KotlinFlow背壓和線程切換竟然如此相似-創新互聯
上篇分析了Kotlin Flow原理,大部分操作符實現比較簡單,相較而言背壓和線程切換比較復雜,遺憾的是,縱觀網上大部分文章,關于Flow背壓和協程切換這塊的原理說得比較少,語焉不詳,鑒于此,本篇重點分析兩者的原理及使用。
通過本篇文章,你將了解到:
1. 什么是背壓?
- 什么是背壓?
- 如何處理背壓?
- Flow buffer的原理
- Flow 線程切換的使用
- Flow 線程切換的原理
先看自然界的水流:
為了充分利用水資源,人類建立了大壩,以大壩為分界點將水流分為上游和下游。
當上游的流速大于下游的流速,日積月累,最終導致大壩溢出,此種現象稱為背壓的出現
而對于Kotlin里的Flow,也有上游(生產者)、下游(消費者)的概念,如:
suspend fun testBuffer1() {var flow = flow {//生產者
(1..3).forEach {println("emit $it")
emit(it)
}
}
flow.collect {//消費者
println("collect:$it")
}
}通過collect操作符觸發了流,從生產者生產數據(flow閉包),到消費者接收并處理數據(collect閉包),這就完成了流從上游到下游的一次流動過程。
2. 如何處理背壓?模擬一個生產者消費者速度不一致的場景:
suspend fun testBuffer3() {var flow = flow {(1..3).forEach {delay(1000)
println("emit $it")
emit(it)
}
}
var time = measureTimeMillis {flow.collect {delay(2000)
println("collect:$it")
}
}
println("use time:${time} ms")
}計算流從生產到消費的整個時間:
生產者的速度比消費者的速度快,而它倆都是在同一個線程里順序執行的,生產者必須等待消費者消費完畢后才會進行下一次生產。
因此,整個流的耗時=生產者耗時(3 * 1000ms)+消費者耗時(3 * 2000ms)=9s。
顯而易見,消費者影響了生產者的速度,這種情況下該怎么優化呢?
最簡單的解決方案:
生產者和消費者分別在不同的線程執行
如:
suspend fun testBuffer4() {var flow = flow {(1..3).forEach {delay(1000)
println("emit $it in thread:${Thread.currentThread()}")
emit(it)
}
}.flowOn(Dispatchers.IO)
var time = measureTimeMillis {flow.collect {delay(2000)
println("collect:$it in thread:${Thread.currentThread()}")
}
}
