如何利用python的KMeans和PCA包實現聚類算法-創新互聯
如何利用python的KMeans和PCA包實現聚類算法,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
成都創新互聯成立于2013年,先為雙牌等服務建站,雙牌等地企業,進行企業商務咨詢服務。為雙牌企業網站制作PC+手機+微官網三網同步一站式服務解決您的所有建站問題。題目: 通過給出的駕駛員行為數據(trip.csv),對駕駛員不同時段的駕駛類型進行聚類,聚成普通駕駛類型,激進類型和超冷靜型3類 。 利用Python的scikit-learn包中的Kmeans算法進行聚類算法的應用練習。并利用scikit-learn包中的PCA算法來對聚類后的數據進行降維,然后畫圖展示出聚類效果。通過調節聚類算法的參數,來觀察聚類效果的變化,練習調參。
數據介紹: 選取某一個駕駛員的經過處理的數據集trip.csv,將該駕駛人的各個時間段的特征進行聚類。(注:其中的driver 和trip_no 不參與聚類)
字段介紹: driver :駕駛員編號;trip_no:trip編號;v_avg:平均速度;v_var:速度的方差;a_avg:平均加速度;a_var:加速度的方差;r_avg:平均轉速;r_var:轉速的方差; v_a:速度level為a時的時間占比(同理v_b , v_c , v_d ); a_a:加速度level為a時的時間占比(同理a_b, a_c); r_a:轉速level為a時的時間占比( r_b, r_c)
聚類算法要求:
(1)統計各個類別的數目
(2)找出聚類中心
(3)將每條數據聚成的類別(該列命名為jllable )和原始數據集進行合并,形成新的dataframe,命名為new_df ,并輸出到本地,命名為new_df.csv。
降維算法要求:
(1)將用于聚類的數據的特征的維度降至2維,并輸出降維后的數據,形成一個dataframe名字new_pca
(2)畫圖來展示聚類效果(可用如下代碼):
import matplotlib.pyplot asplt
d = new_pca[new_df['jllable'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['jllable'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['jllable'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('D:/workspace/python/Practice/ddsx/kmeans.png')
plt.show()
python實現代碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
運行結果如下:
##各個類別的數目
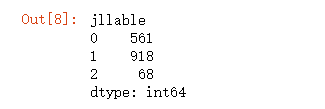
##聚類中心

##新的dataframe,命名為new_df ,并輸出到本地,命名為new_df.csv。

##可視化------kmeans.png
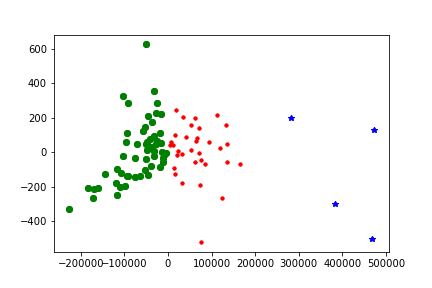
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注創新互聯-成都網站建設公司行業資訊頻道,感謝您對創新互聯的支持。
分享名稱:如何利用python的KMeans和PCA包實現聚類算法-創新互聯
文章出自:http://vcdvsql.cn/article34/cdipse.html
成都網站建設公司_創新互聯,為您提供建站公司、服務器托管、網站收錄、企業網站制作、微信公眾號、網站策劃
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 響應式網站建設之視覺設計原則 2022-07-22
- 您需要知道的關于響應式網站設計的一切 2019-06-03
- 手機響應式網站布局很重要 2014-06-10
- 響應式網站設計的的延續性 2019-01-05
- 響應式網站設計中的4個難點 2013-08-31
- 響應式網站常見的幾個設計問題探討 2023-03-16
- 響應式網站設計到底改變了什么 2021-05-07
- 企業建設響應式網站帶來的五大好處 2016-05-17
- Html5響應式網站模板怎么設計制作? 2021-02-15
- 響應式網站在網站制作上有哪些不足? 2023-01-21
- 在用戶體驗上響應式網站有哪些優點 2022-08-14
- 為什么響應式網站建設比較貴? 2022-07-28