hive基本架構
如下圖所示,從邏輯上來看,Hive包含了3大部分。
創新互聯堅持“要么做到,要么別承諾”的工作理念,服務領域包括:成都網站建設、成都做網站、企業官網、英文網站、手機端網站、網站推廣等服務,滿足客戶于互聯網時代的安遠網站設計、移動媒體設計的需求,幫助企業找到有效的互聯網解決方案。努力成為您成熟可靠的網絡建設合作伙伴!
- Hive Clients
- Hive Services
- Hive Storage and Computing
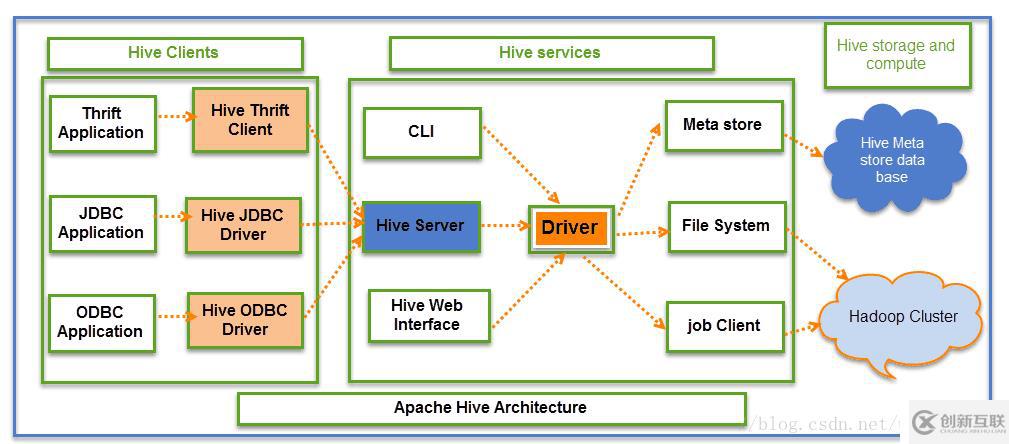
用戶操作Hive的接口主要有三個:CLI,Client 和 WUI。
其中最常用的是CLI,Cli啟動的時候,會同時啟動一個Hive副本。
Client是Hive的客戶端,用戶連接至Hive Server。在啟動 Client模式的時候,需要指出Hive Server所在節點,并且在該節點啟動Hive Server。而客戶端則又可以分為三種Thrift Client,JDBC Client,ODBC Client。
Web Interface是通過瀏覽器訪問Hive。
- Hive將元數據存儲在數據庫中,如MySQL、derby。Hive中的元數據包括表的名字,表的列和分區及其屬性,表的屬性(是否為外部表等),表的數據所在目錄等。
- 解釋器、編譯器、優化器完成HQL查詢語句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成。生成的查詢計劃存儲在HDFS中,并在隨后由MapReduce調用執行。
- Hive的數據存儲在HDFS中,大部分的查詢、計算由MapReduce完成(注意,包含的查詢,比如select from tbl不會生成MapRedcue任務)。
上圖中的Driver會處理從應用到metastore到filed system的所有請求,以進行后續操作。
Hive組件
Driver
實現了session handler,在JDBC/ODBC接口上實現了執行和獲取信息的API。
Compiler
該組件用于對不同的查詢表達式做解析查詢,語義分析,最終會根據從metastore中查詢到的表和分區元數據生成一個execution plain。
Execution Egine
該組件會執行由compiler創建的execution。其中plan從數據結構上來看,是一個DAG,該組件會管理plan的不同stage與組件中執行這些plan之間的依賴。
Metastore
Hive的metastore組件是hive元數據集中存放地。該組件存儲了包括變量表中列和列類型等結構化的信息以及數據倉庫中的分區信息(包括列和列類型信息,讀寫數據時必要的序列化和反序列化信息,數據被存儲在HDFS文件中的位置)。
Metastore組件包括兩個部分:metastore services和Meta storage database。
- Metastore database的介質就是關系數據庫,例如hive默認的嵌入式磁盤數據庫derby,還有mysql數據庫。
- Metastore services是建立在后臺數據存儲介質(HDFS)之上,并且可以和hive services進行交互的服務組件。
默認情況下,metastore services和hive services是安裝在一起的,運行在同一個進程當中。也可以把metastore services從hive services里剝離出來,將metastore獨立安裝在一個集群里,hive遠程調用metastore services。這樣我們可以把元數據這一層放到防火墻之后,客戶端訪問hive服務,就可以連接到元數據這一層,從而提供了更好的管理性和安全保障。
