selenium怎么處理iframe作用域問題
這篇文章給大家分享的是有關selenium怎么處理iframe作用域問題的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
創新互聯服務項目包括洪澤網站建設、洪澤網站制作、洪澤網頁制作以及洪澤網絡營銷策劃等。多年來,我們專注于互聯網行業,利用自身積累的技術優勢、行業經驗、深度合作伙伴關系等,向廣大中小型企業、政府機構等提供互聯網行業的解決方案,洪澤網站推廣取得了明顯的社會效益與經濟效益。目前,我們服務的客戶以成都為中心已經輻射到洪澤省份的部分城市,未來相信會繼續擴大服務區域并繼續獲得客戶的支持與信任!
在使用python進行爬蟲操作的過程中,一般為了防止爬蟲,會使用iframe,但是由于iframe有限制,iframe是前端內嵌頁面,訪問域名與主網頁不同,所以有時會得到不自己想要的數據。本文針對抓包工具定位沒有定位到iframe中的小的html中提供解決方法。
以文本塊生成xpath為/html/body/text(),根據xpath進行如下代碼編寫。
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3')
time.sleep(2)
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()得到結果
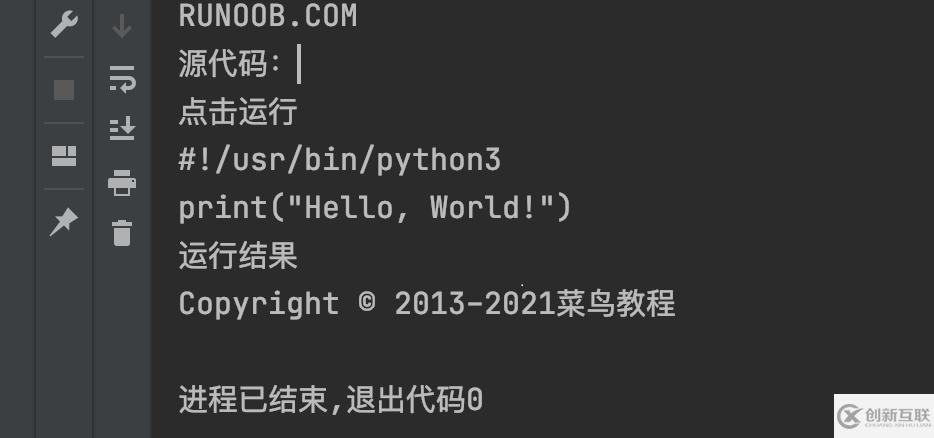
原因分析
當我們打開抓包工具定位到Hello, World!文本的時候會發現,該文本是在一個iframe中。這樣的話我們xpath所定位到的內容則是大的html中的路徑。我們需要的內容則是在iframe中的小的html中。
解決方法
通過分析發現,想要解決問題的實質就是改變作用域。通過switch_to.frame(‘id’)方法來改變作用域就可以了。
重新編寫代碼:
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3')
time.sleep(2)
driver.switch_to.frame('iframeResult')
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()運行結果
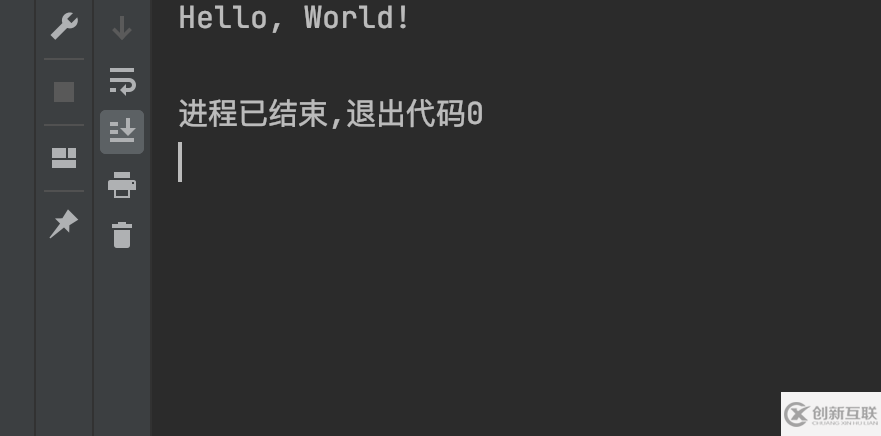
感謝各位的閱讀!關于“selenium怎么處理iframe作用域問題”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
分享名稱:selenium怎么處理iframe作用域問題
URL鏈接:http://vcdvsql.cn/article18/iijddp.html
成都網站建設公司_創新互聯,為您提供網站建設、虛擬主機、品牌網站設計、網站收錄、App設計、網站改版
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 自適應網站制作過程中要注意的細節 2021-06-23
- 自適應網站與響應式網站的區別是什么? 2016-03-14
- 自適應網站和響應式網站的區別和缺點 2015-03-17
- 企業建站是否應該選擇自適應網站設計? 2022-05-10
- 深度刨析自適應網站設計的特點 2021-04-29
- 合肥自適應網站建設的注意事項介紹 2021-11-05
- 為什么自適應網站設計很受歡迎 2013-08-31
- 淺談自適應網站設計特點 2021-04-30
- 自適應網站制作注意事項 2016-09-12
- 響應式網站和自適應網站的區別 2016-12-05
- 企業網站建設為什么要做手機站自適應網站有什么優勢 2022-11-05
- 響應式網頁設計與自適應網站 2015-12-12