如何使用Python爬取QQ音樂(lè)評(píng)論并制成詞云圖-創(chuàng)新互聯(lián)
這篇文章將為大家詳細(xì)講解有關(guān)如何使用Python爬取QQ音樂(lè)評(píng)論并制成詞云圖,小編覺得挺實(shí)用的,因此分享給大家做個(gè)參考,希望大家閱讀完這篇文章后可以有所收獲。

Python主要應(yīng)用于:1、Web開發(fā);2、數(shù)據(jù)科學(xué)研究;3、網(wǎng)絡(luò)爬蟲;4、嵌入式應(yīng)用開發(fā);5、游戲開發(fā);6、桌面應(yīng)用開發(fā)。
環(huán)境:Ubuntu16.4 python版本:3.6.4 庫(kù):wordcloud
這次我們要講的是爬取QQ音樂(lè)的評(píng)論并制成云詞圖,我們這里拿周杰倫的等你下課來(lái)舉例。
第一步:獲取評(píng)論
我們先打開QQ音樂(lè),搜索周杰倫的《等你下課》,直接拉到底部,發(fā)現(xiàn)有5000多頁(yè)的評(píng)論。

這時(shí)候我們要研究的就是怎樣獲取每頁(yè)的評(píng)論,這時(shí)候我們可以先按下F12,選擇NetWork,我們可以先點(diǎn)擊小紅點(diǎn)清空數(shù)據(jù),然后再點(diǎn)擊一次,開始監(jiān)控,然后點(diǎn)擊下一頁(yè),看每次獲取評(píng)論的時(shí)候訪問(wèn)獲取的是哪幾條數(shù)據(jù)。最后我們就能看到下圖的樣子,我們發(fā)現(xiàn),第一條數(shù)據(jù)就是我們所要找的內(nèi)容,點(diǎn)擊第一條數(shù)據(jù),打開它的response拉到最下面,發(fā)現(xiàn)他的最后一條評(píng)論rootcommentcontent跟我們網(wǎng)頁(yè)中最后一條評(píng)論是一致的,那這時(shí)候已經(jīng)成功了一般了,我們接下來(lái)只需要研究這條數(shù)據(jù)獲取的規(guī)律就可以獲取到所有的評(píng)論了。
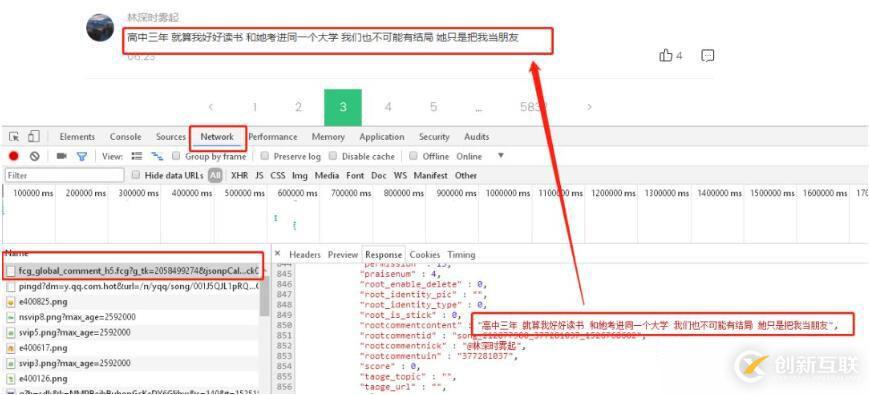
我們先查看這條數(shù)據(jù)的Headers分析下Request URL,通過(guò)點(diǎn)開不同的頁(yè)碼進(jìn)行比較,發(fā)現(xiàn)每次發(fā)出的情況網(wǎng)址大部分內(nèi)容是相同,不同的地方有兩個(gè),就是pagenum跟JsonCallBack,pagenum從英文上很明顯能看出來(lái)就是頁(yè)碼,JsonCallBack又是啥呢?
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h6.fcg?g_tk=2058499274&jsonpCallback=jsoncallback7494258674829413&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=212877900&cmd=8&needmusiccrit=0&pagenum=4&pagesize=25&lasthotcommentid=song_212877900_23831021_1526748144&callback=jsoncallback7494258674829413&domain=qq.com&ct=24&cv=101010