println("use time:${time} ms")
}添加了flowOn()函數,它的存在使得它前面的代碼在指定的線程里執行,如flow閉包了的代碼都在IO線程執行,也就是生產者在IO線程執行。
而消費者在當前線程執行,因此兩者無需相互等待,節省了總時間:
確實是減少了時間,提升了效率。但我們知道開啟線程代價還是挺大的,既然都在協程里運行了,能否借助協程的特性:協程掛起不阻塞線程 來完成此事呢?
此時,Buffer出場了,先看看它是如何表演的:
suspend fun testBuffer5() {var flow = flow {(1..3).forEach {delay(1000)
println("emit $it in thread:${Thread.currentThread()}")
emit(it)
}
}.buffer(5)
var time = measureTimeMillis {flow.collect {delay(2000)
println("collect:$it in thread:${Thread.currentThread()}")
}
}
println("use time:${time} ms")
}這次沒有使用flowOn,取而代之的是buffer。
運行結果如下: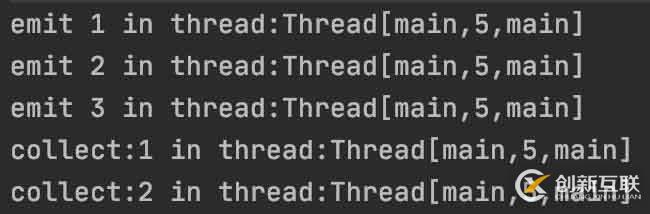
可以看出,生產者消費者都是在同一線程執行,但總耗時卻和不在同一線程運行時相差無幾。
那么它是如何做到的呢?這就得從buffer的源碼說起。
先看看沒有buffer時的耗時:
suspend fun testBuffer3() {var flow = flow {(1..3).forEach {delay(1000)
println("emit $it")
emit(it)
}
}
var time = measureTimeMillis {flow.collect {delay(2000)
println("collect:$it")
}
}
println("use time:${time} ms")
}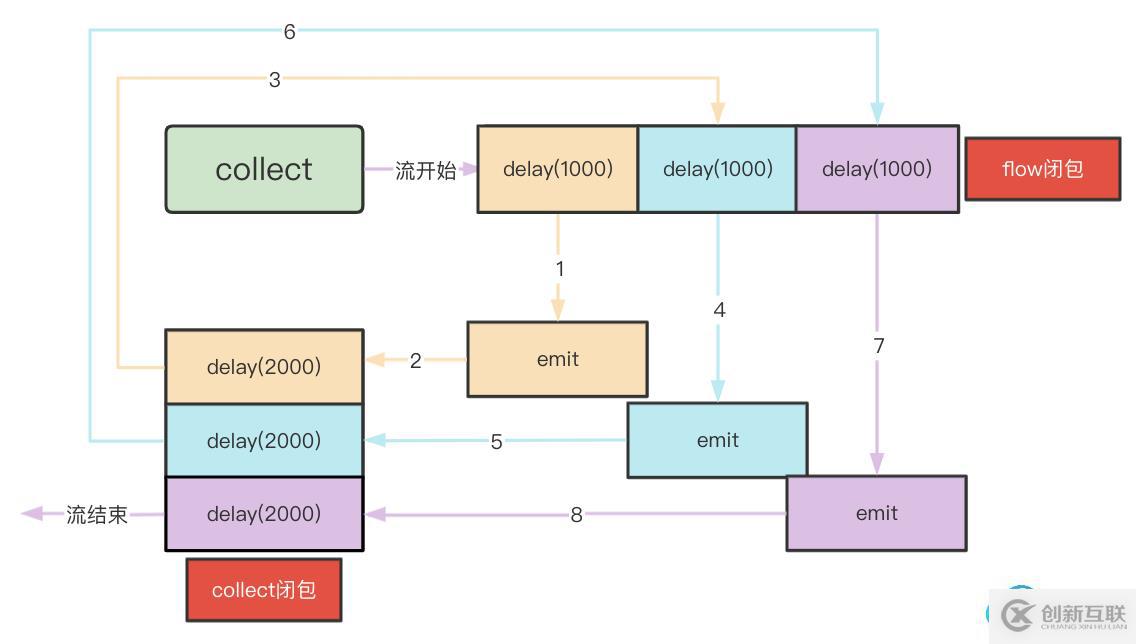
從collect開始,依次執行flow閉包,通過emit調用到collect閉包,因為flow閉包里包含了幾次emit,因此整個流程會有幾次發射。
如上圖,從步驟1到步驟8,因為是在同一個線程里,因此是串行執行的,整個流的耗時即為生產者到消費者(步驟1~步驟8)的耗時。
在沒看源碼之前,我們先猜測一下它的流程: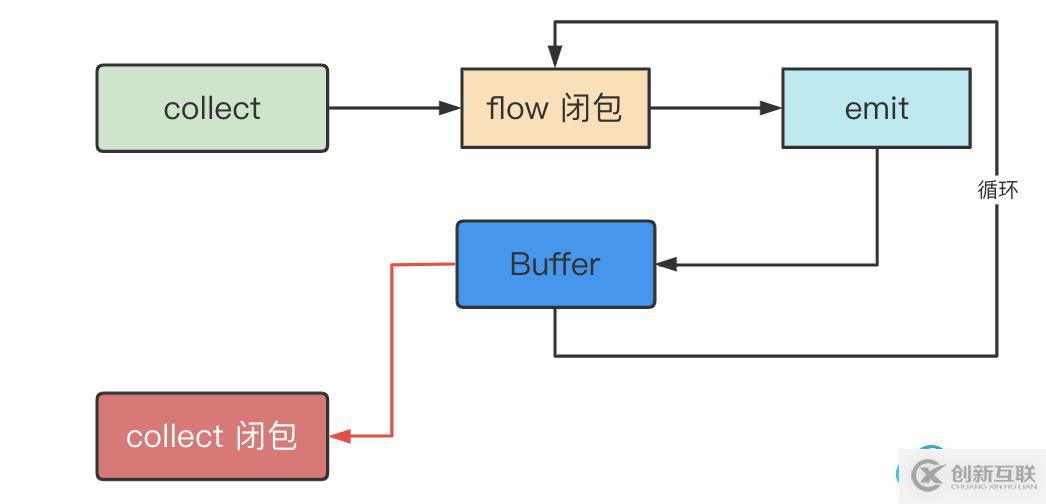
每次emit都發送到buffer里,然后立刻回來繼續發送,如此一來生產者沒有被消費者的速度拖累。
而消費者會檢測Buffer里是否有數據,有則取出來。
根據之前的經驗我們知道:collect調用到emit最后到buffer是線性調用的,放入buffer后繼續循環emit,那么問題來了:
是誰觸發了collect閉包的調用呢?
