MySQL高可用集群架構(gòu)MHA
MHA(Master HighAvailability)目前在MySQL高可用方面是一個(gè)相對(duì)成熟的解決方案,它由日本DeNA公司youshimaton(現(xiàn)就職于Facebook公司)開發(fā),是一套優(yōu)秀的作為MySQL高可用性環(huán)境下故障切換和主從提升的高可用軟件。在MySQL故障切換過程中,MHA能做到在0~30秒之內(nèi)自動(dòng)完成數(shù)據(jù)庫(kù)的故障切換操作,并且在進(jìn)行故障切換的過程中,MHA能在最大程度上保證數(shù)據(jù)的一致性,以達(dá)到真正意義上的高可用。
在象州等地區(qū),都構(gòu)建了全面的區(qū)域性戰(zhàn)略布局,加強(qiáng)發(fā)展的系統(tǒng)性、市場(chǎng)前瞻性、產(chǎn)品創(chuàng)新能力,以專注、極致的服務(wù)理念,為客戶提供成都網(wǎng)站設(shè)計(jì)、成都網(wǎng)站制作 網(wǎng)站設(shè)計(jì)制作按需設(shè)計(jì)網(wǎng)站,公司網(wǎng)站建設(shè),企業(yè)網(wǎng)站建設(shè),成都品牌網(wǎng)站建設(shè),營(yíng)銷型網(wǎng)站建設(shè),外貿(mào)網(wǎng)站建設(shè),象州網(wǎng)站建設(shè)費(fèi)用合理。
MHA里有兩個(gè)角色一個(gè)是MHA Node(數(shù)據(jù)節(jié)點(diǎn))另一個(gè)是MHA Manager(管理節(jié)點(diǎn))。
MHA Manager可以單獨(dú)部署在一臺(tái)獨(dú)立的機(jī)器上管理多個(gè)master-slave集群,也可以部署在一臺(tái)slave節(jié)點(diǎn)上。MHA Node運(yùn)行在每臺(tái)MySQL服務(wù)器上,MHA Manager會(huì)定時(shí)探測(cè)集群中的master節(jié)點(diǎn),當(dāng)master出現(xiàn)故障時(shí),它可以自動(dòng)將最新數(shù)據(jù)的slave提升為新的master,然后將所有其他的slave重新指向新的master。整個(gè)故障轉(zhuǎn)移過程對(duì)應(yīng)用程序完全透明。

在MHA自動(dòng)故障切換過程中,MHA試圖從宕機(jī)的主服務(wù)器上保存二進(jìn)制日志,最大程度的保證數(shù)據(jù)的不丟失,但這并不總是可行的。例如,如果主服務(wù)器硬件故障或無法通過ssh訪問,MHA沒法保存二進(jìn)制日志,只進(jìn)行故障轉(zhuǎn)移而丟失了最新的數(shù)據(jù)。使用MySQL 5.5的半同步復(fù)制,可以大大降低數(shù)據(jù)丟失的風(fēng)險(xiǎn)。MHA可以與半同步復(fù)制結(jié)合起來。如果只有一個(gè)slave已經(jīng)收到了最新的二進(jìn)制日志,MHA可以將最新的二進(jìn)制日志應(yīng)用于其他所有的slave服務(wù)器上,因此可以保證所有節(jié)點(diǎn)的數(shù)據(jù)一致性。
注:從MySQL5.5開始,MySQL以插件的形式支持半同步復(fù)制。如何理解半同步呢?首先我們來看看異步,全同步的概念:
異步復(fù)制(Asynchronous replication)
MySQL默認(rèn)的復(fù)制即是異步的,主庫(kù)在執(zhí)行完客戶端提交的事務(wù)后會(huì)立即將結(jié)果返給給客戶端,并不關(guān)心從庫(kù)是否已經(jīng)接收并處理,這樣就會(huì)有一個(gè)問題,主如果crash掉了,此時(shí)主上已經(jīng)提交的事務(wù)可能并沒有傳到從上,如果此時(shí),強(qiáng)行將從提升為主,可能導(dǎo)致新主上的數(shù)據(jù)不完整。
全同步復(fù)制(Fully synchronous replication)
指當(dāng)主庫(kù)執(zhí)行完一個(gè)事務(wù),所有的從庫(kù)都執(zhí)行了該事務(wù)才返回給客戶端。因?yàn)樾枰却袕膸?kù)執(zhí)行完該事務(wù)才能返回,所以全同步復(fù)制的性能必然會(huì)受到嚴(yán)重的影響。
半同步復(fù)制(Semisynchronous replication)
介于異步復(fù)制和全同步復(fù)制之間,主庫(kù)在執(zhí)行完客戶端提交的事務(wù)后不是立刻返回給客戶端,而是等待至少一個(gè)從庫(kù)接收到并寫到relay log中才返回給客戶端。相對(duì)于異步復(fù)制,半同步復(fù)制提高了數(shù)據(jù)的安全性,同時(shí)它也造成了一定程度的延遲,這個(gè)延遲最少是一個(gè)TCP/IP往返的時(shí)間。所以,半同步復(fù)制最好在低延時(shí)的網(wǎng)絡(luò)中使用。
下面來看看半同步復(fù)制的原理圖:
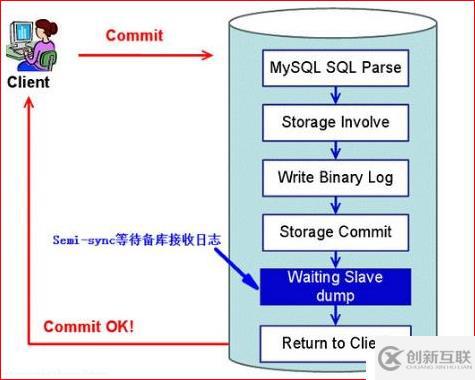
