python如何批量統(tǒng)計(jì)xml中各類目標(biāo)的數(shù)量-創(chuàng)新互聯(lián)
這篇文章給大家分享的是有關(guān)python如何批量統(tǒng)計(jì)xml中各類目標(biāo)的數(shù)量的內(nèi)容。小編覺(jué)得挺實(shí)用的,因此分享給大家做個(gè)參考,一起跟隨小編過(guò)來(lái)看看吧。

代碼如下:
# -*- coding:utf-8 -*-
import os
import xml.etree.ElementTree as ET
import numpy as np
np.set_printoptions(suppress=True, threshold=np.nan)
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree=ET.parse(xml_path+filename)
objects=[]
for obj in tree.findall('object'):
obj_struct={}
obj_struct['name']=obj.find('name').text
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im=Image.open(image_path+filename)
W=im.size[0]
H=im.size[1]
area=W*H
im_info=[W,H,area]
return im_info
if __name__ == '__main__':
xml_path='C:/Users/nansbas/Desktop/hebin/03/'
filenamess=os.listdir(xml_path)
filenames=[]
for name in filenamess:
name=name.replace('.xml','')
filenames.append(name)
recs={}
obs_shape={}
classnames=[]
num_objs={}
obj_avg={}
for i,name in enumerate(filenames):
recs[name]=parse_obj(xml_path, name+ '.xml' )
for name in filenames:
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']]=1
else:
num_objs[object['name']]+=1
if object['name'] not in classnames:
classnames.append(object['name'])
for name in classnames:
print('{}:{}個(gè)'.format(name,num_objs[name]))
print('信息統(tǒng)計(jì)算完畢。')
補(bǔ)充知識(shí):Python對(duì)目標(biāo)檢測(cè)數(shù)據(jù)集xml文件操作(統(tǒng)計(jì)目標(biāo)種類、數(shù)量、面積、比例等&修改目標(biāo)名字)
1. 根據(jù)xml文件統(tǒng)計(jì)目標(biāo)種類以及數(shù)量
# -*- coding:utf-8 -*-
#根據(jù)xml文件統(tǒng)計(jì)目標(biāo)種類以及數(shù)量
import os
import xml.etree.ElementTree as ET
import numpy as np
np.set_printoptions(suppress=True, threshold=np.nan)
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree=ET.parse(xml_path+filename)
objects=[]
for obj in tree.findall('object'):
obj_struct={}
obj_struct['name']=obj.find('name').text
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im=Image.open(image_path+filename)
W=im.size[0]
H=im.size[1]
area=W*H
im_info=[W,H,area]
return im_info
if __name__ == '__main__':
xml_path='/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/Annotations/'
filenamess=os.listdir(xml_path)
filenames=[]
for name in filenamess:
name=name.replace('.xml','')
filenames.append(name)
recs={}
obs_shape={}
classnames=[]
num_objs={}
obj_avg={}
for i,name in enumerate(filenames):
recs[name]=parse_obj(xml_path, name+ '.xml' )
for name in filenames:
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']]=1
else:
num_objs[object['name']]+=1
if object['name'] not in classnames:
classnames.append(object['name'])
for name in classnames:
print('{}:{}個(gè)'.format(name,num_objs[name]))
print('信息統(tǒng)計(jì)算完畢。')
2.根據(jù)xml文件統(tǒng)計(jì)目標(biāo)的平均長(zhǎng)度、寬度、面積以及每一個(gè)目標(biāo)在原圖中的占比
# -*- coding:utf-8 -*-
#統(tǒng)計(jì)
# 計(jì)算每一個(gè)目標(biāo)在原圖中的占比
# 計(jì)算目標(biāo)的平均長(zhǎng)度、
# 計(jì)算平均寬度,
# 計(jì)算平均面積、
# 計(jì)算目標(biāo)平均占比
import os
import xml.etree.ElementTree as ET
import numpy as np
#np.set_printoptions(suppress=True, threshold=np.nan) #10,000,000
np.set_printoptions(suppress=True, threshold=10000000) #10,000,000
import matplotlib
from PIL import Image
def parse_obj(xml_path, filename):
tree = ET.parse(xml_path + filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def read_image(image_path, filename):
im = Image.open(image_path + filename)
W = im.size[0]
H = im.size[1]
area = W * H
im_info = [W, H, area]
return im_info
if __name__ == '__main__':
image_path = '/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/JPEGImages/'
xml_path = '/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/Annotations/'
filenamess = os.listdir(xml_path)
filenames = []
for name in filenamess:
name = name.replace('.xml', '')
filenames.append(name)
print(filenames)
recs = {}
ims_info = {}
obs_shape = {}
classnames = []
num_objs={}
obj_avg = {}
for i, name in enumerate(filenames):
print('正在處理 {}.xml '.format(name))
recs[name] = parse_obj(xml_path, name + '.xml')
print('正在處理 {}.jpg '.format(name))
ims_info[name] = read_image(image_path, name + '.jpg')
print('所有信息收集完畢。')
print('正在處理信息......')