接下來深入源碼,探究答案。
buffer源碼流程分析創建Flow
public funFlow.buffer(capacity: Int = Channel.BUFFERED, onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND): Flow{var capacity = capacity//buffer容量
var onBufferOverflow = onBufferOverflow//buffer滿之后的處理策略
if (capacity == Channel.CONFLATED) {capacity = 0
onBufferOverflow = BufferOverflow.DROP_OLDEST
}
// create a flow
return when (this) {is FusibleFlow ->fuse(capacity = capacity, onBufferOverflow = onBufferOverflow)
//走else 分支,構造ChannelFlowOperatorImpl
else ->ChannelFlowOperatorImpl(this, capacity = capacity, onBufferOverflow = onBufferOverflow)
}
} buffer 返回Flow實例,其間涉及幾個重要的類和函數: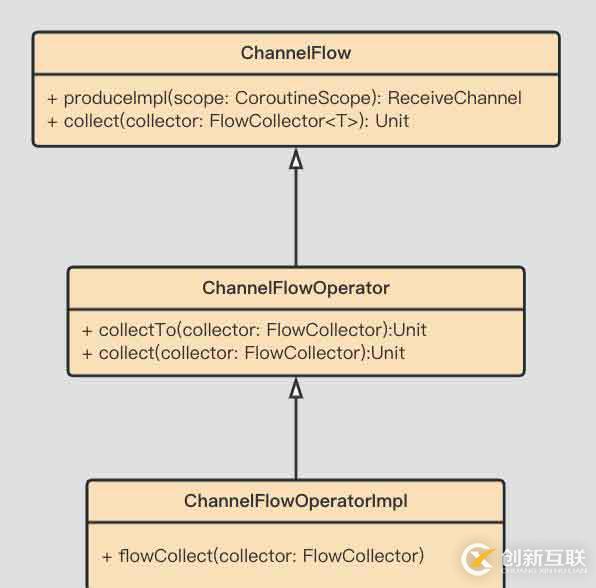
調用collect
當調用Flow.collect時:
public suspend inline funFlow.collect(crossinline action: suspend (value: T) ->Unit): Unit =
collect(object : FlowCollector{override suspend fun emit(value: T) = action(value)
}) 構造了匿名內部類FlowCollector,并實現了emit方法,它的實現為collect的閉包。
調用ChannelFlowOperatorImpl.collect最終會調用ChannelFlow.collect:
override suspend fun collect(collector: FlowCollector): Unit =
coroutineScope {collector.emitAll(produceImpl(this))
}
public open fun produceImpl(scope: CoroutineScope): ReceiveChannel=
scope.produce(context, produceCapacity, onBufferOverflow, start = CoroutineStart.ATOMIC, block = collectToFun)
produceImpl 創建了Channel,內部開啟了協程,返回ReceiveChannel。
再來看emitAll函數:
private suspend funFlowCollector.emitAllImpl(channel: ReceiveChannel, consume: Boolean) {ensureActive()
var cause: Throwable? = null
try {while (true) {//掛起等待Channel數據
val result = run {channel.receiveCatching() }
if (result.isClosed) {//Channel關閉后才會退出循環
result.exceptionOrNull()?.let {throw it }
break // returns normally when result.closeCause == null
}
//發送數據
emit(result.getOrThrow())
}
} catch (e: Throwable) {cause = e
throw e
} finally {if (consume) channel.cancelConsumed(cause)
}
} Channel此時并沒有數據,因此協程會掛起等待。
Channel發送
Channel什么時候有數據呢?當然是在調用了Channel.send()函數后。
前面提到過collect之后開啟了協程:
public open fun produceImpl(scope: CoroutineScope): ReceiveChannel=
scope.produce(context, produceCapacity, onBufferOverflow, start = CoroutineStart.ATOMIC, block = collectToFun)
internal val collectToFun: suspend (ProducerScope) ->Unit
get() = {collectTo(it) }
protected override suspend fun collectTo(scope: ProducerScope) =
flowCollect(SendingCollector(scope)) 此時傳入的參數為:collectToFun,最后構造了:
public class SendingCollector(
private val channel: SendChannel) : FlowCollector{override suspend fun emit(value: T): Unit = channel.send(value)
} 當協程得到執行時,會調用collectToFun–>collectTo(it)–>flowCollect(SendingCollector(scope)),最終調用到:
#ChannelFlowOperatorImpl
override suspend fun flowCollect(collector: FlowCollector) =
flow.collect(collector) 而該flow為最開始的flow,collector為SendingCollector。
flow.collect后會調用到flow的閉包,進而調用到emit函數:
private fun emit(uCont: Continuation, value: T): Any? {val currentContext = uCont.context
currentContext.ensureActive()
//...