總結(jié):異步與半同步異同
默認(rèn)情況下MySQL的復(fù)制是異步的,Master上所有的更新操作寫入Binlog之后并不確保所有的更新都被復(fù)制到Slave之上。異步操作雖然效率高,但是在Master/Slave出現(xiàn)問題的時(shí)候,存在很高數(shù)據(jù)不同步的風(fēng)險(xiǎn),甚至可能丟失數(shù)據(jù)。
MySQL5.5引入半同步復(fù)制功能的目的是為了保證在master出問題的時(shí)候,至少有一臺(tái)Slave的數(shù)據(jù)是完整的。在超時(shí)的情況下也可以臨時(shí)轉(zhuǎn)入異步復(fù)制,保障業(yè)務(wù)的正常使用,直到一臺(tái)salve追趕上之后,繼續(xù)切換到半同步模式。
工作原理:
相較于其它HA軟件,MHA的目的在于維持MySQL Replication中Master庫(kù)的高可用性,其最大特點(diǎn)是可以修復(fù)多個(gè)Slave之間的差異日志,最終使所有Slave保持?jǐn)?shù)據(jù)一致,然后從中選擇一個(gè)充當(dāng)新的Master,并將其它Slave指向它。
-從宕機(jī)崩潰的master保存二進(jìn)制日志事件(binlogevents)。
-識(shí)別含有最新更新的slave。
-應(yīng)用差異的中繼日志(relay log)到其它slave。
-應(yīng)用從master保存的二進(jìn)制日志事件(binlogevents)。
-提升一個(gè)slave為新master。
-使其它的slave連接新的master進(jìn)行復(fù)制。
目前MHA主要支持一主多從的架構(gòu),要搭建MHA,要求一個(gè)復(fù)制集群中必須最少有三臺(tái)數(shù)據(jù)庫(kù)服務(wù)器,一主二從,即一臺(tái)充當(dāng)master,一臺(tái)充當(dāng)備用master,另外一臺(tái)充當(dāng)從庫(kù),因?yàn)橹辽傩枰_(tái)服務(wù)器。
部署環(huán)境如下:
| 角色 | Ip | 主機(jī)名 | os |
| master | 192.168.137.134 | master | centos 6.5 x86_64 |
| Candidate | 192.168.137.130 | Candidate | |
| slave+manage | 192.168.137.146 | slave |
其中master對(duì)外提供寫服務(wù),Candidate為備選master,管理節(jié)點(diǎn)放在純slave機(jī)器上。master一旦宕機(jī),Candidate提升為主庫(kù)
一、基礎(chǔ)環(huán)境準(zhǔn)備
1、在3臺(tái)機(jī)器上配置epel源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
2、建立ssh無交互登錄環(huán)境,
[root@master ~]#ssh-keygen -t rsa -P ''
chmod 600 .ssh/*
cat .ssh/id_rsa.pub >.ssh/authorized_keys
scp -p .ssh/id_rsa .ssh/authorized_keys 192.168.137.130:/root/.ssh
scp -p .ssh/id_rsa .ssh/authorized_keys 192.168.137.146:/root/.ssh
二、配置mysql半同步復(fù)制
注意:mysql主從復(fù)制操作此處不做演示
master授權(quán):
grant replication slave,replication client on *.* to 'repl'@'192.168.137.%' identified by '123456';
grant all on *.* to 'mhauser'@'192.168.137.%' identified by '123456';
Candidate授權(quán):
grant replication slave,replication client on *.* to 'repl'@'192.168.137.%' identified by '123456';
grant all on *.* to 'mhauser'@'192.168.137.%' identified by '123456';
slave授權(quán):
grant all on *.* to 'mhauser'@'192.168.137.%' identified by '123456';
如果用mysql默認(rèn)的異步模式,當(dāng)主庫(kù)硬件損壞宕機(jī)造成的數(shù)據(jù)丟失,因此在配置MHA的同時(shí)建議配置成MySQL的半同步復(fù)制。
注:mysql半同步插件是由谷歌提供,具體位置/usr/local/mysql/lib/plugin/下,一個(gè)是master用的semisync_master.so,一個(gè)是slave用的semisync_slave.so,
