django索引的示例分析-創新互聯
小編給大家分享一下django索引的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!

前言
由于數據庫每天都用來存儲越來越多的信息,因此這些也是每個Django項目中的關鍵組件。 因此了解它們的工作方式非常重要。
當然,我無法解釋所有可用于Django的不同數據庫的全部細節。 不僅如此,因為我不知道這一切,但也因為這會造成一場談話。 或者可能是整個會議。
關于數據庫的理論背景我唯一想說的是,有一種叫做“關系代數”的東西。 用你可能想出的每 一條SELECT語句都可以表達出來。 數學證明。
數據庫查找如何工作
相反,讓我們從數據庫查找的工作方式開始。 因為那是我們最多的時間。
假設我們有這個數據庫的人名表及其相應的年齡,當他們開始編程時。
現在我們要選擇每個19歲開始的人。
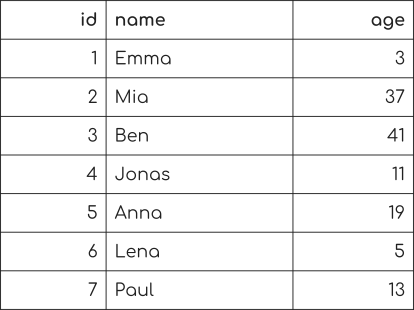
我們可以用SQL查詢來表達:
SELECT * FROM people WHERE age = 19
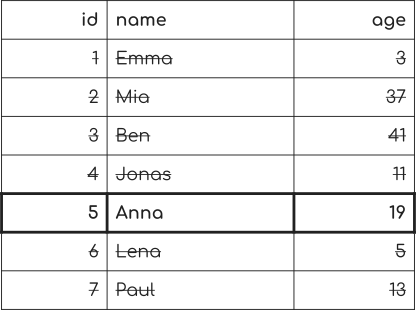
現在,我們如何找到每個人匹配該查詢?
表掃描查找
那么,這很容易。 我們只查看表中的每一行,檢查條件是否適用,如果是,則返回該行。
這被稱為“全表掃描”
到現在為止還挺好。 我們在這里有7排。 因此我們看7行。 這是少量的行,所以查詢速度很快。
但是想象一下,你有10萬,1億,100億甚至更多的行。 遍歷每一行可能非常耗時。 這不是我們想要的或我們可以負擔得起的東西。 我們希望能夠提供有保證的時機來查找特定行。 與行數無關。
這是索引加入派對的地方。
什么是索引?
對于數量不斷增加的數據,索引可以快速訪問單個(或多個)項目,而不會減少很多速度。 這也被稱為“隨機訪問”。 你會看到為什么這樣叫。 但首先讓我們看看現代數據庫系統中最常見的索引類型。
B-Trees / B +樹
目前最常見的索引是B-Tree索引。 或者更確切地說,B +樹索引。
