ortshuffle有什么用
本篇內容介紹了“ort shuffle有什么用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
創新互聯是專業的青州網站建設公司,青州接單;提供成都網站制作、成都網站建設,網頁設計,網站設計,建網站,PHP網站建設等專業做網站服務;采用PHP框架,可快速的進行青州網站開發網頁制作和功能擴展;專業做搜索引擎喜愛的網站,專業的做網站團隊,希望更多企業前來合作!
spark實現了多種shuffle方法,通過 spark.shuffle.manager來確定。暫時總共有三種:hash shuffle、sort shuffle和tungsten-sort shuffle,從1.2.0開始默認為sort shuffle。
從1.2.0開始默認為sort shuffle(spark.shuffle.manager= sort),實現邏輯類似于Hadoop MapReduce,Hash Shuffle每一個reducers產生一個文件,但是Sort Shuffle只是產生一個按照reducer id排序可索引的文件,這樣,只需獲取有關文件中的相關數據塊的位置信息,并fseek就可以讀取指定reducer的數據。但對于rueducer數比較少的情況,Hash Shuffle明顯要比Sort Shuffle快,因此Sort Shuffle有個“fallback”計劃,對于reducers數少于 “spark.shuffle.sort.bypassMergeThreshold” (200 by default),我們使用fallback計劃,hashing相關數據到分開的文件,然后合并這些文件為一個,具體實現為BypassMergeSortShuffleWriter。
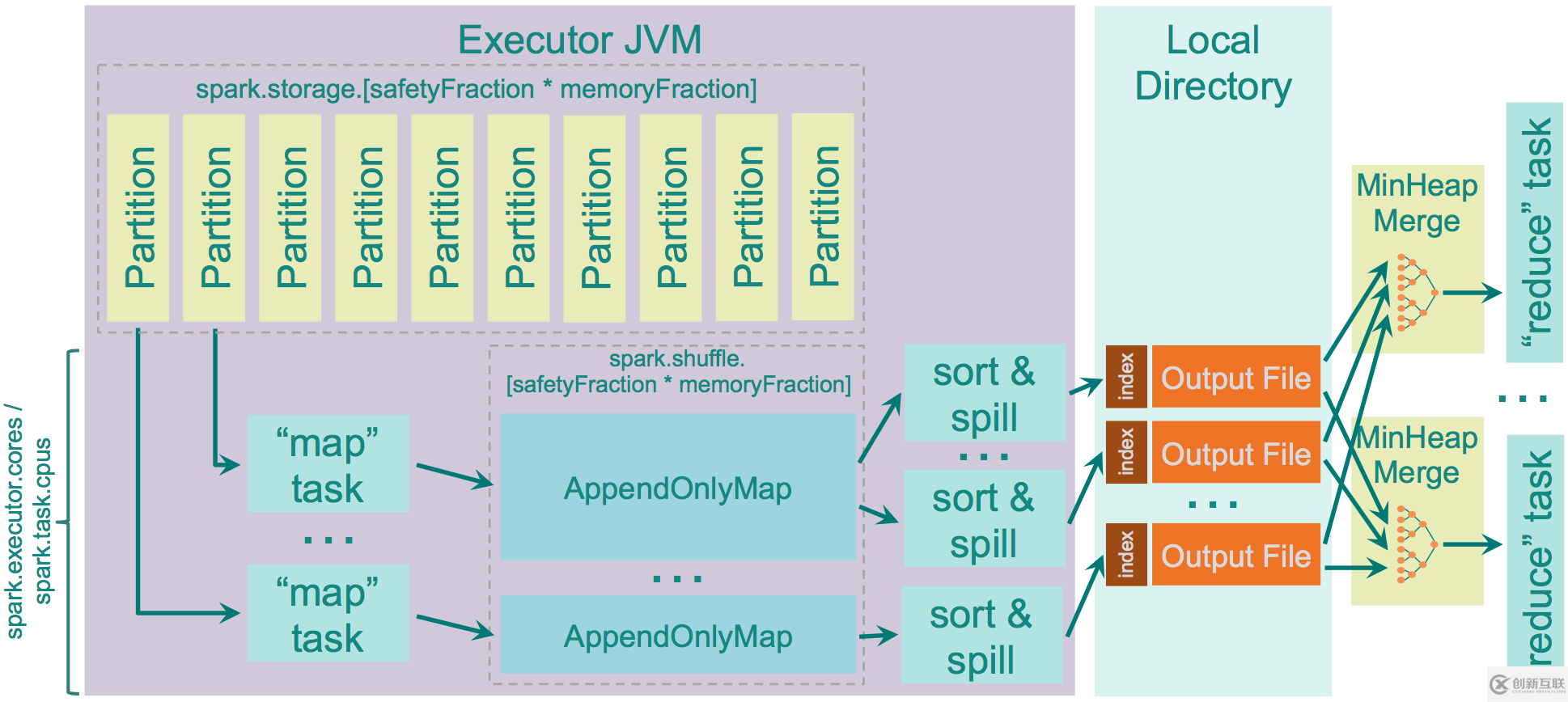
在map進行排序,在reduce端應用Timsort[1]進行合并。map端是否容許spill,通過spark.shuffle.spill來設置,默認是true。設置為false,如果沒有足夠的內存來存儲map的輸出,那么就會導致OOM錯誤,因此要慎用。
用于存儲map輸出的內存為:“JVM Heap Size” \* spark.shuffle.memoryFraction \* spark.shuffle.safetyFraction,默認為“JVM Heap Size” \* 0.2 \* 0.8 = “JVM Heap Size” \* 0.16。如果你在同一個執行程序中運行多個線程(設定spark.executor.cores/ spark.task.cpus超過1),每個map任務存儲的空間為“JVM Heap Size” * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction / spark.executor.cores * spark.task.cpus, 默認2個cores,那么為0.08 * “JVM Heap Size”。 spark使用AppendOnlyMap存儲map輸出的數據,利用開源hash函數MurmurHash4和平方探測法把key和value保存在相同的array中。這種保存方法可以是spark進行combine。如果spill為true,會在spill前sort。
Sort Shuffle內存的源碼級別更詳細說明可以參考[4],讀寫過程可以參考[5]
##優點
map創建文件量較少
少量的IO隨機操作,大部分是順序讀寫
##缺點
要比Hash Shuffle要慢,需要自己通過
spark.shuffle.sort.bypassMergeThreshold來設置合適的值。如果使用SSD盤存儲shuffle數據,那么Hash Shuffle可能更合適。
“ort shuffle有什么用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注創新互聯網站,小編將為大家輸出更多高質量的實用文章!
文章題目:ortshuffle有什么用
網址分享:http://vcdvsql.cn/article36/gjecpg.html
成都網站建設公司_創新互聯,為您提供營銷型網站建設、網站導航、網站設計、品牌網站設計、企業建站、虛擬主機
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 企業建站需要考慮哪些核心問題?成都網站建設公司 2016-11-01
- 個人與企業建站有何區別? 2016-10-26
- 企業建站:用戶體驗研究正在改變 2021-03-03
- 企業建站有哪有些是你需要了解的? 2022-10-13
- 企業建站公司網站建設排名分析 2022-11-14
- 企業建站主要的三大重點 2017-09-24
- 長沙做網站細談企業建站與SEO之間趨勢 2022-09-13
- 中小型企業建站專家,網站是貴公司線上的門面 2016-11-16
- 企業建站前 這8件事需要提前了解 2015-01-25
- 成都企業建站的六大要素 2016-11-05
- 北京中小企業建站有什么優勢 2021-09-06
- 企業建站注意哪些事項? 2017-09-16