使用遠程的metastore services,可以讓metastore services和hive services運行在不同的進程里,這樣也保證了hive的穩定性,提升了hive services的效率。
Hive執行過程
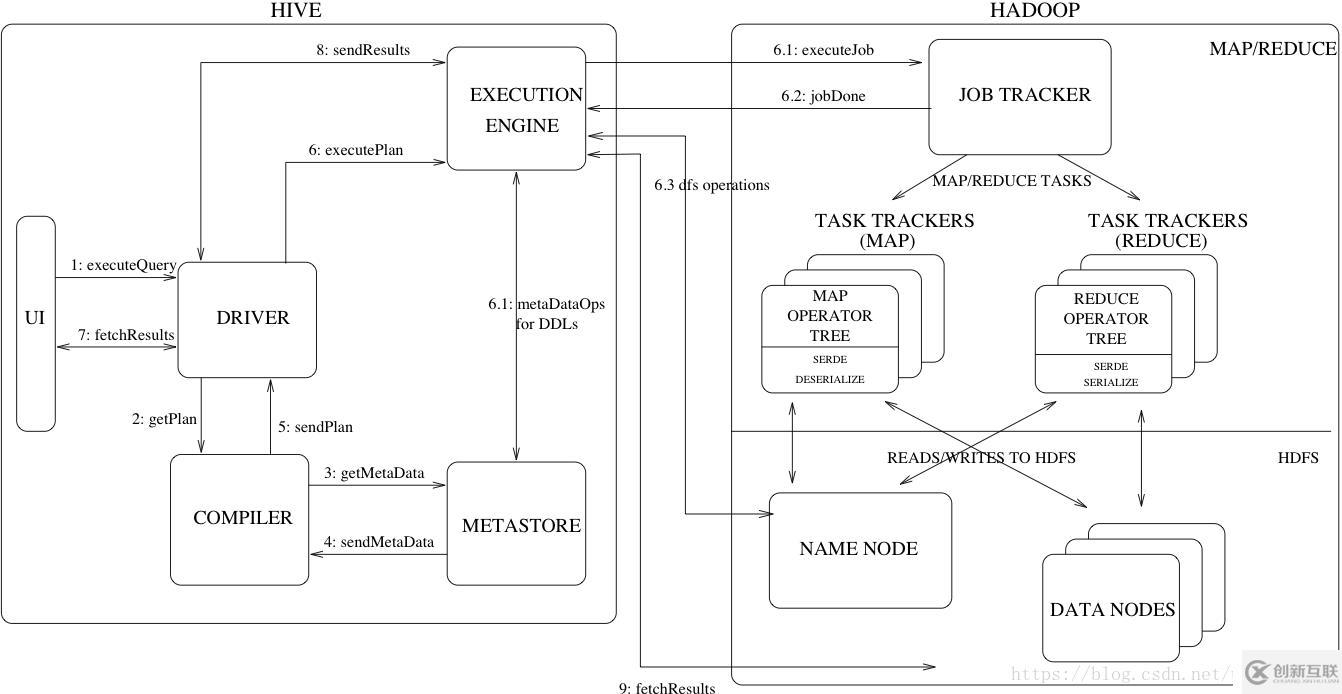
流程大致步驟為:
- 用戶提交查詢等任務給Driver。
- Driver為查詢操作創建一個session handler,接著dirver會發送查詢操作到compiler去生成一個execute plan
- Compiler根據用戶任務去MetaStore中獲取需要的Hive的元數據信息。這些元數據在后續stage中用作抽象語法樹的類型檢測和修剪。
- Compiler得到元數據信息,對task進行編譯,先將HiveQL轉換為抽象語法樹,然后將抽象語法樹轉換成查詢塊,將查詢塊轉化為邏輯的查詢plan,重寫邏輯查詢plan,將邏輯plan轉化為物理的plan(MapReduce), 最后選擇最佳策略。
- 將最終的plan提交給Driver。
- Driver將plan轉交給ExecutionEngine去執行,將獲取到的元數據信息,提交到JobTracker或者RsourceManager執行該task,任務會直接讀取到HDFS中進行相應的操作。
- 獲取執行的結果。
- 取得并返回執行結果。
創建表
解析用戶提交的Hive語句->對其進行解析->分解為表、字段、分區等Hive對象
根據解析到的信息構建對應的表、字段、分區等對象,從SEQUENCE_TABLE中獲取構建對象的最新的ID,與構建對象信息(名稱、類型等等)一同通過DAO方法寫入元數據庫的表中,成功后將SEQUENCE_TABLE中對應的最新ID+5。
實際上常見的RDBMS都是通過這種方法進行組織的,其系統表中和Hive元數據一樣顯示了這些ID信息。通過這些元數據可以很容易的讀取到數據。
優化器
優化器是一個不斷更新的組件,大部分plan的轉移都是通過優化器完成的。
- 將多Multiple join 合并為一個Muti-way join
- 對join、group-by和自定義的MapReduce操作重新進行劃分。
- 消減不必要的列。
- 在表的掃描操作中推行使用斷言。
- 對于已分區的表,消減不必要的分區。
- 在抽樣查詢中,消減不必要的桶。
- 優化器還增加了局部聚合操作用于處理大分組聚合和增加再分區操作用于處理不對稱的分組聚合。
新聞標題:hive基本架構
網頁鏈接:http://vcdvsql.cn/article42/gjshec.html
成都網站建設公司_創新互聯,為您提供用戶體驗、定制開發、品牌網站制作、服務器托管、做網站、
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 淺析商城網站怎么建設才能吸引客戶? 2016-09-26
- 商城網站開發如何才能保證安全性 2021-04-24
- 搭建一個商城網站需要多少錢? 2021-06-21
- 中小型企業建立網站商城有什么優點 2016-11-14
- 商城網站建設需要注意哪些 2013-12-18
- 商城網站需要具備的特點 2022-11-30
- 商城網站操作日志和物流分析 2023-03-13
- 如何提高商城網站的轉化率 2022-12-09
- 商城網站開發流程 2016-10-08
- 深圳商城網站制作小技巧 2021-11-15
- 商城網站模板設計要遵守哪些原則? 2014-12-12
- 商城網站建設的轉化技巧 2022-10-30