completion = uCont
return emitFun(collector as FlowCollector, value, this as Continuation)
} emitFun本質上會調用collector里的emit函數,而此時的collector即為SendingCollector,最后調用channel.send(value)
如此一來,Channel就將數據發送出去了,此時channel.receiveCatching()被喚醒,接下來執行emit(result.getOrThrow()),這函數最后會流轉到最初始的collect的閉包里。
上面的分析即為生產者到消費者的流轉過程,單看源碼可能比較亂,看圖解惑:

紅色部分和綠色部分分別為不同的協程,它倆的關聯點即是藍色部分。
buffer為啥能提升效率Flow buffer的本質上是利用了Channel進行數據的發送和接收
前面分析過無buffer時生產者消費者的流程圖,作為對比,我們也將加入buffer后生產者消費者的流程圖。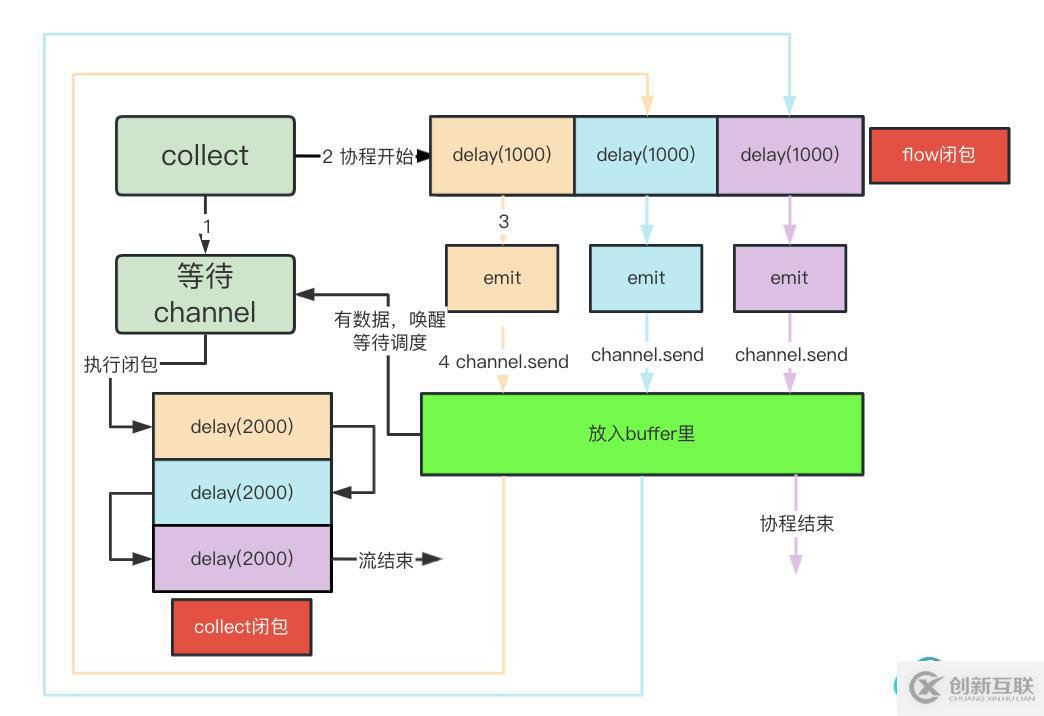
還是以相同的demo,闡述其流程:
- 生產者掛起1s,當1s結束后調用emit發射數據,此時數據放入buffer里,生產者調用delay繼續掛起
- 此時消費者被喚醒,然后掛起 2s等待
- 第2s到來之時,生產者調用emit發送數據到buffer里,繼續掛起
- 第2s到來之時,消費者結束掛起,消費數據,然后繼續掛起2s
- 第3s到來之時,生產者繼續生產數據,而后生產者退出生產
- 第5s到來之時,消費者掛起結束,消費數據,然后繼續掛起2s
- 第7s到來之時,消費者掛起結束,消費結束,此時因為channel里已經沒有數據了,退出循環,最終消費者退出
由此可見,總共花費了7s。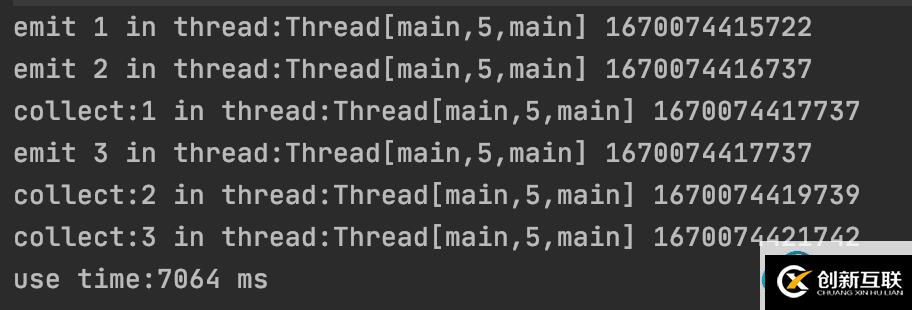
ps:協程調度時機不同,打印順序可能略有差異,但總體耗時不變。
至此,我們找到了buffer能夠提高效率的原因:
生產者、消費者運行在不同的協程,掛起操作不阻塞對方
拋出一個比較有意思的問題:以下代碼加buffer之后效率會有提升嗎?
