Python爬蟲之正則表達式是什么-創新互聯
創新互聯www.cdcxhl.cn八線動態BGP香港云服務器提供商,新人活動買多久送多久,劃算不套路!

這篇文章主要介紹Python爬蟲之正則表達式是什么,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
正則表達式
正則表達式(regular expression)簡稱(regex), 是一種處理字符串的強大工具。它作為一種字符串的匹配模式,用于查看指定字符串是否存在于被查找字符串中,替換指定字符串,或是通過匹配模式查找指定字符串。正則表達式在不同的語言里面,語法也基本是相同的,也就是說學會了一種語言的正則,再學習其它的就很快了。
其主要的匹配過程是:
先用正則語法定義一個規則(pattern)
然后用這個規則與你download的網頁字符串進行對比,根據pattern提取你想要的數據。
好了,讓我們看看Python正則表達式的語法:
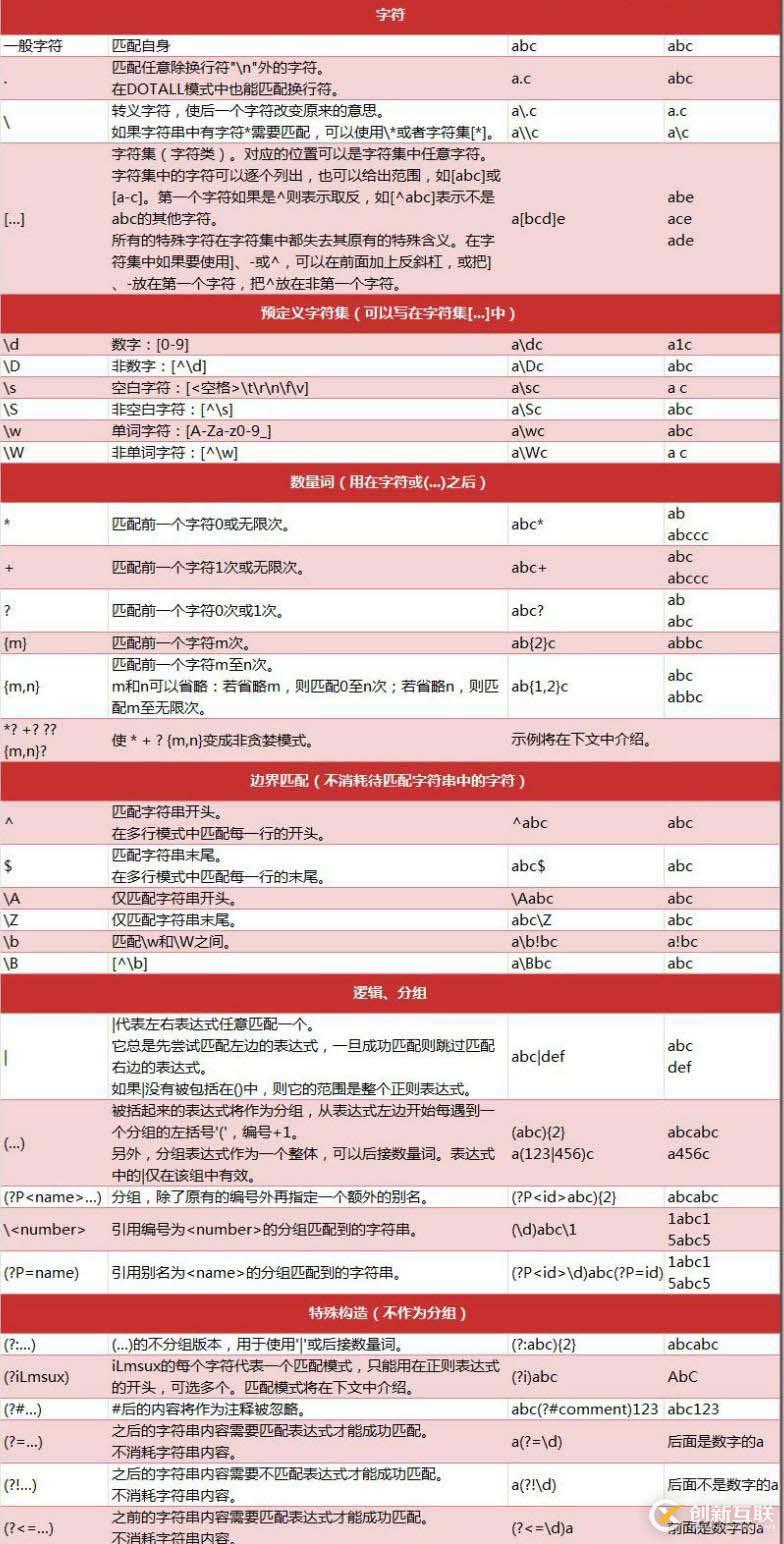
我們舉一個常遇到的一個例子。比如,一個人的郵箱是這樣的lixiaomei@qq.com,那么我們如何從一大堆的字符串把它提取出來呢?
