python如何實現爬取中國前20大學排名案例-創新互聯
創新互聯www.cdcxhl.cn八線動態BGP香港云服務器提供商,新人活動買多久送多久,劃算不套路!

這篇文章將為大家詳細講解有關python如何實現爬取中國前20大學排名案例,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
一、中國大學排名爬蟲案例的步驟如下:
步驟1:從網絡上獲取大學排名網頁內容 getHTMLText()
步驟2:提取網頁內容中信息到合適的數據結構 fillUnivList()
步驟3:利用數據結構展示并輸出結果 printUnivList()
實例代碼
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
'''從網絡上獲取大學排名網頁內容'''
try:
r = requests.get(url, timeout=30)
# #如果狀態不是200,就會引發HTTPError異常
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
'''提取網頁內容中信息到合適的數據結構'''
soup = BeautifulSoup(html, "html.parser")
# 查找html中tbody標簽的所有<tr>子標簽
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# tds[0].string 是排名,tds[1].string 是學校名稱,tds[3].string 是學校的總分
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
''' 打印前 num 名的大學'''
# {1:{3}^10} 中的 {3} 代表取第三個參數
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","學校名稱","總分",chr(12288))) # chr(12288) 代表中文空格
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288))) # chr(12288) 代表中文空格
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)# 獲取大學排名網頁內容
fillUnivList(uinfo, html)#提取網頁內容中信息
printUnivList(uinfo, 20) #輸出結果
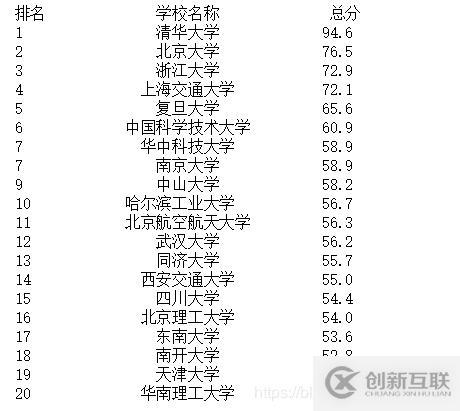
main()結果如下
關于python如何實現爬取中國前20大學排名案例就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
文章名稱:python如何實現爬取中國前20大學排名案例-創新互聯
本文網址:http://vcdvsql.cn/article22/giijc.html
成都網站建設公司_創新互聯,為您提供外貿建站、手機網站建設、網站維護、全網營銷推廣、標簽優化、做網站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 成都外貿建站怎么做? 2015-06-18
- 外貿建站選擇香港主機都有哪些優勢? 2022-10-10
- 外貿建站應該怎么做 2021-03-05
- 海珠區外貿建站公司:專注歐美英文網頁設計制作! 2016-02-07
- 外貿建站推廣?八大技巧幫您引流 2016-03-01
- 外貿建站要留意的各種因素 2022-10-28
- 外貿建站中的那些細節影響著網站流量? 2015-04-24
- 開發好的APP如何獲取用戶,告訴你了你也不一定領悟明白! 2022-06-02
- 外貿建站中的哪些細節影響著網站流量? 2015-06-11
- 外貿建站選韓國vps主機適合嗎? 2022-10-07
- 外貿建站不得不說的秘密 2015-05-07
- 按外貿建站域名五原則挑選老外喜歡的域名 2015-05-01