mysql> show variables like '%plugin_dir%';
+---------------+------------------------------+
| Variable_name | Value |
+---------------+------------------------------+
| plugin_dir | /usr/local/mysql/lib/plugin/ |
+---------------+------------------------------+
1、分別在主從節(jié)點(diǎn)上安裝相關(guān)的插件(master,Candidate,slave)
在MySQL上安裝插件需要數(shù)據(jù)庫(kù)支持動(dòng)態(tài)載入。檢查是否支持,用如下檢測(cè):
mysql> show variables like '%have_dynamic_loading%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| have_dynamic_loading | YES
所有mysql數(shù)據(jù)庫(kù)服務(wù)器,安裝半同步插件(semisync_master.so,semisync_slave.so)
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
檢查Plugin是否已正確安裝:
mysql> show plugins;
或
mysql> select * from information_schema.plugins;
查看半同步相關(guān)信息
mysql> show variables like '%rpl_semi_sync%';
rpl_semi_sync_master_enabled | OFF |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32
上圖可以看到半同復(fù)制插件已經(jīng)安裝,只是還沒有啟用,所以是OFF
2、修改my.cnf文件,配置主從同步:
注:若主MYSQL服務(wù)器已經(jīng)存在,只是后期才搭建從MYSQL服務(wù)器,在置配數(shù)據(jù)同步前應(yīng)先將主MYSQL服務(wù)器的要同步的數(shù)據(jù)庫(kù)拷貝到從MYSQL服務(wù)器上(如先在主MYSQL上備份數(shù)據(jù)庫(kù),再用備份在從MYSQL服務(wù)器上恢復(fù))
master mysql主機(jī):
server-id = 1
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=10000
rpl_semi_sync_slave_enabled=1
relay_log_purge=0
relay-log= relay-bin
relay-log-index = relay-bin.index
注:
rpl_semi_sync_master_enabled=1 1表是啟用,0表示關(guān)閉
rpl_semi_sync_master_timeout=10000:毫秒單位,該參數(shù)主服務(wù)器等待確認(rèn)消息10秒后,不再等待,變?yōu)楫惒椒绞健?/p>
Candidate 主機(jī):
server-id = 2
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
relay_log_purge=0
relay-log= relay-bin
relay-log-index = slave-relay-bin.index
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=10000
rpl_semi_sync_slave_enabled=1
注:relay_log_purge=0,禁止 SQL 線程在執(zhí)行完一個(gè) relay log 后自動(dòng)將其刪除,對(duì)于MHA場(chǎng)景下,對(duì)于某些滯后從庫(kù)的恢復(fù)依賴于其他從庫(kù)的relaylog,因此采取禁用自動(dòng)刪除功能
Slave主機(jī):
Server-id = 3
log-bin = mysql-bin
relay-log = relay-bin
relay-log-index = slave-relay-bin.index
read_only = 1
rpl_semi_sync_slave_enabled = 1
查看半同步相關(guān)信息
mysql> show variables like '%rpl_semi_sync%';
查看半同步狀態(tài):
mysql> show status like '%rpl_semi_sync%';
| Rpl_semi_sync_master_clients | 2 |
重點(diǎn)關(guān)注的參數(shù):
rpl_semi_sync_master_status :顯示主服務(wù)是異步復(fù)制模式還是半同步復(fù)制模式