根據正則語法,我們可以這樣來定義一個pattern:\w+@\w+\.com
為什么這么定義呢?讓我們來看看。
"\w" 的意思是單詞字符[A-Za-z0-9_]。注意是 "單字符串",可以是A-Z或者a-z或者0-9或者_各國語言中的任意一個。
"+" 匹配前一個字符1次或無限次。那么 "\w+" 組合起來的意思就是匹配一次或無限多次的但字符串[A-Za-z0-9]組合的字符串。
"@" 是郵箱的特定字符,所以固定不變。
第二個 "\w+" 與前一個是一個道理,匹配一次或無限次的[A-Za-z0-9]組合的字符串。
" \. " 的含義是將" . "轉義,因為 " . " 本身也是正則語法中的其中一種,為了真的得到 ".com" 而不是帶有功能的" . ", 所以在前面加上 "\" 轉義字符。
所以,不論是例子中的 lixiaomei@qq.com,還是其它如xiaoxiao@126.com之類的郵箱,只要符合規則全都可以匹配,怎么樣,簡單吧!
問題來了,有的郵箱格式可是xiaoxiao@xxx.xxx.com這樣的!這樣的話上面的規則就不能用了。沒錯,上面的規則比較特殊,只能匹配單一格式的郵箱名。那么怎樣設計一個滿足以上兩種格式的pattern呢?看看這個:\w+@(\w+\.)?\w+\.com
這個又是什么意思?
\w+@與之前一樣
(\w+\.)?中的“ ? ”是匹配0次或1次括號分組內的匹配內容,"()" 則表示被括內容是一個分組,分組序號從pattern字符串起始往后依次排列。分組的概念非常重要,在后面 “匹配對象方法” 章節會著重介紹其如何使用。
\w+\.com與之前一樣
因為是匹配0次或1次,那么就意味著括號內的部分是可有可無的,所以這個pattern就可能匹配兩種郵箱格式。
“?”是0次或1次,那么 \w+@(\w+\.)*\w+\.com 模式就更厲害了," * " 可以匹配0次或無限次。
re模塊核心函數
上面簡單的介紹了正則表達式的pattern是如何設置的,那么下一步我們就可以開始我們的提取工作了。在Python的re模塊中有幾個核心的函數專門用來進行匹配和查找。
compile()函數
函數定義: compile(pattern, flag=0)
函數描述:編譯正則表達式pattern,然后返回一個正則表達式對象。
為什么要對pattern進行編譯呢?《Python核心編程 》里面是這樣解釋的:
使用預編譯的代碼對象比直接使用字符串要快,因為解釋器在執行字符串形式的代碼前都必須把字符串編譯成代碼對象。
同樣的概念也適用于正則表達式。在模式匹配發生之前,正則表達式模式必須編譯成正則表達式對象。由于正則表達式在執行過程中將進行多次比較操作,因此強烈建議使用預編譯。而且,既然正則表達式的編譯是必需的,那么使用預編譯來提升執行性能無疑是明智之舉。re.compile()能夠提供此功能。
原來是這樣,由于compile的使用很簡單,所以將在以下幾個匹配查找的函數使用方法中體現。
match()函數
函數定義: match(pattern, string, flag=0)
函數描述:只從字符串的最開始與pattern進行匹配,匹配成功返回匹配對象(只有一個結果),否則返回None。
import re s1 = '我12345abcde' s2 = '.12345abcde' # pattern字符串前加 “ r ” 表示原生字符串 pattern = r'\w.+' # 編譯pattern pattern_compile = re.compile(pattern) # 對s1和s2分別匹配 result1 = re.match(pattern, s1) result2 = re.match(pattern, s2) print(result1) print(result2) >>> <_sre.SRE_Match object; span=(0, 11), match='我12345abcde'>
注意:
match函數是從最開始匹配的,意思是如果第一個字符就不匹配,那就直接玩完,返回None。
Python中pattern字符串前面的 " r " 代表了原生字符串的意思。
