MySQL全文索引如何解決like模糊匹配查詢慢的問(wèn)題
這篇文章主要講解了“MySQL全文索引如何解決like模糊匹配查詢慢的問(wèn)題”,文中的講解內(nèi)容簡(jiǎn)單清晰,易于學(xué)習(xí)與理解,下面請(qǐng)大家跟著小編的思路慢慢深入,一起來(lái)研究和學(xué)習(xí)“MySQL全文索引如何解決like模糊匹配查詢慢的問(wèn)題”吧!
創(chuàng)新互聯(lián)成立于2013年,是專業(yè)互聯(lián)網(wǎng)技術(shù)服務(wù)公司,擁有項(xiàng)目成都網(wǎng)站建設(shè)、做網(wǎng)站網(wǎng)站策劃,項(xiàng)目實(shí)施與項(xiàng)目整合能力。我們以讓每一個(gè)夢(mèng)想脫穎而出為使命,1280元靖邊做網(wǎng)站,已為上家服務(wù),為靖邊各地企業(yè)和個(gè)人服務(wù),聯(lián)系電話:18982081108
需求
需要模糊匹配查詢一個(gè)單詞
select * from t_phrase where LOCATE('昌',phrase) = 0;
select * from t_chinese_phrase where instr(phrase,'昌') > 0;
select * from t_chinese_phrase where phrase like '%昌%'
explain一下看看執(zhí)行計(jì)劃
.jpg)
由explain的結(jié)果可知,雖然我們給phrase建了索引,但是查詢的時(shí)候,索引是失效的。
原因: mysql的索引是B+樹結(jié)構(gòu),InnoDB在模糊查詢數(shù)據(jù)時(shí)使用 "%xx" 會(huì)導(dǎo)致索引失效(此處就不展開講了)
從查詢時(shí)長(zhǎng)上來(lái)看,花費(fèi)時(shí)間:90ms
目前數(shù)據(jù)量:93230(9.3W)已經(jīng)需要90ms,這個(gè)時(shí)間不太能接受,假如數(shù)據(jù)量增加,這個(gè)時(shí)間會(huì)不斷增長(zhǎng)。
解決方案:
數(shù)據(jù)量不大的情況下,使用mysql的全文索引;
數(shù)據(jù)量比較大或者mysql的全文索引不達(dá)預(yù)期的情況下,可以考慮使用ES
下面主要是MySQL的全文索引相關(guān).
全文索引介紹
1、發(fā)展歷史
舊版的MySQL的全文索引只能用在MyISAM存儲(chǔ)引擎的char、varchar和text的字段上。
MySQL5.6.24上InnoDB引擎也加入了全文索引。
2、全文索引
全文檢索(Full-Text Search)是將存儲(chǔ)于數(shù)據(jù)庫(kù)中的整本書或整篇文章中的任意內(nèi)容信息查找出來(lái)的技術(shù)。它可以根據(jù)需要獲得全文中有關(guān)章、節(jié)、段、詞等信息,也可以進(jìn)行各種統(tǒng)計(jì)和分析
3、創(chuàng)建全文索引
若需對(duì)大量數(shù)據(jù)設(shè)置全文索引,建議先添加數(shù)據(jù)再創(chuàng)建索引。
1、創(chuàng)建表時(shí)創(chuàng)建全文索引
2、為已有表添加全文索引create table 表名(
字段名1,
字段名2,
字段名3,
字段名4,
FULLTEXT full_index_name (字段名)
)ENGINE=InnoDB;
create fulltext index 索引名稱 on 表名(字段名);
eg:
create table t_word
(
id int unsigned auto_increment comment '自增id' primary key,
uid char(32) not null comment '32位唯一id',
word varchar(256) null comment '英文單詞',
translate varchar(256) null
);
create fulltext index full_idx_translate
on t_word (translate);
create fulltext index full_idx_word
on t_word (word);
INSERT INTO t_word (id, uid, word, translate) VALUES (1, '9d592499c65648b0a9519206688ef3f9', 'lion', '獅子');