for name in filenames:
im_w = ims_info[name][0]
im_h = ims_info[name][1]
im_area = ims_info[name][2]
for object in recs[name]:
if object['name'] not in num_objs.keys():
num_objs[object['name']] = 1
else:
num_objs[object['name']] += 1
#num_objs += 1
ob_w = object['bbox'][2] - object['bbox'][0]
ob_h = object['bbox'][3] - object['bbox'][1]
ob_area = ob_w * ob_h
w_rate = ob_w / im_w
h_rate = ob_h / im_h
area_rate = ob_area / im_area
if not object['name'] in obs_shape.keys():
obs_shape[object['name']] = ([[ob_w,
ob_h,
ob_area,
w_rate,
h_rate,
area_rate]])
else:
obs_shape[object['name']].append([ob_w,
ob_h,
ob_area,
w_rate,
h_rate,
area_rate])
if object['name'] not in classnames:
classnames.append(object['name']) # 求平均
for name in classnames:
obj_avg[name] = (np.array(obs_shape[name]).sum(axis=0)) / num_objs[name]
print('{}的情況如下:*******\n'.format(name))
print(' 目標(biāo)平均W={}'.format(obj_avg[name][0]))
print(' 目標(biāo)平均H={}'.format(obj_avg[name][1]))
print(' 目標(biāo)平均area={}'.format(obj_avg[name][2]))
print(' 目標(biāo)平均與原圖的W比例={}'.format(obj_avg[name][3]))
print(' 目標(biāo)平均與原圖的H比例={}'.format(obj_avg[name][4]))
print(' 目標(biāo)平均原圖面積占比={}\n'.format(obj_avg[name][5]))
print('信息統(tǒng)計(jì)計(jì)算完畢。')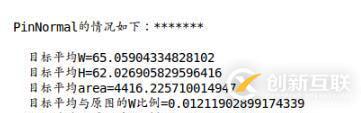
3.修改xml文件中某個(gè)目標(biāo)的名字為另一個(gè)名字
#修改xml文件中的目標(biāo)的名字,
import os, sys
import glob
from xml.etree import ElementTree as ET
# 批量讀取Annotations下的xml文件
# per=ET.parse(r'C:\Users\rockhuang\Desktop\Annotations\000003.xml')
xml_dir = r'/home/dlut/網(wǎng)絡(luò)/make_database/數(shù)據(jù)集——合集/VOCdevkit/VOC2018/Annotations'
xml_list = glob.glob(xml_dir + '/*.xml')
for xml in xml_list:
print(xml)
per = ET.parse(xml)
p = per.findall('/object')
for oneper in p: # 找出person節(jié)點(diǎn)
child = oneper.getchildren()[0] # 找出person節(jié)點(diǎn)的子節(jié)點(diǎn)
if child.text == 'PinNormal': #需要修改的名字
child.text = 'normal bolt' #修改成什么名字
if child.text == 'PinDefect': #需要修改的名字
child.text = 'defect bolt-1' #修改成什么名字
per.write(xml)
print(child.tag, ':', child.text)
感謝各位的閱讀!關(guān)于“python如何批量統(tǒng)計(jì)xml中各類目標(biāo)的數(shù)量”這篇文章就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,讓大家可以學(xué)到更多知識(shí),如果覺(jué)得文章不錯(cuò),可以把它分享出去讓更多的人看到吧!
當(dāng)前文章:python如何批量統(tǒng)計(jì)xml中各類目標(biāo)的數(shù)量-創(chuàng)新互聯(lián)
文章起源:http://vcdvsql.cn/article8/jidip.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供網(wǎng)頁(yè)設(shè)計(jì)公司、網(wǎng)站排名、手機(jī)網(wǎng)站建設(shè)、面包屑導(dǎo)航、軟件開發(fā)、營(yíng)銷型網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容

- 成都網(wǎng)站建設(shè):靜態(tài)發(fā)布和動(dòng)態(tài)發(fā)布的選擇是有技巧的 2017-01-10
- 靜態(tài)網(wǎng)頁(yè)對(duì)seo提升的益處是啥? 2014-01-20
- 靜態(tài)網(wǎng)頁(yè)與動(dòng)態(tài)網(wǎng)頁(yè)的區(qū)別和優(yōu)勢(shì) 2016-11-11
- 成都seo:文章url偽靜態(tài)的好處及對(duì)網(wǎng)站優(yōu)化的影響 2014-05-30
- 成都網(wǎng)站建設(shè)有限公司談動(dòng)態(tài)網(wǎng)站和靜態(tài)網(wǎng)站的優(yōu)劣勢(shì) 2016-07-06
- 營(yíng)銷型網(wǎng)站建設(shè)中什么是動(dòng)態(tài)網(wǎng)站、靜態(tài)網(wǎng)站 2022-11-17
- 焦作網(wǎng)站建設(shè)-靜態(tài)網(wǎng)站的特點(diǎn)和優(yōu)勢(shì) 2021-09-29
- 靜態(tài)網(wǎng)站設(shè)計(jì)的優(yōu)缺點(diǎn) 2019-04-25
- 靜態(tài)網(wǎng)頁(yè)的優(yōu)勢(shì)是哪些? 2016-10-02
- 做網(wǎng)站建設(shè)為什么要選擇靜態(tài)頁(yè)面? 2013-05-11
- 談?wù)劸W(wǎng)站優(yōu)化當(dāng)中的偽靜態(tài)優(yōu)化技術(shù) 2016-05-11
- 成都網(wǎng)站建設(shè)開發(fā)營(yíng)銷型網(wǎng)站的時(shí)候?yàn)槭裁唇oURL選擇靜態(tài)的? 2016-11-01