search()函數
函數定義: search(pattern, string, flag=0)
函數描述:與match()工作的方式一樣,但是search()不是從最開始匹配的,而是從任意位置查找第一次匹配的內容。如果所有的字串都沒有匹配成功,返回None,否則返回匹配對象。
import re s1 = '我12345abcde' s2 = '+?!@12345abcde' # pattern字符串前加 “ r ” 表示原生字符串 pattern = r'\w.+' pattern_compile = re.compile(pattern) result1 = re.search(pattern_compile, s1) result2 = re.search(pattern_compile, s2) print(result1) print(result2) >>> <_sre.SRE_Match object; span=(0, 11), match='我12345abcde'> >>> <_sre.SRE_Match object; span=(4, 14), match='12345abcde'>
可以看到無論字符串最開始是否匹配pattern,只要在字符串中找到匹配的部分就會作為結果返回(注意是第一次匹配的對象)。
findall()函數
函數定義: findall(pattern, string [,flags])
函數描述:查找字符串中所有(非重復)出現的正則表達式模式,并返回一個匹配列表
import re s1 = '我12345abcde' s2 = '+?!@12345abcde@786ty' # pattern字符串前加 “ r ” 表示原生字符串 pattern = r'\d+' pattern_compile = re.compile(pattern) result1 = re.match(pattern_compile, s2) result2 = re.search(pattern_compile, s1) result3 = re.findall(pattern_compile, s2) print(result1) print(result2) print(result3) >>> None >>> <_sre.SRE_Match object; span=(1, 6),
上面同時列出了match、search、findall三個函數用法。findall與match和search不同的地方是它會返回一個所有無重復匹配的列表。如果沒找到匹配部分,就返回一個空列表。
以上是Python爬蟲之正則表達式是什么的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注創新互聯-成都網站建設公司行業資訊頻道!
文章名稱:Python爬蟲之正則表達式是什么-創新互聯
標題鏈接:http://vcdvsql.cn/article8/isjop.html
成都網站建設公司_創新互聯,為您提供網站策劃、ChatGPT、微信小程序、網站制作、手機網站建設、外貿建站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 設置面包屑導航,能提升蜘蛛抓取么? 2023-04-04
- 面包屑導航在網站優化中有用嗎? 2022-09-26
- 百度快照推廣網站外部鏈接的公道機關:需要從導航欄、側邊欄、面包屑導航開始籌謀 2023-01-23
- 做seo我們要避免做這些對我們的網站 2022-06-20
- 面包屑導航:什么是面包屑導航呢 2021-11-27
- 面包屑導航優化原則都有什么? 2022-06-14
- 網站建設中面包屑導航功能的重要性 2022-08-20
- 網站設計中面包屑導航的作用 2023-03-12
- 【網站建設】面包屑導航對SEO優化的作用有哪些? 2022-03-26
- 【網站建設】網站建設中面包屑導航的設計技巧有哪些? 2022-03-22
- 成都網絡SEO要怎么做面包屑導航? 2023-04-07
- 網站面包屑導航對網站優化的作用以及影響 2014-11-17