ApacheFlink官方文檔--概念-創新互聯
數據流編程模型
原文鏈接
博主理解篇
抽象層次
Flink提供不同級別的抽象來開發流/批處理應用程序。
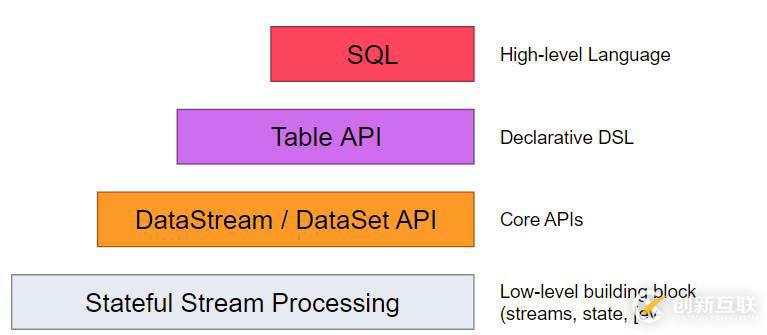
- 這個最低級別的抽象提供了有狀態的流式操作。它是通過處理函數嵌入到DataStream API。它允許用戶自由的處理一個或者多個數據流中的事件,并且使用一致,容錯的狀態。此外,用戶可以注冊事件時間和處理時間回調,允許程序實現復雜的計算。
- 實際上,大多數應用不需要上面描述的低級別抽象,而是針對Core APIs(核心API),例如:?DataStream API(有邊界和無邊界的數據流) 和?DataSet API(有邊界的數據集)。這些流暢的API提供通用數據處理,像用戶指定的各種形式的transformations(轉換),joins(連接),aggregations(聚合),windows(窗口化操作),state(狀態)等等。這些API表示在各自的編程語言中為類(class)中的數據類型進行處理。
低階的處理函數集成了DataStream API,這樣就可以針對特性的操作使用低層級的抽象。DataSet API 為有邊界的 data sets提供了附加的原語,例如循環/迭代。
- Table API 是一種以表為中心的聲明式的DSL,它可能會被動態的改變(當處理數據流的時候)。Table API?遵循擴展模型:Table 有一個附加模式(類似于關系型數據庫表)并且API提供了類似的操作,例如:select,project,join,group-by,aggregate等等。Table API聲明式的定義了邏輯操作應該怎么做 而不是確切的指定操作的代碼看起來如何。盡管table API可以通過多種形式的用戶自定義函數來擴展,它的表現還是不如Core APIs,但是用起來更加的簡潔(寫更少的代碼)。此外,Table API 還可以執行一個優化器,適用于優化規則之前執行。
Table和DataStream/DataSet之間可以無縫的轉換,允許程序組合使用Table api和DataStream和DataSet的API。 - Flink最高級別的抽象是sql。這種抽象在語義和表達上面類似于Table API,但將程序表示為SQL查詢表達式。SQL抽象與Table API 緊密聯系在一起,Sql查詢可以在table API定義的表中執行。
程序和數據流
