MapReduce如何實現自定義排序-創新互聯
MapReduce概念

是一種編程模型,用于大規模數據集(大于1TB)的并行運算。概念"Map(映射)"和"Reduce(歸約)",和它們的主要思想,都是從函數式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會分布式并行編程的情況下,將自己的程序運行在分布式系統上。 當前的軟件實現是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。
MapReduce提供了以下的主要功能:
1)數據劃分和計算任務調度:
系統自動將一個作業(Job)待處理的大數據劃分為很多個數據塊,每個數據塊對應于一個計算任務(Task),并自動 調度計算節點來處理相應的數據塊。作業和任務調度功能主要負責分配和調度計算節點(Map節點或Reduce節點),同時負責監控這些節點的執行狀態,并 負責Map節點執行的同步控制。
2)數據/代碼互定位:
為了減少數據通信,一個基本原則是本地化數據處理,即一個計算節點盡可能處理其本地磁盤上所分布存儲的數據,這實現了代碼向 數據的遷移;當無法進行這種本地化數據處理時,再尋找其他可用節點并將數據從網絡上傳送給該節點(數據向代碼遷移),但將盡可能從數據所在的本地機架上尋 找可用節點以減少通信延遲。
3)系統優化:
為了減少數據通信開銷,中間結果數據進入Reduce節點前會進行一定的合并處理;一個Reduce節點所處理的數據可能會來自多個 Map節點,為了避免Reduce計算階段發生數據相關性,Map節點輸出的中間結果需使用一定的策略進行適當的劃分處理,保證相關性數據發送到同一個 Reduce節點;此外,系統還進行一些計算性能優化處理,如對最慢的計算任務采用多備份執行、選最快完成者作為結果。
4)出錯檢測和恢復:
以低端商用服務器構成的大規模MapReduce計算集群中,節點硬件(主機、磁盤、內存等)出錯和軟件出錯是常態,因此 MapReduce需要能檢測并隔離出錯節點,并調度分配新的節點接管出錯節點的計算任務。同時,系統還將維護數據存儲的可靠性,用多備份冗余存儲機制提 高數據存儲的可靠性,并能及時檢測和恢復出錯的數據。
測試文本:
tom 20 8000
nancy 22 8000
ketty 22 9000
stone 19 10000
green 19 11000
white 39 29000
socrates 30 40000???MapReduce中,根據key進行分區、排序、分組
MapReduce會按照基本類型對應的key進行排序,如int類型的IntWritable,long類型的LongWritable,Text類型,默認升序排序
???為什么要自定義排序規則?現有需求,需要自定義key類型,并自定義key的排序規則,如按照人的salary降序排序,若相同,則再按age升序排序
以Text類型為例:
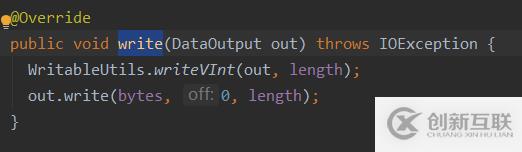
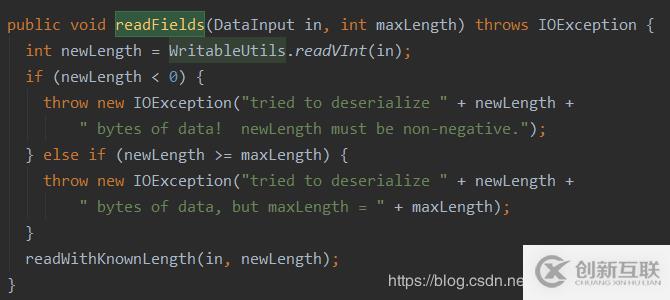
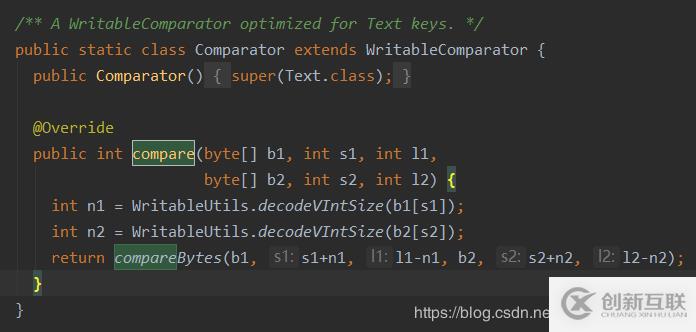
Text類實現了WritableComparable接口,并且有write()、readFields()和compare()方法readFields()方法:用來反序列化操作write()方法:用來序列化操作
所以要想自定義類型用來排序需要有以上的方法
自定義類代碼:
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Person implements WritableComparable<Person> {
private String name;
private int age;
private int salary;
public Person() {
}
public Person(String name, int age, int salary) {
//super();
this.name = name;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
@Override
public String toString() {
return this.salary + " " + this.age + " " + this.name;
}
//先比較salary,高的排序在前;若相同,age小的在前
public int compareTo(Person o) {
int compareResult1= this.salary - o.salary;
if(compareResult1 != 0) {
return -compareResult1;
} else {
return this.age - o.age;
}
}
//序列化,將NewKey轉化成使用流傳送的二進制
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeInt(age);
dataOutput.writeInt(salary);
}
//使用in讀字段的順序,要與write方法中寫的順序保持一致
public void readFields(DataInput dataInput) throws IOException {
//read string
this.name = dataInput.readUTF();