rpl_semi_sync_master_clients :顯示有多少個(gè)從服務(wù)器配置為半同步復(fù)制模式
rpl_semi_sync_master_yes_tx :顯示從服務(wù)器確認(rèn)成功提交的數(shù)量
rpl_semi_sync_master_no_tx :顯示從服務(wù)器確認(rèn)不成功提交的數(shù)量
rpl_semi_sync_master_tx_avg_wait_time :事務(wù)因開啟 semi_sync ,平均需要額外等待的時(shí)間
rpl_semi_sync_master_net_avg_wait_time :事務(wù)進(jìn)入等待隊(duì)列后,到網(wǎng)絡(luò)平均等待時(shí)間
三、配置mysql-mha
所有mysql節(jié)點(diǎn)安裝
rpm -ivh perl-DBD-MySQL-4.013-3.el6.i686.rpm [yum -y install perl-DBD-MySQL]
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
2. manage需安裝依賴的perl包
rpm -ivh perl-Config-Tiny-2.12-7.1.el6.noarch.rpm
rpm -ivh perl-DBD-MySQL-4.013-3.el6.i686.rpm [yum -y install perl-DBD-MySQL]
rpm -ivh compat-db43-4.3.29-15.el6.x86_64.rpm
rpm -ivh perl-Mail-Sender-0.8.16-3.el6.noarch.rpm
rpm -ivh perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm
rpm -ivh perl-TimeDate-1.16-11.1.el6.noarch.rpm
rpm -ivh perl-MIME-Types-1.28-2.el6.noarch.rpm
rpm -ivh perl-MailTools-2.04-4.el6.noarch.rpm
rpm -ivh perl-Email-Date-Format-1.002-5.el6.noarch.rpm
rpm -ivh perl-Params-Validate-0.92-3.el6.x86_64.rpm
rpm -ivh perl-Params-Validate-0.92-3.el6.x86_64.rpm
rpm -ivh perl-MIME-Lite-3.027-2.el6.noarch.rpm
rpm -ivh perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
rpm -ivh perl-Log-Dispatch-2.27-1.el6.noarch.rpm
yum install -y perl-Time-HiRes-1.9721-144.el6.x86_64
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
3. 配置mha
配置文件位于管理節(jié)點(diǎn),通常包括每一個(gè)mysql server的主機(jī)名,mysql用戶名,密碼,工作目錄等等。
mkdir /etc/masterha/
vim /etc/masterha/app1.cnf
[server default]
user=mhauser
password=123456
manager_workdir=/data/masterha/app1
manager_log=/data/masterha/app1/manager.log
remote_workdir=/data/masterha/app1
ssh_user=root
repl_user=repl
repl_password=123456
ping_interval=1
[server1]
hostname=192.168.137.134
port=3306
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server2]
hostname=192.168.137.130
port=3306
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server3]
hostname=192.168.137.146
port=3306
master_binlog_dir=/usr/local/mysql/data
no_master=1
配關(guān)配置項(xiàng)的解釋:
manager_workdir=/masterha/app1//設(shè)置manager的工作目錄
manager_log=/masterha/app1/manager.log//設(shè)置manager的日志
user=manager//設(shè)置監(jiān)控用戶manager
password=123456 //監(jiān)控用戶manager的密碼
ssh_user=root //ssh連接用戶
repl_user=mharep //主從復(fù)制用戶
