key值大于當前樹的根節點的值,則應該去右子樹中查找
4.若所傳入的key值等于當前樹的根節點的值,就找到了,直接返回true
bool Find(const K& key)
{
//定義一個cur負責查找我們要找的值
Node* cur = _root;
//如果cur!=nullptr,就可以一直進行查找
while (cur)
{
//如果key的值大于當前結點的值,則要找的值在右子樹中
if (key >cur->_key)
cur = cur->_right;
//如果key的值小于當前結點的值,則要找的值在左子樹中
else if (key< cur->_key)
cur = cur->_left;
//走到這里表示當前的值就為我們要找的值
else
//直接返回true,表示樹中存在key值
return true;
}
//循環結束,表示cur走到了空,即樹中沒有該key值
return false;
}bool _FindR(Node* root,const K& key)
{
//如果根節點為空,則直接返回
if (root = nullptr)
return false;
//如果key的值大于當前結點的值,則要找的值在右子樹中
if (key >root->_key)
return _FindR(root->_right, key);
//如果key的值小于當前結點的值,則要找的值在左子樹中
else if (key< root->_key)
return _Find(root->_left, key);
//到這一步則證明已經找到與key值相同的值,返回true
else
return true;
}
bool FindR(const K& key)
{
//調用子函數
return _FindR(_root,key);
}K模型即只有key作為關鍵碼,結構中只需要存儲Key即可,關鍵碼即為需要搜索到的值。
比如:給一個單詞,判斷該單詞是否拼寫正確,具體方式如下:
以詞庫中所有單詞集合中的每個單詞作為key,構建一棵二叉搜索樹
在二叉搜索樹中檢索該單詞是否存在,存在則拼寫正確,不存在則拼寫錯誤。
每一個關鍵碼key,都有與之對應的值Value,即
該種方式在現實生活中非常常見:
比如英漢詞典就是英文與中文的對應關系,通過英文可以快速找到與其對應的中文,英文單詞與其對應的中文
再比如統計單詞次數,統計成功后,給定單詞就可快速找到其出現的次數,單詞與其出現次數就是
插入和刪除操作都必須先查找,查找效率代表了二叉搜索樹中各個操作的性能。
對有n個結點的二叉搜索樹,若每個元素查找的概率相等,則二叉搜索樹平均查找長度是結點在二叉搜索樹的深度的函數,即結點越深,則比較次數越多。
但對于同一個關鍵碼集合,如果各關鍵碼插入的次序不同,可能得到不同結構的二叉搜索樹,如下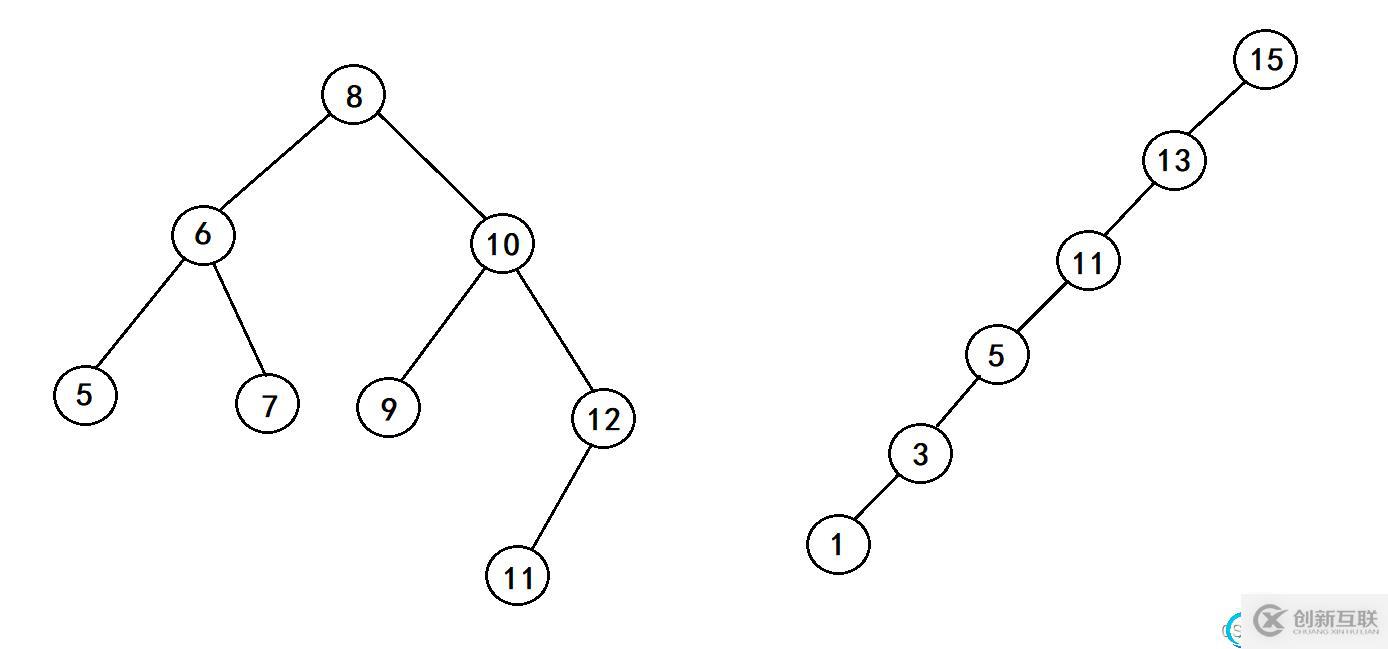
最優情況下,二叉搜索樹為完全二叉樹(或者接近完全二叉樹),其平均比較次數為:logN
最差情況下,二叉搜索樹退化為單枝樹(或者類似單支),其比較次數最壞能達到n。
如果退化成單枝樹,二叉搜索樹的性能就失去了。所以我們在后面要對其進行改進,不論按照什么次序插入關鍵碼,二叉搜索樹的性能都能達到最優。這里就涉及到了我們后面要學習的AVL樹和紅黑樹。
以上就是我們所講的二叉搜索樹的全部內容了,其中的重點和難點其實都是刪除操作,其他的一些操作還是比較容易理解的,后面我們還會講述更AVL樹、紅黑樹等更高階的樹的實現,大家可以先關注博主,方便以后查看。如果你覺得我的內容對你有用的話,記得給波三連呦!!!
你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
網站欄目:C++之二叉搜索樹詳解-創新互聯
鏈接分享:http://vcdvsql.cn/article16/ppjdg.html
成都網站建設公司_創新互聯,為您提供品牌網站建設、網站設計公司、ChatGPT、企業網站制作、建站公司、微信小程序
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 成都做網站丨企業網站應該具備哪些功能? 2016-09-06
- 剛開始做網站首先要先了解哪些知識 2016-11-04
- 做網站到底是選擇價格重要還是選擇性能重要呢? 2022-07-02
- 如今企業做網站在朝哪個方向進步 2022-09-23
- 針對網站優化做網站的服務器哪里買的問題 2016-09-07
- 做網站要從哪里先下手 2022-10-21
- 成都做網站:網絡推廣和網絡營銷有什么差異? 2022-10-22
- 做網站的優化需要學習房子搭建技巧 2016-09-05
- 定制做網站需要注意哪些方面? 2022-07-04
- 企業做網站建設的3個原因 2022-08-04
- 自己怎么做網站?這三大要素缺一不可 2021-04-25
- 成都網站建設公司告訴您如何利用百度站長工具做網站優化 2016-11-08