suspend fun testBuffer6() {var flow = flow {(1..3).forEach {println("emit $it")
emit(it)
}
}
var time = measureTimeMillis {flow.collect {delay(2000)
println("collect:$it")
}
}
println("use time:${time} ms")
}在未實驗之前,如果你已經有答案,恭喜你已經弄懂了buffer的本質。
4. Flow 線程切換的使用suspend fun testBuffer4() {var flow = flow {(1..3).forEach {delay(1000)
println("emit $it in thread:${Thread.currentThread()}")
emit(it)
}
}.flowOn(Dispatchers.IO)
var time = measureTimeMillis {flow.collect {delay(2000)
println("collect:$it in thread:${Thread.currentThread()}")
}
}
println("use time:${time} ms")
}flowOn(Dispatchers.IO)表示其之前的操作符(函數)都在IO線程執行,如這里的意思是flow閉包里的代碼在IO線程執行。
而其之后的操作符(函數)在當前的線程執行。
通常用在子線程里獲取網絡數據(flow閉包),然后再collect閉包里(主線程)更新UI。
public funFlow.flowOn(context: CoroutineContext): Flow{checkFlowContext(context)
return when {context == EmptyCoroutineContext ->this
this is FusibleFlow ->fuse(context = context)
else ->ChannelFlowOperatorImpl(this, context = context)
}
} 看到這你可能已經有答案了:這不就和buffer一樣的方式嗎?