repl_password=123.abc//主從復(fù)制用戶密碼
ping_interval=1 //設(shè)置監(jiān)控主庫(kù),發(fā)送ping包的時(shí)間間隔,默認(rèn)是3秒,嘗試三次沒有回應(yīng)的時(shí)候自動(dòng)進(jìn)行failover
master_binlog_dir=/usr/local/mysql/data //設(shè)置master 保存binlog的位置,以便MHA可以找到master的日志,我這里的也就是mysql的數(shù)據(jù)目錄
candidate_master=1//設(shè)置為候選master,如果設(shè)置該參數(shù)以后,發(fā)生主從切換以后將會(huì)將此從庫(kù)提升為主庫(kù)。
檢測(cè)各節(jié)點(diǎn)間ssh互信通信配置是否ok
masterha_check_ssh --conf=/etc/masterha/app1.cnf
結(jié)果:All SSH connection tests passed successfully.
檢測(cè)各節(jié)點(diǎn)間主從復(fù)制是否ok
masterha_check_repl --conf=/etc/masterha/app1.cnf
結(jié)果:MySQL Replication Health is OK.
在驗(yàn)證時(shí),若遇到這個(gè)錯(cuò)誤:Can't exec "mysqlbinlog" ......
解決方法是在所有服務(wù)器上執(zhí)行:
ln -s /usr/local/mysql/bin/* /usr/local/bin/
啟動(dòng)manager:
nohup /usr/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover > /etc/masterha/manager.log 2>&1 &
--remove_dead_master_conf 為主從切換后,老的主庫(kù)IP將會(huì)從配置文件中移除
--ignore_last_failover 忽略生成的切換完成文件,若不忽略,則8小時(shí)內(nèi)無法再次切換
--ignore_fail_on_start
##當(dāng)有slave 節(jié)點(diǎn)宕掉時(shí),MHA默認(rèn)是啟動(dòng)不了的,加上此參數(shù)即使有節(jié)點(diǎn)宕掉也能啟動(dòng)MHA,
關(guān)閉MHA:
masterha_stop --conf=/etc/masterha/app1.cnf
查看MHA狀態(tài):
masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:45128) is running(0:PING_OK), master:192.168.137.134
4.模擬故障轉(zhuǎn)移
停掉master,
/etc/init.d/mysqld stop
查看 MHA 日志 /data/masterha/app1/manager.log
----- Failover Report -----
app1: MySQL Master failover 192.168.137.134(192.168.137.134:3306) to 192.168.137.1
30(192.168.137.130:3306) succeeded
Master 192.168.137.134(192.168.137.134:3306) is down!
Check MHA Manager logs at zifuji:/data/masterha/app1/manager.log for details.
Started automated(non-interactive) failover.
The latest slave 192.168.137.130(192.168.137.130:3306) has all relay logs for reco
very.
Selected 192.168.137.130(192.168.137.130:3306) as a new master.
192.168.137.130(192.168.137.130:3306): OK: Applying all logs succeeded.
192.168.137.146(192.168.137.146:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.137.146(192.168.137.146:3306): OK: Applying all logs succeeded. Slave star
ted, replicating from 192.168.137.130(192.168.137.130:3306)
192.168.137.130(192.168.137.130:3306): Resetting slave info succeeded.
Master failover to 192.168.137.130(192.168.137.130:3306) completed successfully.