Flink程序的基本構建模塊是streams(流)和transformations(轉換)。(需要注意的是,Flink的DataSet API所使用的DataSets內部也是流-更多內容將在以后解釋)。從概念上講流(可能沒有結束)是一個數據流記錄,而轉換是一個操作,它取一種或者多個流作為輸入,并產生一個或者多個輸出流作為結果。
當執行的時候,Flink程序映射到streaming dataflows(流數據流),由streams和轉換operators組成。每一個數據流開始于一個或者多個source,并且終止于一個或者多個sink。數據流類似于任意的有向無環圖(DAGS)。雖然通過迭代構造允許特定形式的環,但是大多數情況下,簡單起見,我們都不考慮這一點。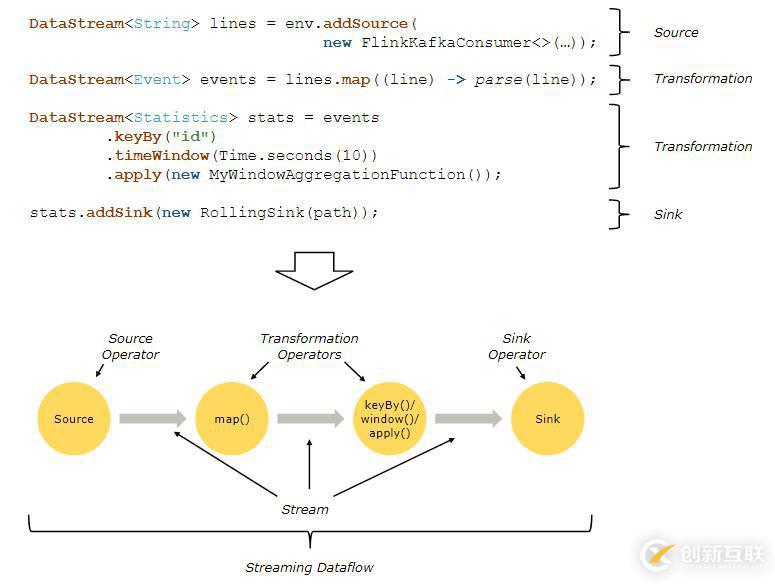
通常情況下,程序中的轉換與數據流中的操作是一一對應的。有時,然而,一個轉換可能有多個轉換操作構成。
source和sink的文檔在streaming connectors和 batch connectors 。Transformation的文檔在DataStream operators和DataSet transformation。并行數據流
Flink程序本質上是并行的和分布式的。在執行過程中,一個流(stream)包含一個或多個流分區 (stream partition),而每一個operator包含一個或多個operator子任務 。操作子任務之間彼此獨立,在不同的線程中執行,甚至有可能運行在不同的機器或容器上。
operator子任務的數量即是此特定operator的并行度 。一個流的并行度即其生產operator的并行度。相同程序中的不同的operator可能有不同級別的并行度。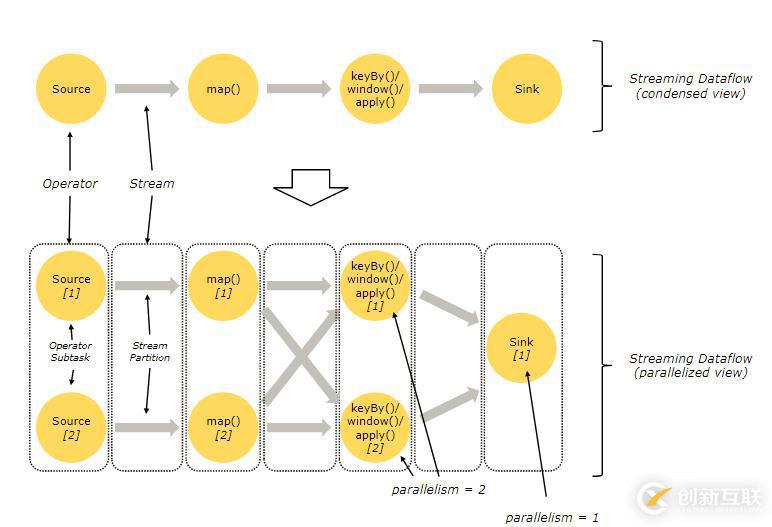
流在兩個operator之間傳輸數據,可以通過一對一(或稱 forwarding )模式,或者通過redistributing模式: - 一對一流(例如上圖中Source與map() opreator之間)保持了元素的分區與排序。那意味著 map() operator的子任務[1]將以與 Source 的子任務[1]生成順序相同的順序查看到相同的元素。
