怎么用python實(shí)現(xiàn)KNN分類器
這篇文章主要介紹“怎么用python實(shí)現(xiàn)KNN分類器”,在日常操作中,相信很多人在怎么用python實(shí)現(xiàn)KNN分類器問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”怎么用python實(shí)現(xiàn)KNN分類器”的疑惑有所幫助!接下來,請跟著小編一起來學(xué)習(xí)吧!
成都創(chuàng)新互聯(lián)專業(yè)為企業(yè)提供紫陽網(wǎng)站建設(shè)、紫陽做網(wǎng)站、紫陽網(wǎng)站設(shè)計(jì)、紫陽網(wǎng)站制作等企業(yè)網(wǎng)站建設(shè)、網(wǎng)頁設(shè)計(jì)與制作、紫陽企業(yè)網(wǎng)站模板建站服務(wù),十年紫陽做網(wǎng)站經(jīng)驗(yàn),不只是建網(wǎng)站,更提供有價(jià)值的思路和整體網(wǎng)絡(luò)服務(wù)。
什么是監(jiān)督學(xué)習(xí)?
監(jiān)督學(xué)習(xí)是指:利用一組已知類別的樣本調(diào)整分類器的參數(shù),使其達(dá)到所要求性能的過程,也稱為監(jiān)督訓(xùn)練或有教師學(xué)習(xí)。
監(jiān)督學(xué)習(xí)是從標(biāo)記的訓(xùn)練數(shù)據(jù)來推斷一個(gè)功能的機(jī)器學(xué)習(xí)任務(wù)。訓(xùn)練數(shù)據(jù)包括一套訓(xùn)練示例。在監(jiān)督學(xué)習(xí)中,每個(gè)實(shí)例都是由一個(gè)輸入對象(通常為向量)和一個(gè)期望的輸出值(也稱為監(jiān)督信號)組成。監(jiān)督學(xué)習(xí)算法是分析該訓(xùn)練數(shù)據(jù),并產(chǎn)生一個(gè)推斷的功能,其可以用于映射出新的實(shí)例。一個(gè)最佳的方案將允許該算法來正確地決定那些看不見的實(shí)例的類標(biāo)簽。
舉個(gè)例子會(huì)更清楚
這是一個(gè)數(shù)據(jù)集,包含一些水果樣本的質(zhì)量、寬度、高度和顏色分?jǐn)?shù)。
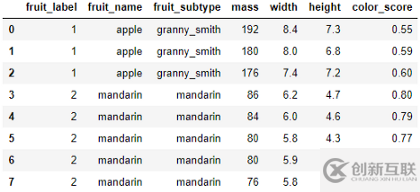
目的是訓(xùn)練一個(gè)模型,如果我們在模型中輸入質(zhì)量、寬度、高度和顏色分?jǐn)?shù),模型就可以讓我們知道水果的名稱。例如,如果我們輸入一個(gè)水果的質(zhì)量、寬度、高度和顏色分?jǐn)?shù)分別設(shè)置為175、7.3、7.2、0.61,模型應(yīng)該將水果的名稱輸出為蘋果。
在這里,質(zhì)量、寬度、高度和顏色分?jǐn)?shù)是輸入特征(X)。水果的名稱是輸出變量或標(biāo)簽(y)。
這個(gè)例子對你來說可能聽起來很傻。但這是在監(jiān)督機(jī)器學(xué)習(xí)模型中使用的機(jī)制。
稍后我將用一個(gè)真實(shí)的數(shù)據(jù)集展示一個(gè)實(shí)際的例子。
KNN分類器
KNN分類器是基于記憶的機(jī)器學(xué)習(xí)模型的一個(gè)例子。
這意味著這個(gè)模型會(huì)記住訓(xùn)練示例,然后他們用它來分類以前從未見過的對象。
KNN分類器的k是為了預(yù)測一個(gè)新的測試實(shí)例而檢索的訓(xùn)練樣本數(shù)。
KNN分類器分三步工作:
當(dāng)給它一個(gè)新的實(shí)例或?qū)嵗M(jìn)行分類時(shí),它將檢索之前記憶的訓(xùn)練樣本,并從中找出最近的樣本的k個(gè)數(shù)。
然后分類器查找最近的例子的k個(gè)數(shù)字的標(biāo)簽(上面例子中水果的名稱)。
最后,該模型結(jié)合這些標(biāo)簽進(jìn)行預(yù)測。通常,它會(huì)預(yù)測標(biāo)簽最多的那個(gè)。例如,如果我們選擇k為5,在最近的5個(gè)例子中,如果我們有3個(gè)橘子和2個(gè)蘋果,那么新實(shí)例的預(yù)測值將是橘子。
資料準(zhǔn)備
在開始之前,我建議你檢查計(jì)算機(jī)中是否有以下可用資源:
Numpy 庫
Pandas 庫
Matplotlib 庫
Scikit-Learn 庫
Jupyter Notebook
如果你沒有安裝Jupyter Notebook,你可以選擇其他筆記本。我建議你可以使用谷歌公司的Colab。
谷歌Colab Notebook不是私有的。所以,不要在那里做任何專業(yè)或敏感的工作。但對練習(xí)來說很棒。因?yàn)楹芏喑S玫能浖呀?jīng)安裝在里面了。
我建議下載數(shù)據(jù)集。我在頁面底部提供了鏈接。你可以自己運(yùn)行每一行代碼。
首先,導(dǎo)入必要的庫:
%matplotlib notebook import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.model_selection import train_test_split
在本教程中,我將使用來自Kaggle的泰坦尼克號數(shù)據(jù)集。我已將此數(shù)據(jù)集上傳到與我的筆記本相同的文件夾中。
下面是如何使用pandas導(dǎo)入數(shù)據(jù)集。
titanic = pd.read_csv('titanic_data.csv')
titanic.head()
#titaninc.head() 給出數(shù)據(jù)集的前五行。我們只打印前五行以檢查數(shù)據(jù)集。
看第二列。它包含的信息,如果人活了下來。0表示該人幸存,1表示該人沒有存活。
在本教程中,我們的目標(biāo)是預(yù)測“幸存”特征。
為了簡單起見,我將保留一些對算法更重要的關(guān)鍵特征,并去掉其余的。
這個(gè)數(shù)據(jù)集非常簡單。僅僅憑直覺,我們可以看到有些列對于預(yù)測“幸存”特征并不重要。
例如,“PassengerId”、“Name”、“Ticket”和“Cabin”似乎對預(yù)測乘客是否存活沒有幫助。
我將制作一個(gè)具有一些關(guān)鍵特征的新數(shù)據(jù)幀,并將其命名為titanic1。
titanic1 = titanic[['Pclass', 'Sex', 'Fare', 'Survived']]
“Sex”列具有字符串值,需要更改該值。因?yàn)橛?jì)算機(jī)不懂單詞。它只懂?dāng)?shù)字。我將把“男”改為0,“女”改為1。
titanic1['Sex'] = titanic1.Sex.replace({'male':0, 'female':1})以下是titanic1數(shù)據(jù)幀的外觀:
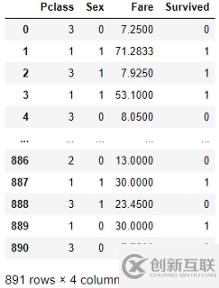
我們的目標(biāo)是根據(jù)泰坦尼克1號數(shù)據(jù)幀中的其他信息預(yù)測“幸存”參數(shù)。因此,輸出變量或標(biāo)簽(y)是“幸存”。輸入特征(X)是'P-class'、'Sex'和'Fare'。
X = titanic1[['Pclass', 'Sex', 'Fare']] y = titanic1['Survived']
開發(fā)KNN分類器
首先,我們需要將數(shù)據(jù)集分成兩個(gè)集:訓(xùn)練集和測試集。
我們將使用訓(xùn)練集來訓(xùn)練模型,其中模型將同時(shí)記憶輸入特征和輸出變量。
然后,我們將使用測試集來檢驗(yàn)?zāi)P褪欠衲軌蚴褂谩癙-class”、“Sex”和“Fare”來預(yù)測乘客是否幸存。
“train_test_split”方法將有助于分割數(shù)據(jù)。默認(rèn)情況下,此函數(shù)使用75%的數(shù)據(jù)得到訓(xùn)練集,使用25%的數(shù)據(jù)得到測試集。你可以改變它,你可以指定“train_size”或“test_size ”。
如果將train_size設(shè)置為0.8,則拆分為80%的訓(xùn)練數(shù)據(jù)和20%的測試數(shù)據(jù)。但對我來說,默認(rèn)值75%是好的。所以,我沒有使用train_size或test_size 參數(shù)。
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
記住對“random_state”使用相同的值。這樣,每次進(jìn)行這種拆分時(shí),訓(xùn)練集和測試集的數(shù)據(jù)都是相同的。
我選擇隨機(jī)狀態(tài)為0。你可以選擇一個(gè)數(shù)字。
Python的scikit-learn庫已經(jīng)有了KNN分類器模型。進(jìn)行導(dǎo)入。
from sklearn.neighbors import KNeighborsClassifier
將此分類器保存在變量中。
knn = KNeighborsClassifier(n_neighbors = 5)
在這里,n_neighbors是5。
這意味著,當(dāng)我們要求我們的訓(xùn)練模型來預(yù)測一個(gè)新實(shí)例的生存概率時(shí),它需要5個(gè)最近的訓(xùn)練數(shù)據(jù)。
基于這5個(gè)訓(xùn)練數(shù)據(jù)的標(biāo)簽,模型將預(yù)測新實(shí)例的標(biāo)簽。
現(xiàn)在,我將把訓(xùn)練數(shù)據(jù)擬合到模型中,以便模型能夠記住它們。
knn.fit(X_train, y_train)
你可能會(huì)認(rèn)為,當(dāng)它記住訓(xùn)練數(shù)據(jù)時(shí),它可以100%正確地預(yù)測訓(xùn)練特征的標(biāo)簽。但不一定,為什么?