3. 查看slave復(fù)制狀態(tài)
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.137.130
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
MHA Manager 端日常主要操作步驟
1)檢查是否有下列文件,有則刪除。
發(fā)生主從切換后,MHAmanager服務(wù)會(huì)自動(dòng)停掉,且在manager_workdir(/data/masterha/app1/app1.failover.complete)目錄下面生成文件app1.failover.complete,若要啟動(dòng)MHA,必須先確保無此文件)
find / -name 'app1.failover.complete'
rm -f /data/masterha/app1/app1.failover.complete
2)檢查MHA當(dāng)前置:
# masterha_check_repl --conf=/etc/masterha/app1.cnf
3)啟動(dòng)MHA:
#nohup masterha_manager --conf=/etc/masterha/app1.cnf&>/etc/masterha/manager.log &
當(dāng)有slave 節(jié)點(diǎn)宕掉時(shí),默認(rèn)是啟動(dòng)不了的,加上 --ignore_fail_on_start即使有節(jié)點(diǎn)宕掉也能啟動(dòng)MHA,如下:
#nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_fail_on_start&>/etc/masterha/manager.log &
4)停止MHA: masterha_stop --conf=/etc/masterha/app1.cnf
5)檢查狀態(tài):
# masterha_check_status --conf=/etc/masterha/app1.cnf
6)檢查日志:
#tail -f /etc/masterha/manager.log
7)主從切換,原主庫(kù)后續(xù)工作
vim /etc/my.cnf
read_only=ON
relay_log_purge = 0
mysql> reset slave all;
mysql> reset master;
/etc/init.d/mysqld restart
mysql> CHANGE MASTER TO MASTER_HOST='192.168.137.130',MASTER_USER='repl',MASTER_PASSWORD='123456';
##與新主庫(kù)做主從復(fù)制
masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:45950) is running(0:PING_OK), master:192.168.137.130
注意:如果正常,會(huì)顯示"PING_OK",否則會(huì)顯示"NOT_RUNNING",這代表MHA監(jiān)控沒有開啟。
定期刪除中繼日志
在配置主從復(fù)制中,slave上設(shè)置了參數(shù)relay_log_purge=0,所以slave節(jié)點(diǎn)需要定期刪除中繼日志,建議每個(gè)slave節(jié)點(diǎn)刪除中繼日志的時(shí)間錯(cuò)開。
corntab -e
0 5 * * * /usr/local/bin/purge_relay_logs - -user=root --password=pwd123 --port=3306 --disable_relay_log_purge >>/var/log/purge_relay.log 2>&1
5、配置VIP
ip配置可以采用兩種方式,一種通過keepalived的方式管理虛擬ip的浮動(dòng);另外一種通過腳本方式啟動(dòng)虛擬ip的方式(即不需要keepalived或者h(yuǎn)eartbeat類似的軟件)。
1、keepalived方式管理虛擬ip,keepalived配置方法如下:
在master和Candidate主機(jī)上安裝keepalived
安裝依賴包:
[root@master ~]# yum install openssl-devel libnfnetlink-devel libnfnetlink popt-devel kernel-devel -y
wget http://www.keepalived.org/software/keepalived-1.2.20.tar.gz
ln -s /usr/src/kernels/2.6.32-642.1.1.el6.x86_64 /usr/src/linux
tar -xzf keepalived-1.2.20.tar.gz;cd keepalived-1.2.20
./configure --prefix=/usr/local/keepalived;make && make install
ln -s /usr/local/keepalived/sbin/keepalived /usr/bin/keepalived
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/keepalived
mkdir /etc/keepalived
ln -s /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf
chmod 755 /etc/init.d/keepalived
chkconfig --add keepalived
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
service keepalived restart
echo 1 > /proc/sys/net/ipv4/ip_forward
修改Keepalived的配置文件(在master上配置)
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
guopeng@163.com
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id mysql-ha1
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.137.100
}
}
在候選master(Candidate)上配置
[root@Candidate keepalived-1.2.20]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id mysql-ha2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.137.100
}
}
啟動(dòng)keepalived服務(wù),在master上啟動(dòng)并查看日志
/etc/init.d/keepalived start
tail -f/var/log/messages
Aug 14 01:05:25 minion Keepalived_vrrp[39720]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.137.100