INSERT INTO t_word (id, uid, word, translate) VALUES (2, 'ce26ac4239514bc6af481bcb1d9b67df', 'panda', '熊貓');
INSERT INTO t_word (id, uid, word, translate) VALUES (3, 'a7d6042853c44904b68275daafb44702', 'tiger', '老虎');
INSERT INTO t_word (id, uid, word, translate) VALUES (4, 'f13bd0a8ecea44fc9ade1625eeb4cc3c', 'goat', '山羊');
INSERT INTO t_word (id, uid, word, translate) VALUES (5, '27d5cbfc93a046388d712085e567474f', 'sheep', '綿羊');
INSERT INTO t_word (id, uid, word, translate) VALUES (6, 'ed35df138cf348aa937781be8ee21cbf', 'lamb', '羊羔');
INSERT INTO t_word (id, uid, word, translate) VALUES (7, 'fba5861d9527440990276e999f47ef8f', 'buffalo', '水牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (8, '3a72e76f210841b1939fff0d3d721375', 'bull', '公牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (9, '272e0b28ea7a48248a86f17533bf9943', 'cow', '母牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (10, '47127adface54e418e4c1b9980af6d16', 'calf', '小牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (11, '10592499c65648b0a9519206688ef3f9', 'little lion', '小獅子');
INSERT INTO t_word (id, uid, word, translate) VALUES (12, '1bf095110b634a01bee5b31c5ee7ee0c', 'little cow', '母牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (13, '4813e588cde54c30bd65bfdbb243ad1f', 'little calf', '小小牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (14, '5e377e281ad344048b6938a638b78ccb', 'little bull', '小公牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (15, '2855ad0da2964c7682c178eb8271f13d', 'little buffalo', '小水牛');
INSERT INTO t_word (id, uid, word, translate) VALUES (16, '72f24c9a77644d57a36f3bdf2b8116b0', 'little lamb', '小羊羔');
INSERT INTO t_word (id, uid, word, translate) VALUES (17, '2d592499c65648b0a9519206688ef3f9', 'I''m a big lion', '我是一只大獅子');
3、刪除全文索引
alter table 表名 drop index 索引名;
4、全文索引使用
語(yǔ)法
MATCH(col1,col2,...) AGAINST(expr[search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
4.1 IN NATURAL LANGUAGE MODE