每當(dāng)我們給出輸入并要求它預(yù)測標(biāo)簽時(shí),它都會(huì)從5個(gè)最近的鄰居那里投票,即使它記憶了完全相同的特征。
讓我們看看它在訓(xùn)練數(shù)據(jù)上能給我們多大的準(zhǔn)確度
knn.score(X_test, y_test)
訓(xùn)練數(shù)據(jù)的準(zhǔn)確率為0.83或83%。
記住,我們有一個(gè)模型從未見過的測試數(shù)據(jù)集。現(xiàn)在檢查一下,它能在多大程度上準(zhǔn)確地預(yù)測測試數(shù)據(jù)集的標(biāo)簽。
knn.score(X_test, y_test)
準(zhǔn)確率為0.78%或78%。
結(jié)合以上代碼,下面是4行代碼,它們構(gòu)成了分類器:
knn = KNeighborsClassifier(n_neighbors = 5) knn.fit(X_train, y_train) knn.score(X_train, y_train) knn.score(X_test, y_test)
恭喜!你學(xué)習(xí)了KNN分類器!
注意,訓(xùn)練集的準(zhǔn)確度比測試集的準(zhǔn)確度高一點(diǎn)。
什么是過擬合?
有時(shí),模型對訓(xùn)練集的學(xué)習(xí)非常好,可以很好地預(yù)測訓(xùn)練數(shù)據(jù)集的標(biāo)簽。但是,當(dāng)我們要求模型使用測試數(shù)據(jù)集或它以前沒有看到的數(shù)據(jù)集進(jìn)行預(yù)測時(shí),它的性能如果遠(yuǎn)遠(yuǎn)不如訓(xùn)練集,這種現(xiàn)象稱為過擬合。
用一句話來說,當(dāng)訓(xùn)練集的準(zhǔn)確度遠(yuǎn)遠(yuǎn)高于測試集的準(zhǔn)確度時(shí),我們稱之為過擬合。
預(yù)測
如果要查看測試數(shù)據(jù)集的預(yù)測輸出,請執(zhí)行以下操作:
輸入:
y_pred = knn.predict(X_test) y_pred
輸出:
array([0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1], dtype=int64)
或者你可以只輸入一個(gè)例子,然后找到標(biāo)簽。
我想知道,當(dāng)一個(gè)人乘坐“P-class”=3旅行時(shí),“Sex”是女性,也就是說Sex=1,而且,付了25英鎊的“車費(fèi)”,她是否能按照我們的模型生存下來。
輸入:
knn.predict([[3, 1, 25]])
記住使用兩個(gè)括號,因?yàn)樗枰粋€(gè)二維數(shù)組
輸出:
array([0], dtype=int64)
輸出為零。這意味著按照我們訓(xùn)練過的模型,這個(gè)人無法生存。
請隨時(shí)嘗試更多不同的輸入,就像這一個(gè)一樣。
如果你想進(jìn)一步分析KNN分類器
KNN分類器對k和n_neighbors的選擇非常敏感。在上面的例子中,我使用了n_neighbors=5。
對于不同的n_neighbors,分類器的性能會(huì)有所不同。
讓我們檢查一下它在訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集上對不同n_neighbors的執(zhí)行情況。我選1到20。
現(xiàn)在,我們將計(jì)算從1到20的每個(gè)n_neighbors的訓(xùn)練集準(zhǔn)確率和測試集準(zhǔn)確率
training_accuracy = [] test_accuracy = [] for i in range(1, 21): knn = KNeighborsClassifier(n_neighbors = i) knn.fit(X_train, y_train) training_accuracy.append(knn.score(X_train, y_train)) test_accuracy.append(knn.score(X_test, y_test))
在運(yùn)行了這個(gè)代碼片段之后,我得到了針對不同n_neighbors的訓(xùn)練和測試準(zhǔn)確度。
