在IDEA中編寫spark程序-創新互聯
這里以一個scala版本的word count 程序為例:
①創建一個maven項目:
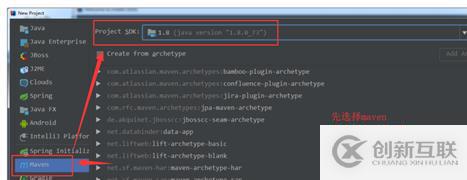
②填寫maven的GAV: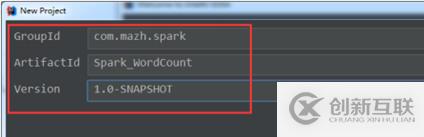
③填寫項目名稱: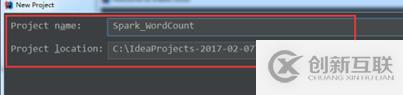
④ 創建好 maven 項目后,點擊 Enable Auto-Import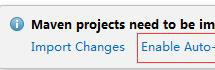
⑤配置pom.xml文件:

<properties>
<project.build.sourceEncoding>UTF8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.3.1</spark.version>
<hadoop.version>2.7.6</hadoop.version>
<scala.compat.version>2.11</scala.compat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>編寫代碼:
object WordCount {
def main(args: Array[String]): Unit = {
//獲取集群入口
val conf: SparkConf = new SparkConf()
conf.setAppName("WordCount")
val sc = new SparkContext(conf)
//從 HDFS 中讀取文件
val lineRDD: RDD[String] = sc.textFile("hdfs://zzy/data/input/words.txt")
//做數據處理
val wordRDD: RDD[String] = lineRDD.flatMap(line=>line.split("\\s+"))
val wordAndCountRDD: RDD[(String, Int)] = wordRDD.map(word=>(word,1))
//將結果寫入到 HDFS 中
wordAndCountRDD.reduceByKey(_+_).saveAsTextFile("hdfs://zzy/data/output")
//關閉編程入口
sc.stop()
}
}打jar包:
在pom.xml中加入相應的插件:
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
</plugins>
</pluginManagement>
</build>然后:
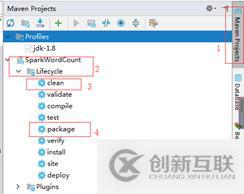
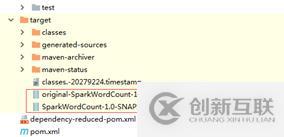
將jar包上傳到集群中運行:
spark-submit \
--class com.zy.scala.WordCount \
--master yarn \
--deploy-mode cluster \
--driver-memory 200M \
--executor-memory 200M \
--total-executor-cores 1 \
hdfs://zzy/data/jar/ScalaTest-1.0-SNAPSHOT.jar \此時在yarn的web就能查看相應的程序的運行進度。
這時候,程序總是異常的結束:
我就使用:
yarn logs -applicationId application_1522668922644_40211 查看了一下報錯信息。
結果:not fount class :scala.WordCount.
然后我就在想是不是jar包出現了問題,我就打開了,之前上傳的jar包,果然根本找不到 我打jar的程序,只有一個,META-INF,此時 我就百思不得不得解,然后由重新反復嘗試了很多次,還是解決不了。后來吃個飯回來,突然想到是不是maven不能將scala編寫的程序打成jar包,后來通過百度,發現了:
maven 默認只編譯java 的文件,而不會編譯scala 文件。但是maven 提供了 能夠編譯scala 的類庫。
好心的博主:scala 在IDEA打jar包相關問題:https://blog.csdn.net/freecrystal_alex/article/details/78296851
然后 我修改了pom.xml文件:
http://down.51cto.com/data/2457588
按照上述的步驟,重新的向集群提交了一次任務,結果不盡人意,又出錯了:
但是這一次錯誤和上次的不同(說明上一個問題已經解決):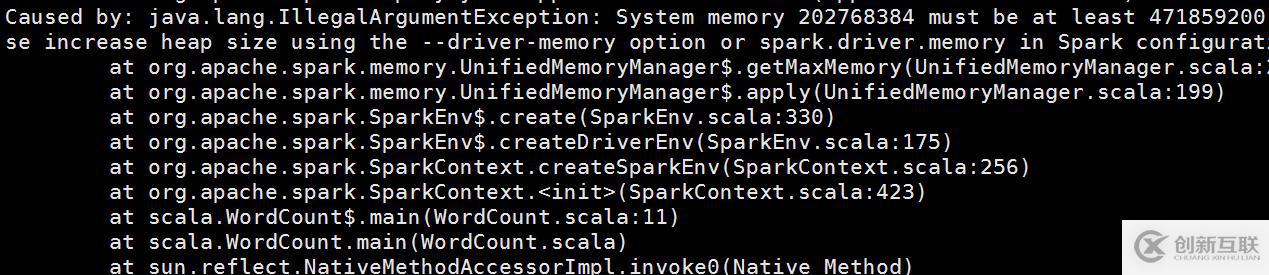
這才明白,原來是Driver進程分配的內存太小了,最少應該大于450M,之后我又修改了 --driver-memory 512M --executor-memory 512M,重新提交任務。結果運行成功!!!
注意:
這里使用的是yarn的任務調用,不是spark自帶的standalone,需要加入的參數:
--master yarn
--deploy-mode cluster
這里的--deploy-mode,使用的是cluster集群模式,client是客戶端模式。
二者的區別是:client表示,在哪個節點提交,Driver就哪里啟動,而cluster模式表示當將Driver放入到集群中啟動。
另外有需要云服務器可以了解下創新互聯scvps.cn,海內外云服務器15元起步,三天無理由+7*72小時售后在線,公司持有idc許可證,提供“云服務器、裸金屬服務器、高防服務器、香港服務器、美國服務器、虛擬主機、免備案服務器”等云主機租用服務以及企業上云的綜合解決方案,具有“安全穩定、簡單易用、服務可用性高、性價比高”等特點與優勢,專為企業上云打造定制,能夠滿足用戶豐富、多元化的應用場景需求。
文章名稱:在IDEA中編寫spark程序-創新互聯
文章鏈接:http://vcdvsql.cn/article44/didcee.html
成都網站建設公司_創新互聯,為您提供小程序開發、品牌網站設計、面包屑導航、標簽優化、關鍵詞優化、外貿建站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 網頁設計公司:增加網站流量的辦法 2021-08-17
- 經典網頁設計公司觀點? 2022-06-27
- 3個不可靠的網頁設計公司的跡象 2022-08-28
- 建站價格影響因素有哪些-成都網頁設計公司 2023-03-02
- 【網頁設計公司】創新互聯教你如何提升網站收 2016-11-12
- 網頁設計公司需要哪些必要的軟件來設計網頁 2016-11-15
- 創新互聯:網頁設計公司對網站建站影響 2022-12-01
- 專業網頁設計公司怎么做網站布局設計? 2020-12-20
- 網頁設計公司哪家好? 2022-09-02
- 專做網頁設計的公司排名,怎么選擇網頁設計公司 2014-01-09
- 北京網頁設計公司:了解客戶需求 做有效益的網站 2016-10-29
- 網頁設計公司怎樣制作網頁 2022-11-29