[root@master ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:57:66:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.134/24 brd 192.168.137.255 scope global eth0
inet 192.168.137.100/32 scope global eth0
inet6 fe80::20c:29ff:fe57:6649/64 scope link
valid_lft forever preferred_lft forever
[root@Candidate ~]# ip addr show dev eth0 ##此時(shí)備選master上是沒有虛擬ip的
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:a5:b4:85 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.130/24 brd 192.168.137.255 scope global eth0
inet6 fe80::20c:29ff:fea5:b485/64 scope link
valid_lft forever preferred_lft forever
注意:
上面兩臺(tái)服務(wù)器的keepalived都設(shè)置為了BACKUP模式,在keepalived中2種模式,分別是master->backup模式和backup->backup模式。這兩種模式有很大區(qū)別。在master->backup模式下,一旦主庫(kù)宕機(jī),虛擬ip會(huì)自動(dòng)漂移到從庫(kù),當(dāng)主庫(kù)修復(fù)后,keepalived啟動(dòng)后,還會(huì)把虛擬ip搶占過來,即使設(shè)置了非搶占模式(nopreempt)搶占ip的動(dòng)作也會(huì)發(fā)生。在backup->backup模式下,當(dāng)主庫(kù)宕機(jī)后虛擬ip會(huì)自動(dòng)漂移到從庫(kù)上,當(dāng)原主庫(kù)恢復(fù)和keepalived服務(wù)啟動(dòng)后,并不會(huì)搶占新主的虛擬ip,即使是優(yōu)先級(jí)高于從庫(kù)的優(yōu)先級(jí)別,也不會(huì)發(fā)生搶占。為了減少ip漂移次數(shù),通常是把修復(fù)好的主庫(kù)當(dāng)做新的備庫(kù)。
2、MHA引入keepalived(MySQL服務(wù)進(jìn)程掛掉時(shí)通過MHA 停止keepalived):
要想把keepalived服務(wù)引入MHA,我們只需要修改切換時(shí)觸發(fā)的腳本文件master_ip_failover即可,在該腳本中添加在master發(fā)生宕機(jī)時(shí)對(duì)keepalived的處理。
編輯腳本/scripts/master_ip_failover,修改后如下。
manager編輯腳本文件:
mkdir /scripts
vim /scripts/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '192.168.137.100';
my $ssh_start_vip = "/etc/init.d/keepalived start";
my $ssh_stop_vip = "/etc/init.d/keepalived stop";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host
";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_h
ost=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_
master_ip=ip --new_master_port=port\n";
}
現(xiàn)在已經(jīng)修改這個(gè)腳本了,接下來我們?cè)?etc/masterha/app1.cnf 中調(diào)用故障切換腳本
停止MHA:
masterha_stop --conf=/etc/masterha/app1.cnf
在配置文件/etc/masterha/app1.cnf 中啟用下面的參數(shù)(在[server default下面添加])
master_ip_failover_script=/scripts/master_ip_failover
啟動(dòng)MHA:
#nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/etc/masterha/manager.log &
檢查狀態(tài):
]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:51284) is running(0:PING_OK), master:192.168.137.134
檢查集群復(fù)制狀態(tài)是否有報(bào)錯(cuò):
]# masterha_check_repl --conf=/etc/masterha/app1.cnf
192.168.137.134(192.168.137.134:3306) (current master)
+--192.168.137.130(192.168.137.130:3306)
+--192.168.137.146(192.168.137.146:3306)
Tue May 9 14:40:57 2017 - [info] Checking replication health on 192.168.137.130..
Tue May 9 14:40:57 2017 - [info] ok.
Tue May 9 14:40:57 2017 - [info] Checking replication health on 192.168.137.146..
Tue May 9 14:40:57 2017 - [info] ok.
Tue May 9 14:40:57 2017 - [info] Checking master_ip_failover_script status:
Tue May 9 14:40:57 2017 - [info] /scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.134 --orig_master_ip=192.168.137.134 --orig_master_port=3306
IN SCRIPT TEST====/etc/init.d/keepalived stop==/etc/init.d/keepalived start===
Checking the Status of the script.. OK
Tue May 9 14:40:57 2017 - [info] OK.
Tue May 9 14:40:57 2017 - [warning] shutdown_script is not defined.