現(xiàn)在,讓我們將訓(xùn)練和測試集的精確度在同一圖中進(jìn)行比較。
plt.figure()
plt.plot(range(1, 21), training_accuracy, label='Training Accuarcy')
plt.plot(range(1, 21), test_accuracy, label='Testing Accuarcy')
plt.title('Training Accuracy vs Test Accuracy')
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')
plt.ylim([0.7, 0.9])
plt.legend(loc='best')
plt.show()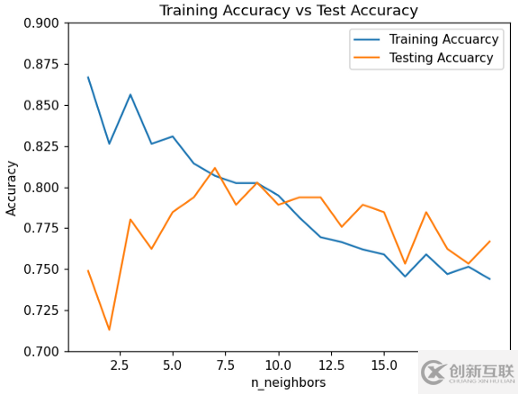
分析上面的圖表
在一開始,當(dāng)n_neighbors 為1、2或3時(shí),訓(xùn)練準(zhǔn)確率遠(yuǎn)遠(yuǎn)高于測試準(zhǔn)確率。所以,這個(gè)模型正遭受著過擬合的困擾。
在那之后,訓(xùn)練和測試的準(zhǔn)確性變得更接近了。這是最佳選擇。我們想要這個(gè)。
但當(dāng)n_neighbors變得更多時(shí),訓(xùn)練和測試集的精確度都在下降。我們不需要這個(gè)。
從上面的圖中可以看出,這個(gè)特定數(shù)據(jù)集和模型的理想n_neighbors 應(yīng)該是6或7。
這是一個(gè)很好的分類器!
看上面的圖表!當(dāng)n_neighbors 為7時(shí),訓(xùn)練和測試的準(zhǔn)確率均在80%以上。
到此,關(guān)于“怎么用python實(shí)現(xiàn)KNN分類器”的學(xué)習(xí)就結(jié)束了,希望能夠解決大家的疑惑。理論與實(shí)踐的搭配能更好的幫助大家學(xué)習(xí),快去試試吧!若想繼續(xù)學(xué)習(xí)更多相關(guān)知識,請繼續(xù)關(guān)注創(chuàng)新互聯(lián)網(wǎng)站,小編會(huì)繼續(xù)努力為大家?guī)砀鄬?shí)用的文章!
分享標(biāo)題:怎么用python實(shí)現(xiàn)KNN分類器
瀏覽地址:http://vcdvsql.cn/article38/iipspp.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供標(biāo)簽優(yōu)化、外貿(mào)網(wǎng)站建設(shè)、虛擬主機(jī)、Google、App設(shè)計(jì)、ChatGPT
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場,如需處理請聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來源: 創(chuàng)新互聯(lián)

- 關(guān)鍵詞優(yōu)化的正確方法 2014-06-11
- 移動(dòng)端SEO關(guān)鍵詞優(yōu)化技巧剖析 2014-04-18
- 亞馬遜平臺(tái)做關(guān)鍵詞優(yōu)化教程 2013-07-31
- seo關(guān)鍵詞優(yōu)化要注意什么? 2013-07-03
- 企業(yè)網(wǎng)站制作過程中核心關(guān)鍵詞優(yōu)化策略 2021-08-14
- 企業(yè)網(wǎng)站關(guān)鍵詞優(yōu)化都有哪些技巧? 2023-04-10
- 網(wǎng)站關(guān)鍵詞優(yōu)化推廣技巧總結(jié)和分析詳解 2016-11-13
- 關(guān)鍵詞優(yōu)化上不去的原因 2016-09-19
- 關(guān)鍵詞優(yōu)化做好這幾點(diǎn),讓成都網(wǎng)站脫穎而出 2022-07-05
- 網(wǎng)頁關(guān)鍵詞優(yōu)化小竅門 2021-09-25
- 【SEO優(yōu)化】如何優(yōu)化多個(gè)關(guān)鍵詞?多關(guān)鍵詞優(yōu)化要點(diǎn)有哪些? 2022-04-16
- 做SEO關(guān)鍵詞優(yōu)化并不僅僅是為排名 2022-12-30