它們或者以其發明者之一Rudolf Bayer命名,或者因為他們自我平衡。 這不是很清楚,但也并不重要。 自我平衡意味著樹木有一定的時間保證:對于B樹最有意思的是,索引的大小并不重要,對于任何相同大小的索引,時間將是相同的。 你也會看到這一點。
就像所有的樹(無論是在計算機科學還是在自然界中),你都以一個根開始。 計算機科學與自然的區別在于,在計算機科學中,我們把樹的根部放在頂部。
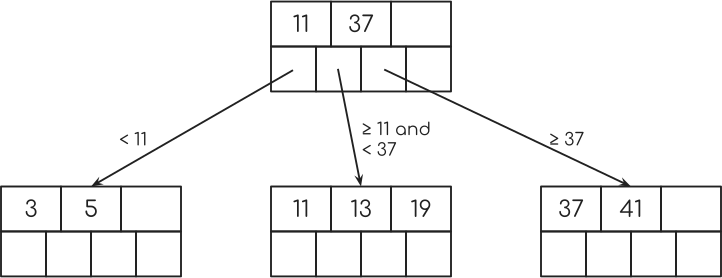
隨你。 這是3級B +樹的根音。
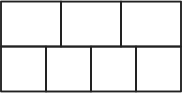
等級3意味著,這個節點可以有3個鍵。 這就是該節點頂部的3個盒子的用途。 下面的4個盒子保存指向另一個節點的指針或數據庫表中的一行。
現在,假設您在此節點中具有密鑰11和37,并且您沒有第三個密鑰。
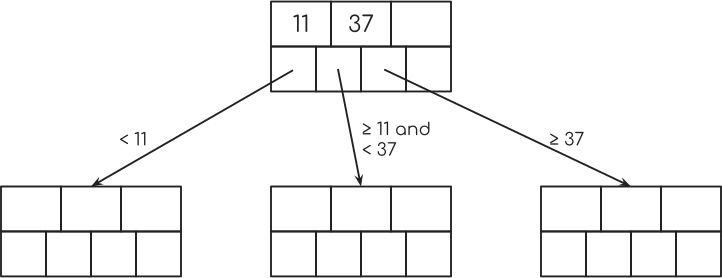
然后最左邊的指針指向一個節點的鍵小于11.第二個指針指向一個節點,其鍵大于或等于11,小于37.第三個指針指向一個鍵大于或等于37的節點。
從我在開始時顯示的表格的年齡欄索引中,可以看起來像這樣。
現在的魔法就是第二行節點中的指針。 它們中的每一個指向表中具有特定鍵的單個行,在我們的示例中,這是年齡。
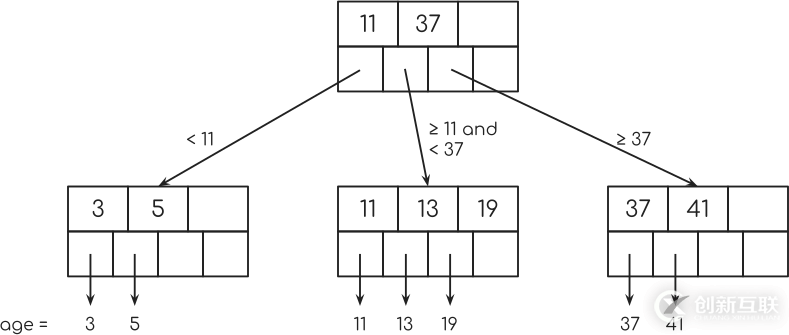
但不只是這個。
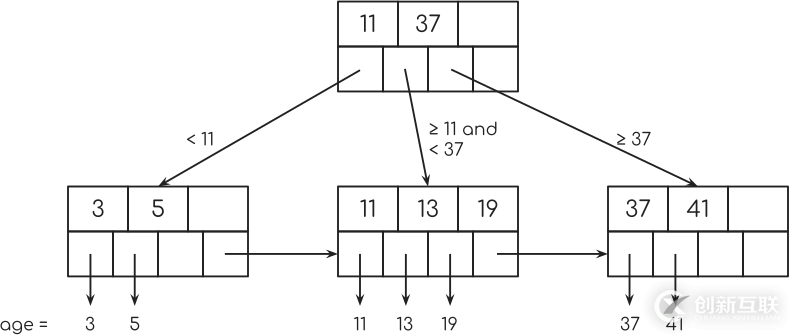
您會看到每個底層節點中的最后一個指針如何指向下一個節點? 這用于“索引掃描”。 我會在稍后回來。
我們來更詳細地看看第二排節點。
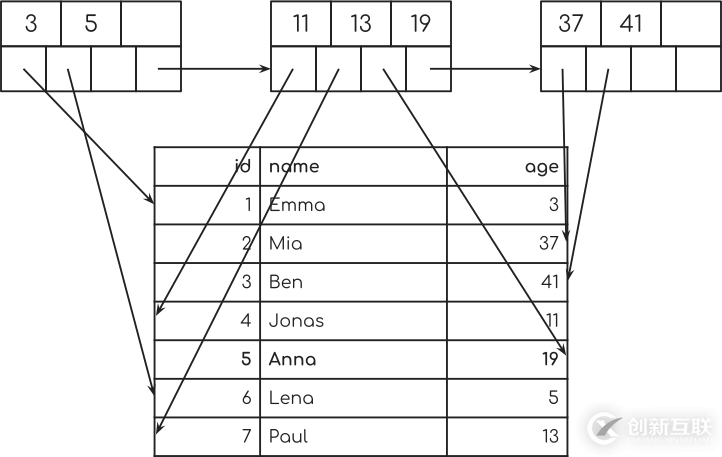
您現在可以看到,來自其中一個樹節點的每個指針如何指向表中的單個行。
您還可以看到來自樹節點的這些指針如何隨機地指向表中的某些行。 這就是為什么這被稱為“隨機訪問”。 數據庫隨機在數據庫表中跳轉。
隨機訪問查找
讓我們用我們之前的SQL查詢刷新我們的記憶。
SELECT * FROM people WHERE age = 19
現在索引如何幫助更快找到相應的行?