this.age = dataInput.readInt();
this.salary = dataInput.readInt();
}
}MapReuduce程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class SecondarySort {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//設置本地運行的mapreduce程序 jar包
configuration.set("mapreduce.job.jar","C:\\Users\\tanglei1\\IdeaProjects\\Hadooptang\\target\\com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, SecondarySort.class.getSimpleName());
FileSystem fileSystem = FileSystem.get(URI.create(args[1]), configuration);
if (fileSystem.exists(new Path(args[1]))) {
fileSystem.delete(new Path(args[1]), true);
}
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Person.class);
job.setMapOutputValueClass(NullWritable.class);
//設置reduce的個數
job.setNumReduceTasks(1);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class MyMap extends
Mapper<LongWritable, Text, Person, NullWritable> {
//LongWritable:輸入參數鍵類型,Text:輸入參數值類型
//Persion:輸出參數鍵類型,NullWritable:輸出參數值類型
@Override
//map的輸出值是鍵值對<K,V>,NullWritable說關心V的值
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//LongWritable key:輸入參數鍵值對的鍵,Text value:輸入參數鍵值對的值
//獲得一行數據,輸入參數的鍵(距首行的位置),Hadoop讀取數據的時候逐行讀取文本
//fields:代表著文本一行的的數據
String[] fields = value.toString().split(" ");
// 本列中文本一行數據:nancy 22 8000
String name = fields[0];
//字符串轉換成int
int age = Integer.parseInt(fields[1]);
int salary = Integer.parseInt(fields[2]);
//在自定義類中進行比較
Person person = new Person(name, age, salary);
context.write(person, NullWritable.get());
}
}
public static class MyReduce extends
Reducer<Person, NullWritable, Person, NullWritable> {
@Override
protected void reduce(Person key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
}運行結果:
40000 30 socrates
29000 39 white
11000 19 green
10000 19 stone
9000 22 ketty
8000 20 tom
8000 22 nancy另外有需要云服務器可以了解下創新互聯cdcxhl.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
本文標題:MapReduce如何實現自定義排序-創新互聯
網頁鏈接:http://vcdvsql.cn/article42/jsshc.html
成都網站建設公司_創新互聯,為您提供電子商務、品牌網站建設、虛擬主機、外貿網站建設、Google、云服務器
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 網站建設之網站導航設計 2022-08-16
- 湛江網站開發:網站導航怎么設計制作才夠炫,更能吸引用戶的! 2022-12-30
- 網站導航優化是什么 2021-11-01
- 網站導航、網站頁面的布局的方法 2019-01-22
- 網站導航系統設計有哪些注意事項 2022-05-05
- 網站導航如何做SEO優化?創新互聯告訴你 2014-04-30
- 沈陽網站開發之網站導航有哪些分類? 2016-08-19
- 「網站導航模塊」個人網站導航模塊設計重要性 2016-05-14
- 深圳網站制作分享網站導航如何設計 2014-09-27
- 網站導航結構優化的方法有那些 2016-11-04
- 怎樣做好網站導航設計交換鏈接原則 2021-05-31
- 網站導航的設計是建設網站的重點 2019-02-09