- Redistributing 流(如上圖中 map() 與 keyBy/window 之間,以及 keyBy/window 與 Sink 之間)則改變了流的分區。每一個operator子任務根據所選擇的轉換,向不同的目標子任務發送數據。比如 keyBy() (根據key的哈希值重新分區), broadcast() ,或者 rebalance() (隨機重分區)。在一次 redistributing 交換中,元素間的排序只保留在每對發送與接受子任務中(比如, map() 的子任務[1]與 keyBy/window 的子任務[2])。因此在這個例子中,每個鍵的順序被保留下來,但是并行確實引入了不確定性--對于不同鍵的聚合結果到達sink的順序。
配置和并行度的詳細配置可以查看這個文檔parallel execution。窗口(Window)
聚合事件(比如計數、求和)在流上的工作方式與批處理不同。比如,對流中的所有元素進行計數是不可能的,因為通常流是無限的(無邊界的)。相反,流上的聚合需要由窗口來劃定范圍,比如 “計算過去的5分鐘” ,或者 “最后100個元素的和” 。
窗口可以是事件驅動的 (比如:每30秒)或者數據驅動的 (比如:每100個元素)。窗口通常被區分為不同的類型,比如滾動窗口 (沒有重疊), 滑動窗口(有重疊),以及會話窗口(由不活動的間隙所打斷)
更多的窗口例子可以查看這個博客。更多的明細可以查看窗口文檔window docs。
時間(Time)
當提到流程序(例如定義窗口)中的時間時,你可以參考不同的時間概念:
- 事件時間是事件創建的時間。它通常由事件中的時間戳描述,例如附接在生產傳感器,或者生產服務。Flink通過時間戳分配器訪問事件時間戳。
- 攝入時間是事件進入Flink數據流源算子的時間。
- 處理時間 是每一個執行時間操作的operator的本地時間。
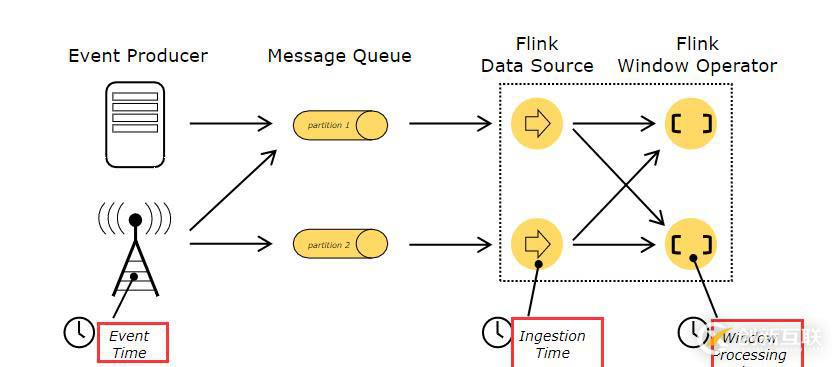
操作時間的更多詳細信息請查看文檔event time docs。
有狀態的操作
盡管數據流中的很多操作一次只查看一個獨立的事件(比如事件解析器),有些操作卻會記錄多個事件間的信息(比如窗口算子)。 這些操作被稱為有狀態的 。
有狀態操作的狀態保存在一個可被視作嵌入式鍵/值存儲的部分中。狀態由有狀態operator讀取的流一起被嚴格地分區與分布。因此,只能訪問一個 keyBy() 函數之后的 keyed streams 的鍵/值狀態,并且僅限于與當前事件鍵相關聯的值。調整流和狀態的鍵確保了所有狀態更新都是本地操作,以在沒有事務開銷的情況下確保一致性。這種對齊還使得Flink可以透明地重新分配狀態與調整流的分區。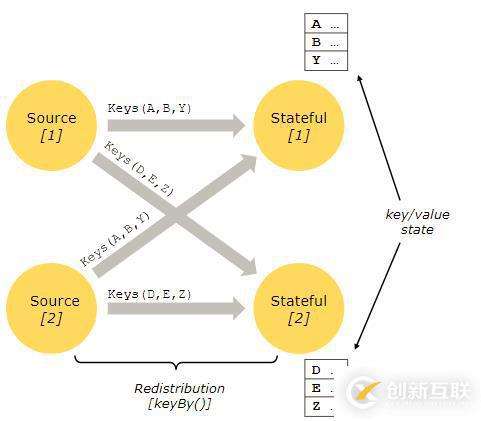