那么,讓我們看看樹:
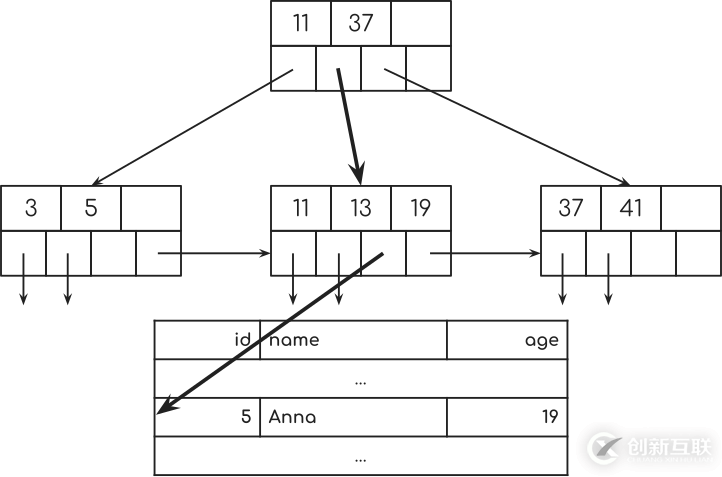
它需要1步從第一個節點到第二個節點。 并且從第二個節點到數據庫表中的行一秒鐘。
請記住,我們必須查看所有7行以查看它們是否與數據庫查詢匹配。
而且由于19個指數中沒有更多的關鍵,我們就完成了。
索引掃描
現在,回到“索引掃描”,假設你想要計算從5歲到13歲時開始編碼的人數。
SELECT COUNT(*) FROM people WHERE age BETWEEN 5 AND 19; SELECT COUNT(*) FROM people WHERE age >= 5 AND age <= 19;
數據庫將查找密鑰5,然后使用指向下一個節點的指針查找更多密鑰。
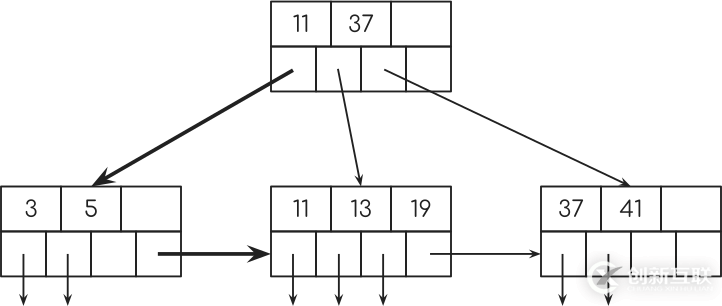
而且因為數據庫所需的所有查詢信息都在索引中,所以數據庫根本不會查看表。
索引非常棒
讓我們讓他們在Django。
實際上,我們已經做到了。
有
db_index = True ,您可以在模型字段上設置
index_together =(('name', 'age'),)你可以在模型的Meta類中設置
ForeignKey() / OneToOneField()使用索引快速查找相關表中的數據
primary_key = True ,Django自動使用AutoField表示每個模型上的id列。
這已經很棒了。 但是這個功能集有點限制。 那里不僅有B +樹索引。 還有一噸多
2016
我們來看看2016年。
馬克·坦林和我有索引的想法。 實際上,Marc在他的contrib.postgres工作中已經有了一些想法。 我們有關于API的想法。 我們希望在Django中擁有的東西。 像,讓我們讓Django支持所有的索引 。
但是我們沒有時間去實現我們的想法!
但我們很幸運。 事實上,Django項目很幸運。
Google Summer of Code 2016
Django再次被接受為Google Summer of Code的組織。 謝謝Google!