自然語(yǔ)言模式是MySQL 默認(rèn) 的全文檢索模式。自然語(yǔ)言模式不能使用操作符,不能指定關(guān)鍵詞必須出現(xiàn)或者必須不能出現(xiàn)等復(fù)雜查詢。
// 默認(rèn)是使用 in natural language mode
select * from t_word where match(word) against ('lion');
// 或者 顯示寫
select * from t_word where match(word) against ('lion' in natural language mode);
結(jié)果如下:
.jpg)
4.2 IN BOOLEAN MODE
BOOLEAN模式可以使用操作符,可以支持指定關(guān)鍵詞必須出現(xiàn)或者必須不能出現(xiàn)或者關(guān)鍵詞的權(quán)重高還是低等復(fù)雜查詢。推薦使用boolean模式
| 操作者 | 描述 |
|---|---|
| 為空 | 默認(rèn),包含該詞 |
| + | 包括,這個(gè)詞必須存在。 |
| - | 排除,詞不得出現(xiàn)。 |
| >(大于號(hào)) | 包括,并提高排名值,查詢的結(jié)果會(huì)靠前 |
| < | 包括,并降低排名值,查詢的結(jié)果會(huì)靠后 |
| () | 將單詞分組為子表達(dá)式(允許將它們作為一組包括在內(nèi),排除在外,排名等等)。 |
| ? | 否定單詞的排名值。 |
| * | 通配符在這個(gè)詞的結(jié)尾。 |
| “” | 定義短語(yǔ)(與單個(gè)單詞列表相對(duì),整個(gè)短語(yǔ)匹配以包含或排除)。 |
示例:
// 默認(rèn)是使用 in natural language mode
select * from t_word where match(word) against ('lion');
// 或者 顯示寫
select * from t_word where match(word) against ('lion' in natural language mode);
.jpg)
// 排除包含lion記錄、查詢出包含cow或者little的記錄,提升包含calf單詞的排名,降低包含cow記錄的排名,查詢出以go開頭的記錄
select * from t_word where match(word) against ('-lion cow little >calf <cow go*' in boolean mode) ;
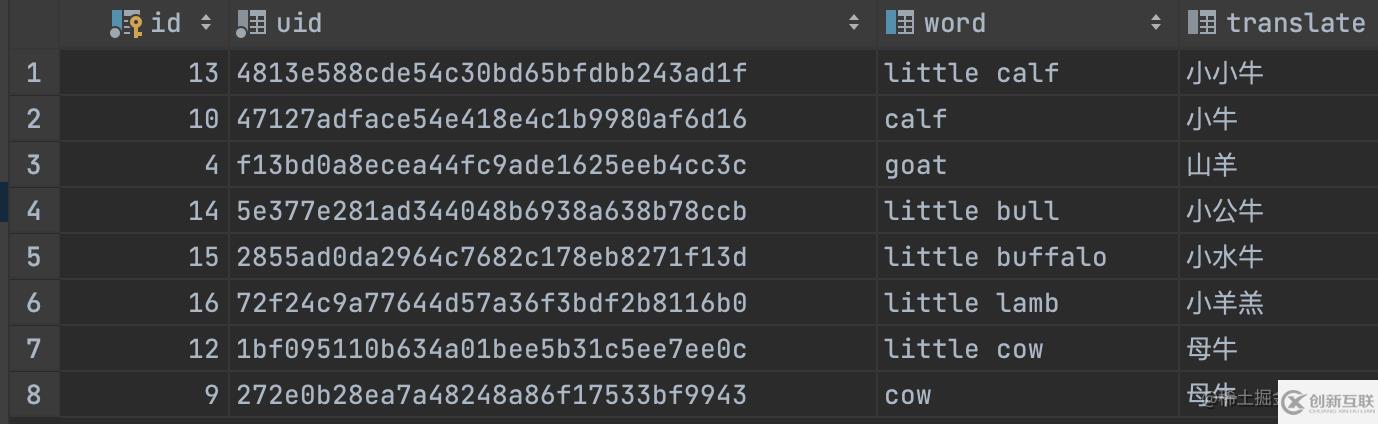
好像問(wèn)題都解決了, 但是問(wèn)題才剛開始
回到最開始的需求,我想模糊搜索
select * from t_word where match(word) against('lio' in boolean mode);
預(yù)期值:把包含lion的都查詢出來(lái) 實(shí)際結(jié)果:啥都沒(méi)有。

全匹配查詢的時(shí)候能查詢出來(lái)
select * from t_word where match(translate) against('小水牛' in boolean mode);

只查詢部分查詢不出來(lái)。如:下面只查詢 "小水" 或者"水牛" 都沒(méi)有數(shù)據(jù)
select * from t_word where match(translate) against('小水' in boolean mode);

奇怪了,這咋沒(méi)出來(lái)呢?
全文索引默認(rèn)是只按照
空格進(jìn)行分詞的,所以當(dāng)我完整的單個(gè)單詞去查詢的時(shí)候是能查出來(lái)的。但是使用部分單詞去查詢或者使用部分中文去查詢時(shí),是查詢不出來(lái)數(shù)據(jù)的,像中文需要使用中文分詞器進(jìn)行分詞。
中文分詞與全文索引
InnoDB默認(rèn)的全文索引parser非常合適于Latin,因?yàn)長(zhǎng)atin是通過(guò)空格來(lái)分詞的。但對(duì)于像中文,日文和韓文來(lái)說(shuō),沒(méi)有這樣的分隔符。一個(gè)詞可以由多個(gè)字來(lái)組成,所以我們需要用不同的方式來(lái)處理。在MySQL 5.7.6中我們能使用一個(gè)新的全文索引插件來(lái)處理它們:N-gram parser。
什么是N-gram?