查看更多信息,請查看此文檔有關state的內容。
容錯檢查點
Flink使用流重放與檢查點的結合實現了容錯。檢查點與每個輸入流的特定點及與相關的每一個operator的狀態相關。一個數據流可以從一個檢查點恢復出來,其中通過恢復operator狀態并從檢查點重放事件以保持一致性 (一次處理語義)
檢查點間隔是以恢復時間(需要重放的事件數量)來消除執行過程中容錯的開銷的一種手段。
容錯內部的描述提供了更多關于flink管理檢查點和相關的話題。啟用和配置檢查點的詳細信息請查看這個文檔checkpointing API docs。
流式批處理
Flink將批處理程序作為流處理程序的特殊情況來執行,只是流是有界的(有限個元素)。 DataSet 內部被視為數據流。上述適用于流處理程序的概念同樣適用于批處理程序,除了一些例外:
- 批處理程序的容錯不再使用檢查點。而是通過完全地重放流來恢復。因為輸入是有界的,因此這是可行的。這種方法使得恢復的成本增加,但是由于避免了檢查點,因而使得正常處理的開銷更小。
- DataSet API中的有狀態操作使用簡化的in-memory/out-of-core數據結構,而不是鍵/值索引。
- DataSet API引入了特殊的同步(superstep-base)迭代,而這種迭代僅僅能在有界流上執行。細節可以查看迭代文檔。
分布式運行時
原文鏈接
任務和Operator鏈
對于分布式運行,Flink將operator子任務鏈接在一起放入任務池。每個任務由一個線程執行。將operator鏈接到任務池中是一項有用的優化:它減少線程到線程的切換和緩沖的開銷,并在降低延遲的同時提高整體吞吐量。可以配置鏈接行為,有關詳細信息,請查閱鏈接文檔。
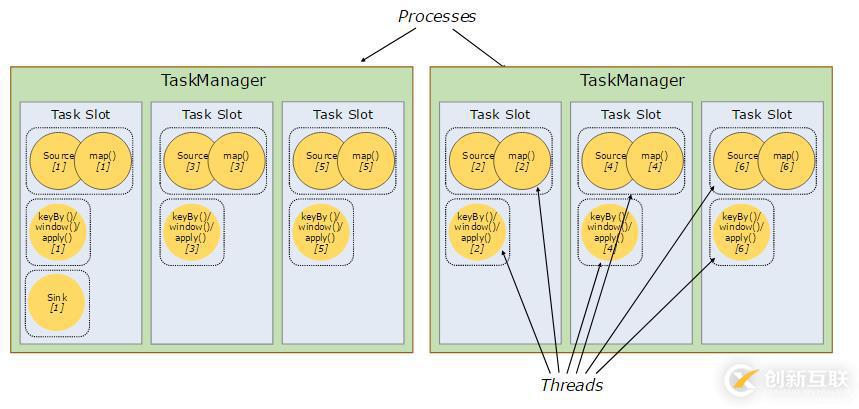
下圖中的示例數據流由五個子任務執行,因此有五個并行線程。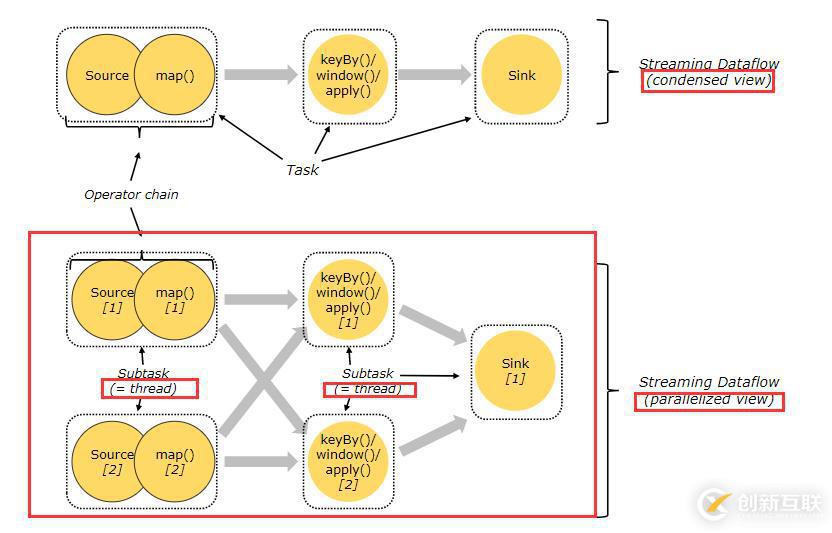
作業管理器,任務管理器,客戶端
Flink運行時有兩種類型的進程組成:
- 作業管理器(JobManagers,也稱為主節點master)負責協調分布式運行時。它們調度任務,協調檢查點,協調失敗恢復,等。
至少有一個作業管理器節點,高可用的環境有多個作業管理器,其中一個節點是leader角色,其他節點是standby角色。 - 任務管理器(TaskManagers,也稱為工作節點worker)執行數據流的任務(更特定一些,子任務),緩沖以及轉換數據流。
同樣至少有一個任務管理器節點。