Tue May 9 14:40:57 2017 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
注意: /scripts/master_ip_failover添加或者修改的內(nèi)容意思是當(dāng)主庫(kù)數(shù)據(jù)庫(kù)發(fā)生故障時(shí),會(huì)觸發(fā)MHA切換,MHA Manager會(huì)停掉主庫(kù)上的keepalived服務(wù),觸發(fā)虛擬ip漂移到備選從庫(kù),從而完成切換。
當(dāng)然可以在keepalived里面引入腳本,這個(gè)腳本監(jiān)控mysql是否正常運(yùn)行,如果不正常,則調(diào)用該腳本殺掉keepalived進(jìn)程(參考MySQL 高可用性keepalived+mysql雙主)。
測(cè)試:在master上停掉mysql
[root@master ~]# /etc/init.d/mysqld stop
Shutting down MySQL............ [ OK ]
到slave(192.168.137.146)查看slave的狀態(tài):
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.137.130
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
從上圖可以看出slave指向了新的master服務(wù)器192.168.137.130(在故障切換前指向的是192.168.137.134)
查看vip綁定:
在192.168.137.134上查看vip綁定
[root@master ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:57:66:49 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.134/24 brd 192.168.137.255 scope global eth0
inet6 fe80::20c:29ff:fe57:6649/64 scope link
valid_lft forever preferred_lft forever
在192.168.137.130上查看vip綁定
[root@Candidate ~]# ip addr show dev eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:a5:b4:85 brd ff:ff:ff:ff:ff:ff
inet 192.168.137.130/24 brd 192.168.137.255 scope global eth0
inet 192.168.137.100/32 scope global eth0
從上面的顯示結(jié)果可以看出vip地址漂移到了192.168.137.130
主從切換后續(xù)工作:現(xiàn)在Candidate變成主,需對(duì)原master重新做只從復(fù)制操作
修復(fù)成從庫(kù)
啟動(dòng)keepalived
rm -fr app1.failover.complete
啟動(dòng)manager
3、通過腳本實(shí)現(xiàn)VIP切換
如果使用腳本管理vip的話,需要手動(dòng)在master服務(wù)器上綁定一個(gè)vip
]#/sbin/ifconfig eth0:0 192.168.137.100/24
vim /scripts/master_ip_failover
my $vip = '192.168.137.100/24';
my $key = '0';
my $ssh_start_vip = "/sbin/ifconfigeth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfigeth0:$key down";
之后的操作同上述keepalived操作
為了防止腦裂發(fā)生,推薦生產(chǎn)環(huán)境采用腳本的方式來管理虛擬ip,而不是使用keepalived來完成。到此為止,基本MHA集群已經(jīng)配置完畢。
分享文章:MySQL高可用集群架構(gòu)MHA
路徑分享:http://vcdvsql.cn/article22/gjgdcc.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供品牌網(wǎng)站建設(shè)、做網(wǎng)站、網(wǎng)站收錄、網(wǎng)站排名、網(wǎng)站建設(shè)、虛擬主機(jī)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)

- 成都考研刷題小程序開發(fā) 2022-06-14
- 微信小程序開發(fā)流程分為那幾個(gè)階段呢 2021-11-06
- 成都小程序APP商城定制開發(fā)制作方案 2017-03-09
- 江西小程序開發(fā)一定要注意哪些事情? 2020-12-13
- 成都小程序開發(fā),如何選擇SSL證書 2022-07-05
- 手機(jī)的NFC功能成就了很多微信小程序開發(fā) 2013-05-17
- 小程序都有什么推廣方式? 2015-08-29
- 小程序開發(fā):可以吸引到哪些新客戶? 2021-02-19
- 小程序開發(fā)對(duì)于企業(yè)有何作用 2021-02-15
- 2015-2016小程序從爆款到明年趨勢(shì),全盤點(diǎn)! 2016-07-28
- 拼團(tuán)小程序開發(fā),拼團(tuán)小程序功能 2022-11-21
- 你必須了解的三大企業(yè)微信小程序開發(fā)要求 2021-02-04