對于那些不知道這是什么的人:谷歌支付學生3個月的時間在開源項目上工作,同時由項目貢獻者進行指導。
大多數情況下, Tim Graham ,還有Marc和我輔導學生Akshesh Doshi在Django中處理更通用的索引支持。 從寫下API等提議,直到最終合并到Django中。
GSoC 2016的主要成果是django.db.models.indexes.Index(fields,name) ( docs )
它定義了所有索引的基類。 您可以通過模型的Meta類中的索引選項使用它們。
例如像這樣:
from django.db import models class Person(models.Model): name = models.CharField(max_length=200) class Meta: indexes = [ models.Index( fields=['name'], name='name_idx', ), ]
這將在數據庫表的名稱列上創建一個B +樹索引。
當然,這并不是什么新鮮事。 這就是在名稱字段中使用db_index = True時可以執行的操作。
您當然也可以在多列上定義索引:
from django.db import models class Person(models.Model): name = models.CharField(max_length=200) age = models.PositiveSmallIntegerField() class Meta: indexes = [ models.Index( fields=['name', 'age'], name='name_age_idx', ), ]
當然,這也不是什么新東西。 你可以用index_together來完成。
但你現在也可以這樣做:
from django.contrib.postgres.fields import JSONField from django.contrib.postgres.indexes import GinIndex from django.db import models class Doc(models.Model): data = JSONField() class Meta: indexes = [ GinIndex( fields=['data'], name='data_gin', ), ]
定義一個GinIndex 。 這是PostgreSQL特有的。 但這是你以前無法做到的事情。 至少不可靠,沒有太多的痛苦。
GinIndex可用于索引JSON blob中的鍵值。 因此,您可以篩選表中JSONB字段中的鍵映射到特定值的表中的行。 這就像“NoSQL 1-0-1”。
Django 1.11附帶的另一種內置索引類型是BrinIndex ,簡單地說,它可以允許更快地計算聚合。 比如,找出每篇文章最后一次購買的時間。
而且由于索引是數據庫模式的一部分,顯然通過遷移來追蹤索引。 因此,當您運行python manage.py migrate時會創建索引:
BEGIN;
--
-- Create model Doc
--
CREATE TABLE "someapp_doc" (
"id" serial NOT NULL PRIMARY KEY,
"data" jsonb NOT NULL);
--
-- Create index data_gin on field(s) data of model doc
--
CREATE INDEX "data_gin" ON "someapp_doc" USING gin ("data");
COMMIT;特色創意
大。
這就是昨天發布的Django 1.11。
但是Django 2.0有什么用?
什么在地平線上?
我們最終想要什么?
功能索引
它們在各種情況下都很有用,在這種情況下,您不希望對原始值進行索引,但可以對其進行變化,例如字符串的小寫。 我已經在為此工作。 我還沒到。 我很想從理解表達式API的人那里獲得幫助。
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=200)
class Meta:
indexes = [
FuncIndex(
expression=Lower('name'),
name='name_lower_idx',
),
]db_index = <IndexClass>
如前所述,對單個列使用索引可能非常麻煩。 因此,讓我們支持Index類作為db_index的一個屬性。
from django.db import models class Author(models.Model): name = models.CharField( max_length=200, db_index=HashIndex )
對某些領域有一個B +樹是沒有意義的。 如前所示, GinIndex對于JSONField來說非常完美。 為什么不在db_index = True時使用每個字段類的default_index_class ?
from django.contrib.postgres.fields import JSONField from django.contrib.postgres.indexes import GinIndex from django.db import models # Somewhere in Django's JSONField implementation: # JSONField.default_index_class = GinIndex class Document(models.Model): data = JSONField(db_index=True)
重構index_together和db_index
這個比面向用戶更引人注目:
我可以想象, db_index和index_together在內部使用Model._meta.indexes可能是有意義的。 這是要調查的東西。
以上是“django索引的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注創新互聯成都網站設計公司行業資訊頻道!
另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
分享名稱:django索引的示例分析-創新互聯
網址分享:http://vcdvsql.cn/article36/ddhgpg.html
成都網站建設公司_創新互聯,為您提供定制網站、外貿網站建設、營銷型網站建設、網站導航、微信小程序、網站排名
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 品牌設計的植入-APP設計5 2022-05-30
- 專業的APP設計師告訴你,怎么做可以讓APP更“快”! 2016-11-11
- 電商APP設計時有哪些問題要注意 2016-11-05
- APP設計常見分割方式 2021-05-20
- Web版網站建設與APP設計之間的不同之處 2016-11-25
- APP設計師必知:用戶體驗十大原則! 2022-06-30
- 怎樣讓你的APP設計更具有吸引力? 2016-08-16
- 大勢所趨!十大令人振奮的移動端APP設計趨勢 2022-06-13
- APP設計容易忽視的問題 2022-06-30
- UI不得不知的app設計布局之道 2022-11-21
- 移動時代的APP設計怎樣做到極簡? 2017-01-24
- 在APP設計中如何正確管理滾動頁面 2016-12-16