在全文索引中,n-gram就是一段文字里面連續(xù)的n個(gè)字的序列。例如,用n-gram來(lái)對(duì)“齒輪傳動(dòng)”來(lái)進(jìn)行分詞,得到的結(jié)果如下:
N=1 : '齒', '輪', '傳', '動(dòng)';
N=2 : '齒輪', '輪傳', '傳動(dòng)';
N=3 : '齒輪傳', '輪傳動(dòng)';
N=4 : '齒輪傳動(dòng)';
這個(gè)上面這個(gè)N是怎么去配置的?
查一下目前的值
show variables like '%token%';
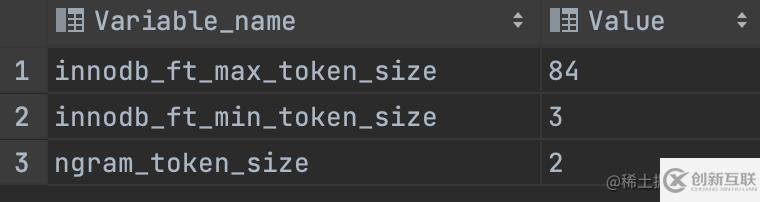
參數(shù)解析:
innodb_ft_min_token_size
默認(rèn)3,表示最小3個(gè)字符作為一個(gè)關(guān)鍵詞,增大該值可減少全文索引的大小
innodb_ft_max_token_size
默認(rèn)84,表示最大84個(gè)字符作為一個(gè)關(guān)鍵詞,限制該值可減少全文索引的大小
ngram_token_size
默認(rèn)2,表示2個(gè)字符作為內(nèi)置分詞解析器的一個(gè)關(guān)鍵詞,合法取值范圍是1-10,如對(duì)“abcd”建立全文索引,關(guān)鍵詞為’ab’,‘bc’,‘cd’ 當(dāng)使用ngram分詞解析器時(shí),innodb_ft_min_token_size和innodb_ft_max_token_size 無(wú)效
修改方式
方式1: 在my.cnf中修改/添加參數(shù)
[mysqld]ngram_token_size = 1
方式2: 修改啟動(dòng)參數(shù)
mysqld --ngram_token_size=1復(fù)制代碼
參數(shù)均不可動(dòng)態(tài)修改,修改后需重啟MySQL服務(wù),并重新建立全文索引
實(shí)際使用
初始化測(cè)試數(shù)據(jù)
這里只提供部分測(cè)試數(shù)據(jù),我下面sql使用全量數(shù)據(jù),數(shù)據(jù)對(duì)不上
create table t_chinese_phrase
(
id int unsigned auto_increment comment 'id'
primary key,
phrase varchar(32) not null comment '詞組'
)
collate = utf8mb4_general_ci;
INSERT INTO t_chinese_phrase (id, phrase) VALUES (278911, '阿昌族');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (279253, '八一南昌起義');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (282316, '昌明');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (282317, '昌盛');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (282318, '昌言');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (286534, '東昌紙');