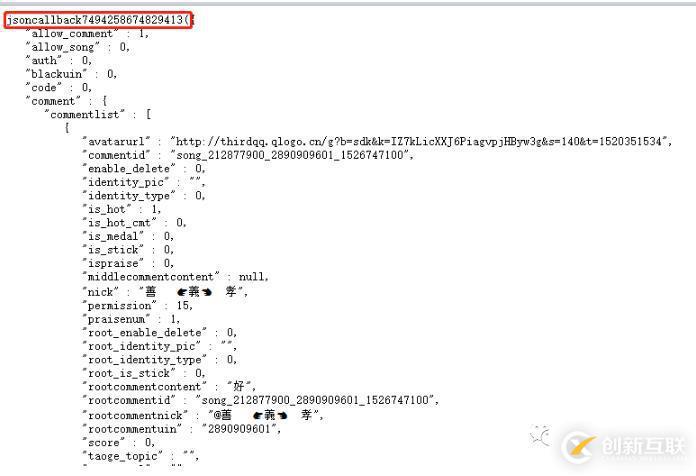
我們不妨將網(wǎng)址直接放在地址欄打開看看是怎樣。我們可以發(fā)現(xiàn)是直接返回一個(gè)不正規(guī)的json格式,為什么說(shuō)是不正規(guī)呢?因?yàn)樗陂_頭多了個(gè)
jsoncallback7494258674829413
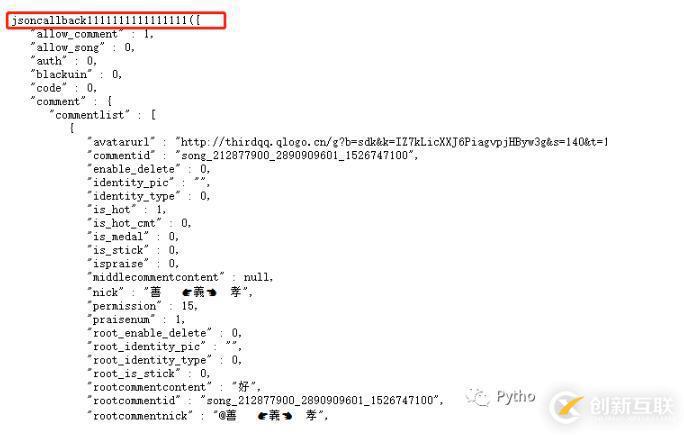
這個(gè)就是我們上面那個(gè)不知道怎么來(lái)的參數(shù),我們嘗試在把這個(gè)數(shù)據(jù)改一下后再打開網(wǎng)址,結(jié)果發(fā)現(xiàn),獲取的json內(nèi)容是沒有變化,唯一變的是開頭jsoncallback1111111111
變成了我們輸入的那個(gè)數(shù)值,所以我們可以猜測(cè)這是一個(gè)隨機(jī)數(shù),無(wú)論你輸入什么,都不會(huì)影響我們要獲取的內(nèi)容。那這樣就好辦多了。
我們就直接放代碼獲取:
import requests
import json
def get_comment():
for i in range(1,7000):
# 打印頁(yè)碼
print(i)
# headers頭部
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Referer': "https://y.qq.com/n/yqq/song/0031TAKo0095np.html"}
# 請(qǐng)求的url
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h6.fcg?g_tk=2058499274&jsonpCallback=jsoncallback06927647062927766&loginUin=2230661779&hostUin=0&format=jsonp&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=212877900&cmd=8&needmusiccrit=0&pagenum=%s&pagesize=25&lasthotcommentid=song_212877900_3035803620_1526783365&callback=jsoncallback06927647062927766&domain=qq.com&ct=24&cv=101010' %i
# 打印當(dāng)前訪問(wèn)的url地址
print (url)
# 將請(qǐng)求得到的頁(yè)面賦值為req
req = requests.get(url,headers=headers,verify=False)
# 對(duì)獲取到的內(nèi)容進(jìn)行utf-8編碼
html = str(req.content,'UTF-8')
# 對(duì)非正規(guī)的json進(jìn)行處理,去掉頭部跟尾部多余的部分
html= html.strip("jsoncallback06927647062927766(")
html = html.replace(")","")
# 去掉兩邊的空格
html = html.strip()
# 將處理后的json轉(zhuǎn)為python的json
data = json.loads(html)
# 獲取json中評(píng)論的部分
list = data['comment']['commentlist']
# 每次都重新定義一個(gè)列表來(lái)存儲(chǔ)每一頁(yè)的評(píng)論
content = []
# 遍歷當(dāng)前頁(yè)的評(píng)論并通過(guò)調(diào)用write()函數(shù)來(lái)保存
for i in list:
# 偶爾也會(huì)有一頁(yè)的評(píng)論獲取不到,這時(shí)候如果報(bào)錯(cuò)了可以直接忽略那一頁(yè),繼續(xù)運(yùn)行
try:
content.append(i['rootcommentcontent'].replace("[em]","").replace("[/em]","").replace("e400",""))
except KeyError:
content = []
break
write(content)
# 將當(dāng)前頁(yè)面的評(píng)論傳遞過(guò)來(lái)
def write(content):
# 打開一個(gè)文件,將列表的內(nèi)容一行一行的存儲(chǔ)下來(lái)
with open('comments.txt', 'a', encoding = 'UTF-8') as f:
for i in range(len(content)):
# 因?yàn)檗D(zhuǎn)為json后\n不胡自動(dòng)換行,所以我們這里將\n給手換行
string = content[i].split("\\n")
for i in string:
# 因?yàn)槌霈F(xiàn)了很多評(píng)論被刪除的情況,所有我們把這句給過(guò)濾掉
i = i.replace("該評(píng)論已經(jīng)被刪除", "")
# 打印每條評(píng)論
print (i)
# 將評(píng)論寫入文本
f.writelines(i)
# 給評(píng)論換行
f.write("\n")
if __name__ == "__main__":
get_comment()寫入文檔的內(nèi)容大概就是這樣:

獲取完之后我們就能用wordcloud來(lái)進(jìn)行詞云圖的制作了:
# -*- coding: utf-8 -*-
import jieba
from wordcloud import WordCloud, STOPWORDS
from os import path
from scipy.misc import imread
# 讀取mask/color圖片
d = path.dirname(__file__)
color_mask = imread("cyx.png")
#將爬到的評(píng)論放在string中
with open('nbzd.txt', 'r', encoding = 'UTF-8') as f:
string = f.read()
word = " ".join(jieba.cut(string))
wordcloud = WordCloud(background_color='white',
mask=color_mask,
max_words=100,
stopwords=STOPWORDS,
font_path='/home/azhao/桌面/素材/simsun.ttc',
max_font_size=100,
random_state=30,
margin=2).generate_from_text(word)
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()最后展示的結(jié)果是這樣的:

關(guān)于“如何使用Python爬取QQ音樂(lè)評(píng)論并制成詞云圖”這篇文章就分享到這里了,希望以上內(nèi)容可以對(duì)大家有一定的幫助,使各位可以學(xué)到更多知識(shí),如果覺得文章不錯(cuò),請(qǐng)把它分享出去讓更多的人看到。
網(wǎng)頁(yè)名稱:如何使用Python爬取QQ音樂(lè)評(píng)論并制成詞云圖-創(chuàng)新互聯(lián)
文章網(wǎng)址:http://vcdvsql.cn/article46/ejieg.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供動(dòng)態(tài)網(wǎng)站、ChatGPT、品牌網(wǎng)站設(shè)計(jì)、域名注冊(cè)、網(wǎng)站收錄、關(guān)鍵詞優(yōu)化
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)
猜你還喜歡下面的內(nèi)容
- 如何使用Nagios監(jiān)控esx、esxi、vcenter-創(chuàng)新互聯(lián)
- 區(qū)塊鏈里的智能合約安全-創(chuàng)新互聯(lián)
- QtCreator設(shè)置代碼自動(dòng)格式化-創(chuàng)新互聯(lián)
- react中的refetch如何用-創(chuàng)新互聯(lián)
- 小程序中Promise進(jìn)行異步流程處理的示例分析-創(chuàng)新互聯(lián)
- VC中如何實(shí)現(xiàn)文字豎排效果-創(chuàng)新互聯(lián)
- microcosm(SpringBoot工具包)-創(chuàng)新互聯(lián)

- 廣州鞋業(yè)網(wǎng)網(wǎng)是鞋行業(yè)專業(yè)電子商務(wù)門戶網(wǎng)站 2021-08-21
- 10個(gè)電子商務(wù)網(wǎng)站模板類型 2015-01-09
- 電子商務(wù)網(wǎng)站設(shè)計(jì)需注意什么? 2015-02-06
- ERP管理系統(tǒng)助力企業(yè)電子商務(wù),核心模塊如何操作? 2022-03-19
- 佛山網(wǎng)站建設(shè)-強(qiáng)化水果電子商務(wù)網(wǎng)站的先入優(yōu)勢(shì) 2021-08-16
- 關(guān)于“電子商務(wù)網(wǎng)站的營(yíng)銷方向與經(jīng)營(yíng)思路” 2021-07-07
- 電子商務(wù)網(wǎng)站制作要三思而行 2021-12-26
- 旅游電子商務(wù)網(wǎng)站的價(jià)值鏈 2021-10-02
- 網(wǎng)絡(luò)營(yíng)銷對(duì)電子商務(wù)的推動(dòng)性 2016-01-07
- 做電子商務(wù),需要注冊(cè)這幾種種類的商標(biāo) 2021-02-17
- 電子商務(wù)網(wǎng)站建設(shè)確定網(wǎng)站建設(shè)目的是關(guān)鍵 2023-01-12
- 如何建立一個(gè)電商網(wǎng)站?如何建立電子商務(wù)網(wǎng)站? 2022-05-27