作業管理器與任務管理器可以以多種方式啟動:以standalone集群的方式直接在主機上啟動,或者被資源管理器YARN或Mesos管理啟動。任務管理器連接到作業管理器上,聲明它們自己是可用狀態并且可被分配任務。
客戶端不是程序運行時的一部分,但是經常用來準備以及發送數據流程序到作業管理器上。此后,客戶端可以斷開連接,或者保持連接結束進程報告。客戶端可以以Java/Scala程序的方式觸發執行,或者在命令行"./bin/flink"中運行。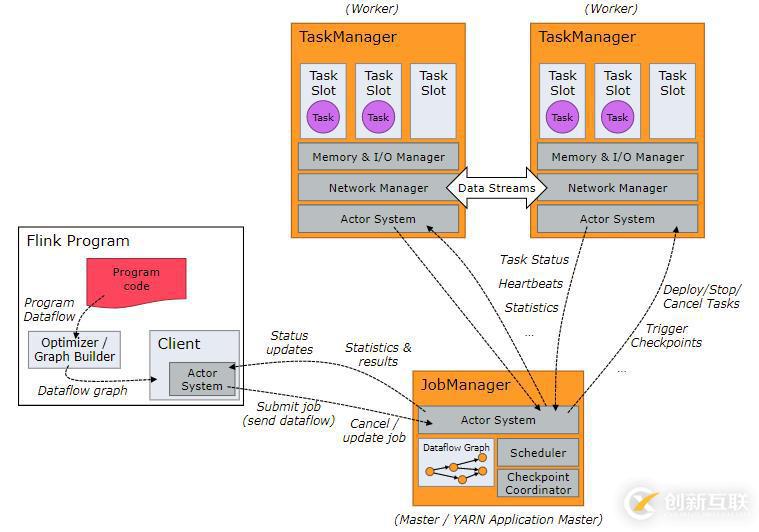
Task Slot和資源
每個Worker節點(任務管理器)是一個JVM進程,在分開的線程中可以執行一個或多個子任務。一個Worker通過控制task slots(至少一個)來控制節點接受多少任務。
每個task slot代表任務管理器固定大小的資源子集。例如:一個擁有3個slot的任務管理器,將會分配它管理的1/3內存到每個slot。對資源進行分槽(slot)意味著子任務不會與其他作業的子任務競爭管理的內存,而是具有一定數量的保留管理內存。注意此處沒有CPU隔離發生,現在只能分隔任務的管理內存。
通過調整task slot數目,用戶可以定義子任務之間如何隔離。每個任務管理器擁有一個slot意味著任務組運行在隔離的JVM(例如,可以在隔離的容器上啟動)上。擁有多個slots意味著更多的子任務共享相同的JVM。在相同的JVM上的任務共享TCP連接(通過多路復用)和心跳信息。它們還可以共享數據集和數據結構,從而減少每個任務的開銷。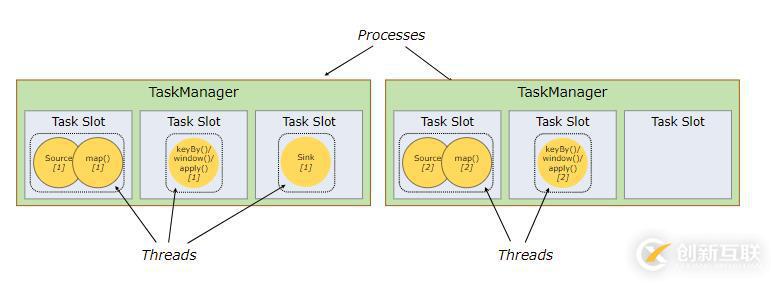
默認情況下,Flink允許子任務共享slot,即使它們是不同任務的子任務,只要它們來自同一個作業。結果就是一個slot擁有這個作業的所有管道操作(pipeline)。允許這種slot共享有兩個主要的好處: - Flink集群需要與作業中使用的最高并行度同樣的task slots。無需計算程序總共包含多少任務(在不同的并行度之上)。
- 更容易獲得更好的資源利用率。沒有共享slot的情況下,非密集型的source與map()子任務將會阻塞與資源密集型的窗口子任務同樣多的資源。通過共享slot,將并行度從2增加到6可以充分利用the slotted(時隙)資源,同時確保繁重的子任務在任務管理器上公平的分配。
APIs同樣還包括用于防止不期望的slot共享的資源組機制。