INSERT INTO t_chinese_phrase (id, phrase) VALUES (291525, '海昌藍(lán)');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (346682, '繁榮昌盛');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (282317, '昌盛');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (287738, '繁盛');
INSERT INTO test.t_chinese_phrase (id, phrase) VALUES (287736, '繁榮');
添加索引
mysql 全文索引使用倒排索引為 full inverted index
結(jié)構(gòu):{單詞,(單詞所在文檔的ID,單詞在具體文件中的位置)}
添加索引:
alter table t_chinese_phrase add fulltext ful_phrase (phrase) with parser ngram;
建完索引,我們可以通過(guò)查詢INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE和INFORMATION_SCHEMA.INNODB_FT_TABLE_TABLE來(lái)查詢哪些詞在全文索引里面。這是一個(gè)非常有用的調(diào)試工具。如果我們發(fā)現(xiàn)一個(gè)包含某個(gè)詞的文檔,沒(méi)有如我們所期望的那樣出現(xiàn)在查詢結(jié)果中,那么這個(gè)詞可能是因?yàn)槟承┰虿辉谌乃饕锩妗1热纾衧topword,或者它的大小小于ngram_token_size等等。這個(gè)時(shí)候我們就可以通過(guò)查詢這兩個(gè)表來(lái)確認(rèn)。下面是一個(gè)簡(jiǎn)單的例子:
# test: 庫(kù)名 t_chinese_phrase: 表名字
SET GLOBAL innodb_ft_aux_table="test/t_chinese_phrase";
# 查詢分詞情況
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;
# 查詢分詞情況
select * from information_schema.innodb_ft_index_table;
查詢結(jié)果如下:
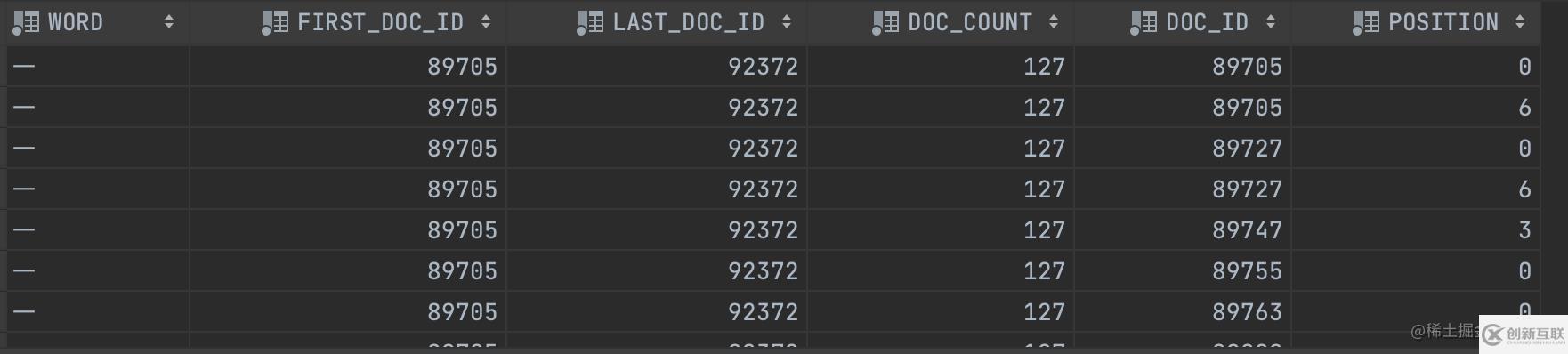
因?yàn)槲覀兩厦嬖O(shè)置了分詞數(shù)是1,所以,可以看到都是按照一個(gè)詞進(jìn)行分詞的。
字段解析:
FIRST_DOC_ID :word第一次出現(xiàn)的文檔ID
LAST_DOC_ID : word最后一次出現(xiàn)的文檔ID
DOC_COUNT :含有word的文檔個(gè)數(shù)
DOC_ID :當(dāng)前文檔ID
POSITION : word 當(dāng)在前文檔ID的位置
查詢
1、使用自然語(yǔ)言模式 NATURAL LANGUAGE MODE 查詢
在自然語(yǔ)言模式(NATURAL LANGUAGE MODE)下,文本的查詢被轉(zhuǎn)換為n-gram分詞查詢的