但仔細看,此處多了個上下文:CoroutineContext。
CoroutineContext的作用就是用來決定協程運行在哪個線程。
前面分析的buffer時,我們的協程的作用域是runBlocking,即使生產者、消費者在不同的協程,但是它們始終在同一個線程里執行。
而使用了flowOn指定線程,此時生產者、消費者在不同的線程運行協程。
因此,只要弄懂了buffer原理,flowOn原理自然而然就懂了。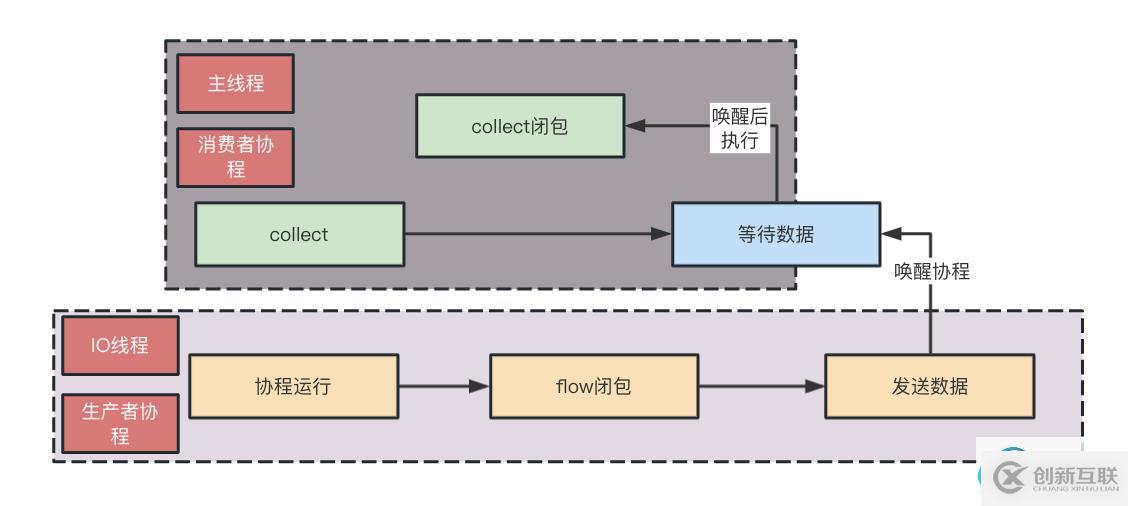
以上為Flow背壓和線程切換的全部內容,下篇將分析Flow的熱流。
本文基于Kotlin 1.5.3,文中完整Demo請點擊
1、Android各種Context的前世今生
2、Android DecorView 必知必會
3、Window/WindowManager 不可不知之事
4、View Measure/Layout/Draw 真明白了
5、Android事件分發全套服務
6、Android invalidate/postInvalidate/requestLayout 徹底厘清
7、Android Window 如何確定大小/onMeasure()多次執行原因
8、Android事件驅動Handler-Message-Looper解析
9、Android 鍵盤一招搞定
10、Android 各種坐標徹底明了
11、Android Activity/Window/View 的background
12、Android Activity創建到View的顯示過
13、Android IPC 系列
14、Android 存儲系列
15、Java 并發系列不再疑惑
16、Java 線程池系列
17、Android Jetpack 前置基礎系列
18、Android Jetpack 易學易懂系列
19、Kotlin 輕松入門系列
20、Kotlin 協程系列全面解讀
你是否還在尋找穩定的海外服務器提供商?創新互聯www.cdcxhl.cn海外機房具備T級流量清洗系統配攻擊溯源,準確流量調度確保服務器高可用性,企業級服務器適合批量采購,新人活動首月15元起,快前往官網查看詳情吧
名稱欄目:KotlinFlow背壓和線程切換竟然如此相似-創新互聯
當前路徑:http://vcdvsql.cn/article42/ceooec.html
成都網站建設公司_創新互聯,為您提供手機網站建設、網頁設計公司、小程序開發、網站內鏈、企業建站、外貿建站
聲明:本網站發布的內容(圖片、視頻和文字)以用戶投稿、用戶轉載內容為主,如果涉及侵權請盡快告知,我們將會在第一時間刪除。文章觀點不代表本網站立場,如需處理請聯系客服。電話:028-86922220;郵箱:631063699@qq.com。內容未經允許不得轉載,或轉載時需注明來源: 創新互聯

- 電子商務網站推廣有哪些方法 2014-04-03
- 高端電子商務網站建設的注意事項 2022-06-21
- 利用電子商務到底能不能賺到錢? 2019-08-31
- 如何設計一個完美的電子商務網站 2022-05-30
- 濮陽網站建設-基于電子商務技術基礎上的企業門戶網站分析 2021-10-23
- 成都電子商務網站建設的核心要點是什么 2022-12-29
- 電子商務網頁視覺設計關注的問題 2016-02-03
- 小型在線零售商如何與大型電子商務品牌進行競爭? 2022-08-12
- 「電子商務」專業是一門什么樣的專業? 2022-12-29
- 成都網站建設:電子商務網站設計七要素 2023-03-22
- 電子商務網站建設從用戶體驗入手 2016-10-28
- 電子商務前途決定你對它的了解認識 2021-05-05