根據經驗,一個很好的默認任務槽(task slot)數就是CPU核心數。使用超線程,每個slot需要2個或更多硬件線程上下文。
狀態后端(State Backends)
存儲鍵/值對索引的確切數據結構取決于所選的狀態后端。一個狀態后端將數據存儲在內存中的哈希映射中,另一個狀態后端使用[RocksDB]()作為鍵/值對存儲。除了定義保存狀態的數據結構之外,狀態后端還實現邏輯以獲取鍵/值對狀態的時間點快照,并將該快照存儲為檢查點的一部分。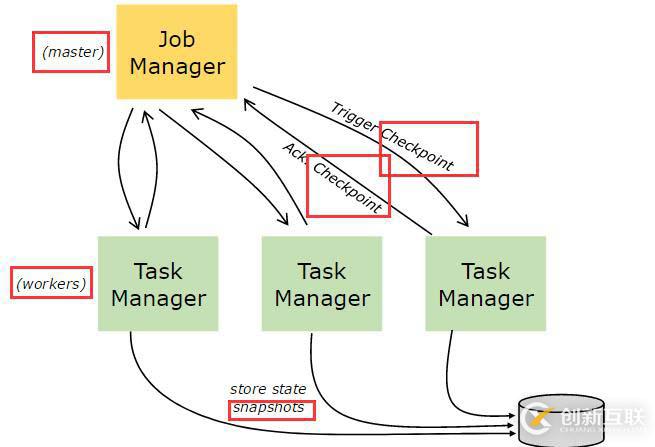
保存點Savepoints
用Data Stream API編寫的程序可以從保存點恢復執行。保存點允許更新程序和Flink集群,而不會丟失任何狀態。
保存點是手動觸發的檢查點,它會獲取程序的快照并將其寫入狀態后端。他們依靠常規的檢查點機制。在執行期間,程序會定期在工作節點上創建快照并生成檢查點。對于恢復,僅僅需要最后完成的檢查點,因此一旦新的檢查點完成,就可以安全地丟棄舊的檢查點。
保存點與這些定期檢查點類似,不同之處在于它們由用戶觸發,并且在較新的檢查點完成時不會自動過期。可以從命令行或通過REST API取消作業時創建保存點。
另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
當前文章:ApacheFlink官方文檔--概念-創新互聯
文章起源:http://vcdvsql.cn/article38/csiesp.html
成都網站建設公司_創新互聯,為您提供軟件開發、網站排名、域名注冊、云服務器、網站內鏈、外貿網站建設
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 品牌網站建設的理念和模板網站區別 2016-11-14
- 品牌網站建設要理解當前趨勢并選擇直觀的導航 2015-01-12
- 品牌網站建設之搜索引擎營銷 2021-09-06
- 品牌網站建設中視覺規劃的重要性 2023-02-17
- 品牌網站建設只需幾招便可搞定 2022-12-28
- 企業品牌網站建設需要注意什么?如何建設出優秀的品牌網站? 2022-10-04
- 成都品牌網站建設問題解析! 2022-10-21
- 品牌網站建設的方案 2021-06-13
- 高品質品牌網站建設的四要素 2022-08-30
- 品牌網站建設流程 2022-11-20
- 在品牌網站建設時,如何制作搜索引擎喜歡的網站? 2016-09-05
- 品牌網站建設從什么角度開始 2016-09-26