并集。
例如,當(dāng)ngram_token_size = 1 時(shí),(‘繁榮昌盛’)轉(zhuǎn)換為(‘繁 榮 昌 盛’)。下面一個(gè)例子:
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('繁榮昌盛' in natural language mode) ;
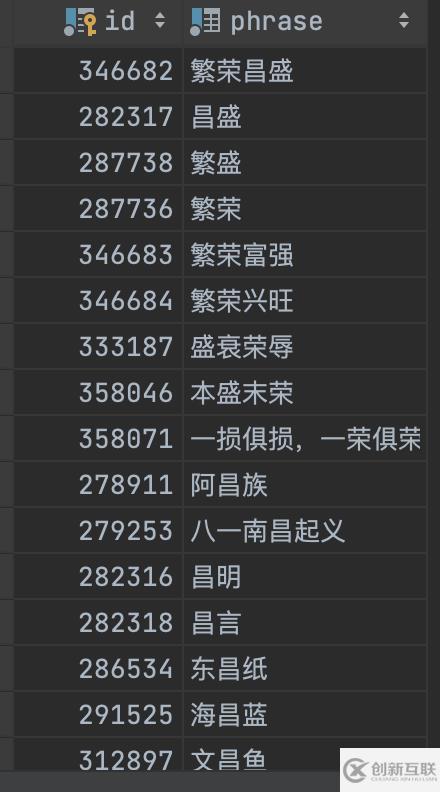
2、使用布爾模式(BOOLEAN MODE)查詢
布爾模式(BOOLEAN MODE)文本查詢被轉(zhuǎn)化為n-gram分詞的
短語(yǔ)查詢
例如,當(dāng)ngram_token_size = 1 時(shí),(‘繁榮昌盛’)轉(zhuǎn)換為(‘”繁榮昌盛“’)。下面一個(gè)例子:
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('繁榮昌盛' in boolean mode) ;
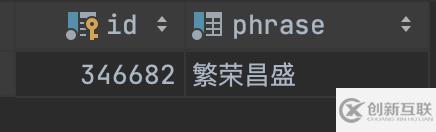
實(shí)際使用
回到我們最開始的查詢需求,看看實(shí)際的效果
查詢包含了“昌”的數(shù)據(jù)
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('昌' IN boolean MODE) ;
SELECT * FROM t_chinese_phrase WHERE MATCH (phrase) AGAINST ('昌' ) order by id asc;
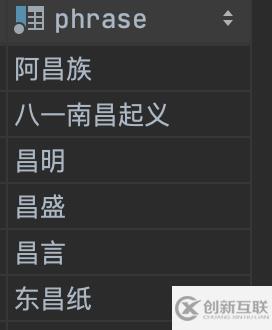
可以看到結(jié)果:目前“昌”在任意位置都能被查詢到。
查詢執(zhí)行計(jì)劃如下:

耗時(shí)31ms(不走索引是90ms),耗時(shí)差不多是之前的1/3。
注意點(diǎn)
1、自然語(yǔ)言全文索引創(chuàng)建索引時(shí)的字段需與查詢的字段保持一致,即MATCH里的字段必須和FULLTEXT里的一模一樣;
2、自然語(yǔ)言檢索時(shí),檢索的關(guān)鍵字在所有數(shù)據(jù)中不能超過(guò)50%(即常見(jiàn)詞),則不會(huì)檢索出結(jié)果。可以通過(guò)布爾檢索查詢;
3、在mysql的stopword中的單詞檢索不出結(jié)果。可通過(guò)
登錄后復(fù)制SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD
查詢所有的stopword。遇到這種情況,有兩種解決辦法:
(1)stopword一般是mysql自建的,但可以通過(guò)設(shè)置ft_stopword_file變量為自定義文件,從而自己設(shè)置stopword,設(shè)置完成后需要重新創(chuàng)建索引。但不建議使用這種方法;
(2)使用布爾索引查詢。
4、小于最短長(zhǎng)度和大于最長(zhǎng)長(zhǎng)度的關(guān)鍵詞無(wú)法查出結(jié)果。可以通過(guò)設(shè)置對(duì)應(yīng)的變量來(lái)改變長(zhǎng)度限制,修改后需要重新創(chuàng)建索引。
myisam引擎下對(duì)應(yīng)的變量名為ft_min_word_len和ft_max_word_len
innodb引擎下對(duì)應(yīng)的變量名為innodb_ft_min_token_size和innodb_ft_max_token_size
5、MySQL5.7.6之前的版本不支持中文,需使用第三方插件
6、全文索引只能在 InnoDB(MySQL 5.6以后) 或 MyISAM 的表上使用,并且只能用于創(chuàng)建 char,varchar,text 類型的列。
感謝各位的閱讀,以上就是“MySQL全文索引如何解決like模糊匹配查詢慢的問(wèn)題”的內(nèi)容了,經(jīng)過(guò)本文的學(xué)習(xí)后,相信大家對(duì)MySQL全文索引如何解決like模糊匹配查詢慢的問(wèn)題這一問(wèn)題有了更深刻的體會(huì),具體使用情況還需要大家實(shí)踐驗(yàn)證。這里是創(chuàng)新互聯(lián),小編將為大家推送更多相關(guān)知識(shí)點(diǎn)的文章,歡迎關(guān)注!
網(wǎng)頁(yè)名稱:MySQL全文索引如何解決like模糊匹配查詢慢的問(wèn)題
URL標(biāo)題:http://vcdvsql.cn/article6/iijpig.html
成都網(wǎng)站建設(shè)公司_創(chuàng)新互聯(lián),為您提供外貿(mào)建站、做網(wǎng)站、電子商務(wù)、域名注冊(cè)、網(wǎng)站導(dǎo)航、營(yíng)銷型網(wǎng)站建設(shè)
聲明:本網(wǎng)站發(fā)布的內(nèi)容(圖片、視頻和文字)以用戶投稿、用戶轉(zhuǎn)載內(nèi)容為主,如果涉及侵權(quán)請(qǐng)盡快告知,我們將會(huì)在第一時(shí)間刪除。文章觀點(diǎn)不代表本網(wǎng)站立場(chǎng),如需處理請(qǐng)聯(lián)系客服。電話:028-86922220;郵箱:631063699@qq.com。內(nèi)容未經(jīng)允許不得轉(zhuǎn)載,或轉(zhuǎn)載時(shí)需注明來(lái)源: 創(chuàng)新互聯(lián)

- 企業(yè)網(wǎng)站制作首頁(yè)要注重哪些問(wèn)題? 2023-04-18
- 深圳企業(yè)網(wǎng)站制作的現(xiàn)狀分析? 2022-06-27
- 企業(yè)網(wǎng)站制作怎樣區(qū)分靜態(tài)和動(dòng)態(tài)網(wǎng)頁(yè)呢? 2013-05-16
- 問(wèn)企業(yè)網(wǎng)站制作的意義有哪些 2021-10-13
- 企業(yè)網(wǎng)站制作存在的缺點(diǎn)有哪些 2023-02-04
- 企業(yè)網(wǎng)站制作需要注意的事項(xiàng) 2021-08-18
- 深圳中小企業(yè)網(wǎng)站制作,中小企業(yè)網(wǎng)站制作有哪些容易忽略的問(wèn)題? 2021-12-23
- 外貿(mào)企業(yè)網(wǎng)站制作公司 2016-10-05
- 影響企業(yè)網(wǎng)站制作質(zhì)量的主要因素 2021-12-17
- 企業(yè)網(wǎng)站制作到底有什么意義和目的 2021-09-21
- 企業(yè)網(wǎng)站制作的重要性,老板們,該行動(dòng)啦 2021-10-24
- 企業(yè)網(wǎng)站制作前需策劃的網(wǎng)站后臺(tái)功能 2021-06-15